

Le Scraping web est une technique automatisée qui permet d’extraire et de collecter de grandes quantités de données à partir de sites web, à l’aide de différents outils ou programmes. Il est couramment utilisé pour extraire des tableaux HTML, qui contiennent des données organisées en colonnes et en lignes. Une fois collectées, ces données peuvent être analysées ou utilisées à des fins de recherche. Pour un guide plus détaillé, consultez cet article surle Scraping web HTML.
Ce tutoriel vous apprendra comment extraire des tableaux HTML à partir de sites web à l’aide de Python.
Prérequis
Avant de commencer ce tutoriel, vous devezinstaller Python version 3.8 ou plus récenteetcréer un environnement virtuel. Si vous débutez dans le Scraping web avec Python,cet articleest un bon point de départ.
Une fois l’environnement créé, installez les paquets Python suivants :
- Requests
- Beautiful Soup
- pandas
Vous pouvez installer les paquets à l’aide de la commande suivante :
pip install requests beautifulsoup4 pandas
Comprendre la structure d’une page Web
Dans ce tutoriel, vous allez extraire des données dusite Web Worldometer. Cette page Web contient des données actualisées sur les pays du monde entier, y compris leurs chiffres de population respectifs pour 2024 :
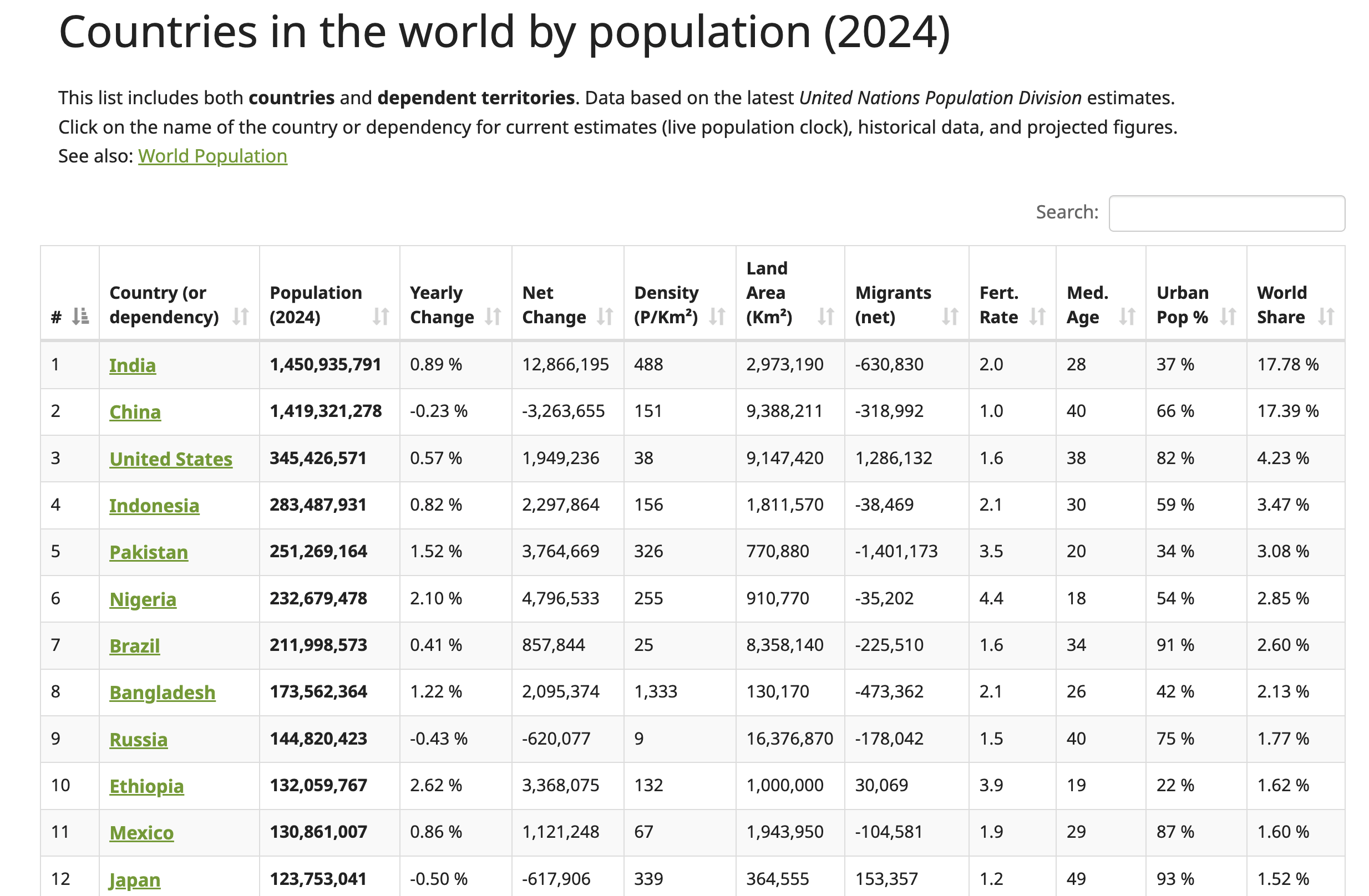
Pour localiser la structure HTML du tableau, cliquez avec le bouton droit de la souris sur le tableau (illustré dans la capture d’écran précédente) et sélectionnez Inspecter. Cette action ouvre le panneau Outils de développement, qui affiche le code HTML de la page, avec l’élément sélectionné mis en surbrillance :
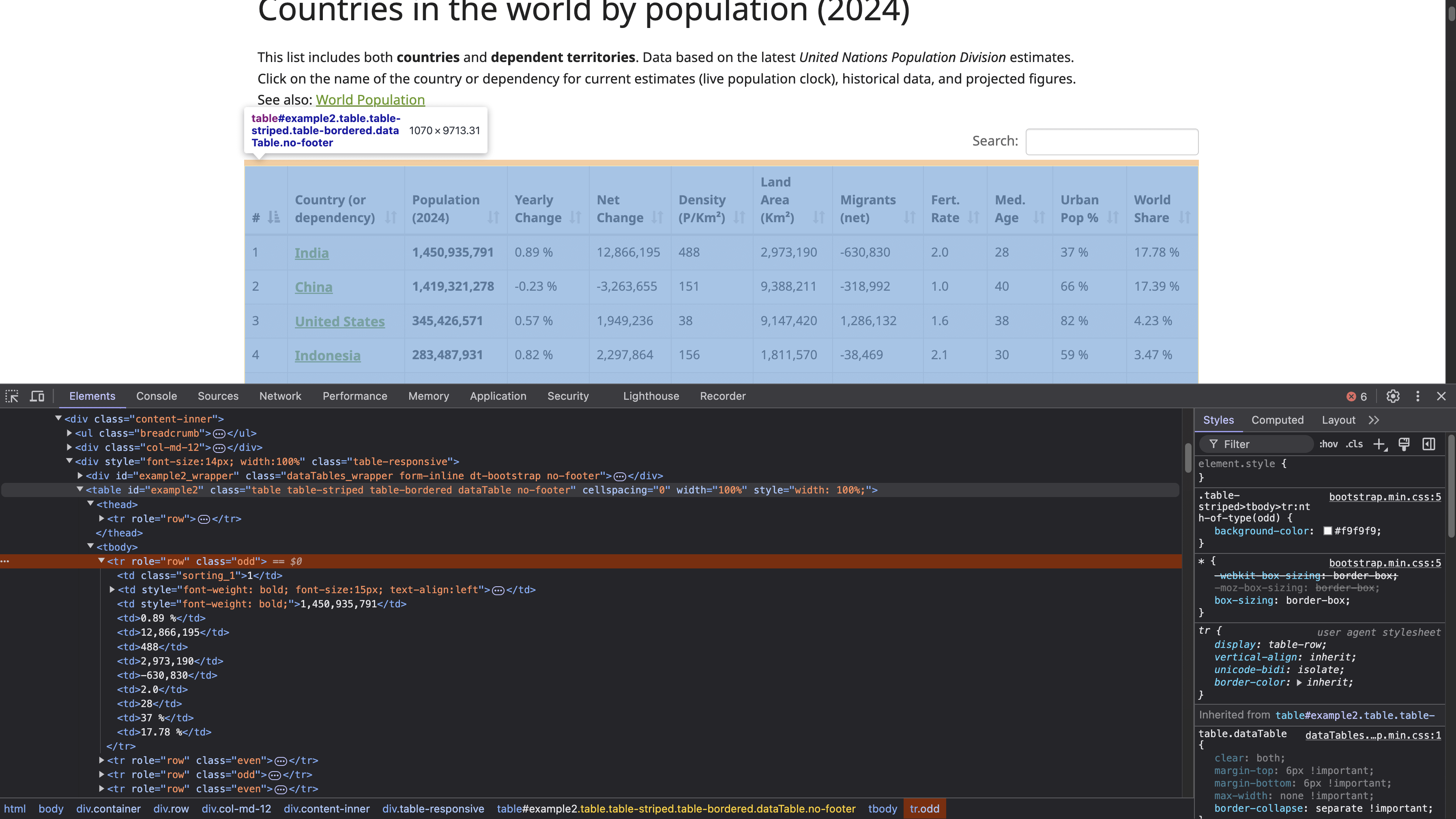
La balise <table> avec l’ID example2 définit le début de la structure du tableau. Ce tableau comporte des en-têtes avec les balises <th>, et les lignes sont définies par les balises <tr>, chaque <tr> représentant une nouvelle ligne horizontale dans le tableau. À l’intérieur de chaque <tr>, la balise <td> crée des cellules individuelles dans cette ligne, contenant les données affichées dans chaque cellule.
Remarque : avant de procéder à tout scraping, il est important que vous consultiez et respectiez la politique de confidentialité et les conditions d’utilisation du site web afin de vous assurer que vous respectez toutes les restrictions relatives à l’utilisation des données et à l’accès automatisé.
Envoyer une requête HTTP pour accéder à la page web
Pour envoyer une requête HTTP et accéder à la page web, créez un fichier Python (par exemple html_table_scraper.py) et importez les paquets requests, BeautifulSoup et pandas:
# importer les paquets
import requests
from bs4 import BeautifulSoup
import pandas as pd
Ensuite, définissez l’URL de la page Web que vous souhaitez extraire et envoyez une requête GET à cette page Web à l’aide de https://www.worldometers.info/world-population/population-by-country/:
# Envoyer une requête au site web pour obtenir le contenu de la page
url = 'https://www.worldometers.info/world-population/population-by-country/'
Pour vérifier si la réponse est réussie ou non, envoyez une requête à l’aide de la méthode get() de Requests :
# Obtenir le contenu de l'URL
response = requests.get(url)
# Vérifier le statut de la réponse.
if response.status_code == 200:
print("La requête a abouti !")
else:
print(f"Erreur : {response.status_code} - {response.text}")
Ce code envoie une requête GET à une URL spécifiée, puis vérifie le statut de la réponse. Une réponse 200 indique que la requête a abouti.
Utilisez la commande suivante pour exécuter le script Python dans votre terminal :
python html_table_scraper.py
Votre résultat devrait ressembler à ceci :
La requête a abouti !
La requête GET ayant abouti, vous disposez désormais du contenu HTML de l’ensemble de la page Web, y compris le tableau HTML.
Analysez le HTML à l’aide de Beautiful Soup
Beautiful Soup peut traiter le contenu HTML mal formaté ou corrompu, ce qui est courant lors du scraping web. Ici, vous utilisez le package Beautiful Soup pour effectuer les opérations suivantes :
- Effectuer l’analyse du contenu HTML de la page Web pour trouver le tableau qui présente les données démographiques.
- Collecter les en-têtes du tableau.
- Collecter toutes les données présentées dans les lignes du tableau.
Pour analyser le contenu que vous avez collecté, créez un objet Beautiful Soup :
# Analyser le contenu HTML à l'aide de BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
Ensuite, localisez l’élément de tableau dans le HTML avec l’attribut id « example2 ». Ce tableau contient la population des pays en 2024 :
# Trouver le tableau contenant les données démographiques
table = soup.find('table', attrs={'id': 'example2'})
Collecter les en-têtes du tableau
Le tableau comporte un en-tête situé dans les balises HTML <thead> et <th>. Utilisez la méthode find() du package Beautiful Soup pour extraire les données de la balise <thead> et la méthode find_all() pour collecter tous les en-têtes :
# Collecter les en-têtes du tableau
headers = []
# Localiser la ligne d'en-tête dans la balise <thead>
header_row = table.find('thead').find_all('th')
for th in header_row:
# Ajouter le texte de l'en-tête à la liste des en-têtes
headers.append(th.text.strip())
Ce code crée une liste Python vide appelée headers, localise la balise HTML <thead> pour trouver tous les en-têtes dans les balises HTML <th>, puis ajoute chaque en-tête collecté à la liste des en-têtes.
Collecter les données des lignes du tableau
Pour collecter les données de chaque ligne, créez une liste Python vide appelée data afin de stocker les données extraites :
# Initialiser une liste vide pour stocker nos données
data = []
Ensuite, extrayez les données de chaque ligne du tableau à l’aide de la méthode find_all() et ajoutez-les à la liste Python :
# Parcourir chaque ligne du tableau (en ignorant la ligne d'en-tête)
for tr in table.find_all('tr')[1:]:
# Créer une liste des données de la ligne actuelle
row = []
# Rechercher toutes les cellules de données dans la ligne actuelle
for td in tr.find_all('td'):
# Obtenir le contenu textuel de la cellule et supprimer les espaces supplémentaires
cell_data = td.text.strip()
# Ajouter les données de cellule nettoyées à la liste des lignes
row.append(cell_data)
# Après avoir récupéré toutes les cellules de cette ligne, ajoutez la ligne à notre liste de données
data.append(row)
# Convertissez les données collectées en un DataFrame pandas pour faciliter leur traitement
df = pd.DataFrame(data, columns=headers)
# Affichez le DataFrame pour voir le nombre de lignes et de colonnes
print(df.shape)
Ce code parcourt toutes les balises HTML <tr> trouvées dans le tableau, en commençant par la deuxième ligne (en ignorant la ligne d’en-tête). Pour chaque ligne (<tr>), une liste vide row est créée pour stocker les données des cellules de cette ligne. À l’intérieur de la ligne, le code trouve toutes les balises HTML <td> à l’aide de la méthode find_all(), qui représentent les cellules de données individuelles de la ligne.
Pour chaque balise HTML <td>, le code extrait le contenu textuel à l’aide de l'attribut .textet applique la méthode .strip() pour supprimer tout espace blanc en début ou en fin de texte. Les données de cellule nettoyées sont ajoutées à la liste des lignes. Après avoir traité toutes les cellules de la ligne actuelle, la ligne entière est ajoutée à la liste de données. Enfin, vous convertissez les données collectées en un DataFrame pandas avec les noms de colonnes définis par la liste des en-têtes, puis vous affichez la forme des données.
Le script Python complet devrait ressembler à ceci :
# Importer les paquets
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Envoyer une requête au site web pour obtenir le contenu de la page
url = 'https://www.worldometers.info/world-population/population-by-country/'
# Obtenir le contenu de l'URL
response = requests.get(url)
# Vérifier si la requête a abouti
if response.status_code == 200:
# Analyser le contenu HTML à l'aide de Beautiful Soup
soup = BeautifulSoup(response.content, 'html.parser')
# Trouver le tableau contenant les données démographiques à l'aide de son ID
table = soup.find('table', attrs={'id': 'example2'})
# Collecter les en-têtes du tableau
headers = []
# Localiser la ligne d'en-tête dans la balise HTML <thead>
header_row = table.find('thead').find_all('th')
for th in header_row:
# Ajouter le texte de l'en-tête à la liste des en-têtes
headers.append(th.text.strip())
# Initialiser une liste vide pour stocker nos données
data = []
# Parcourir chaque ligne du tableau (en ignorant la ligne d'en-tête)
for tr in table.find_all('tr')[1:]:
# Créer une liste des données de la ligne actuelle
row = []
# Rechercher toutes les cellules de données dans la ligne actuelle
for td in tr.find_all('td'):
# Obtenir le contenu textuel de la cellule et supprimer les espaces supplémentaires
cell_data = td.text.strip()
# Ajouter les données de cellule nettoyées à la liste des lignes
row.append(cell_data)
# Après avoir obtenu toutes les cellules de cette ligne, ajouter la ligne à notre liste de données
data.append(row)
# Convertir les données collectées en un DataFrame pandas pour faciliter leur traitement
df = pd.DataFrame(data, columns=headers)
# Imprimer le DataFrame pour voir les données collectées
print(df.shape)
else:
print(f"Erreur : {response.status_code} - {response.text}")
Utilisez la commande suivante pour exécuter le script Python dans votre terminal :
python html_table_scraper.py
Votre résultat devrait ressembler à ceci :
(234,12)
À ce stade, vous avez extrait avec succès 234 lignes et 12 colonnes du tableau HTML.
Ensuite, utilisez la méthode head() de pandas et print() pour afficher les dix premières lignes des données extraites :
print(df.head(10))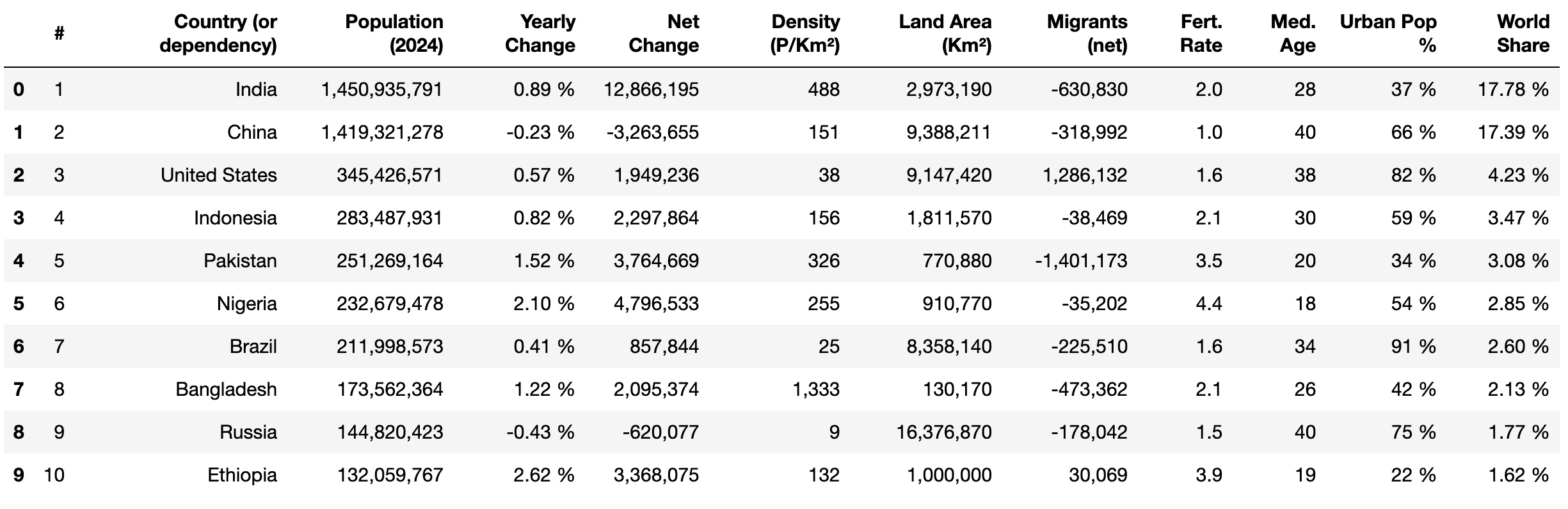
Nettoyer et structurer les données
Lorsque vous extrayez des données d’un tableau HTML, il est important de les nettoyer afin de garantir leur cohérence, leur exactitude et leur bonne utilisation pour l’analyse. Les données brutes extraites d’un tableau HTML peuvent présenter divers problèmes, tels que des valeurs manquantes, des problèmes de formatage, des caractères indésirables ou des types de données incorrects. Ces problèmes peuvent conduire à des analyses inexactes et à des résultats peu fiables. Un nettoyage approprié permet de normaliser l’ensemble de données et de garantir qu’il correspond à la structure prévue pour l’analyse.
Dans cette section, les tâches de nettoyage des données suivantes sont effectuées :
- Renommer les noms de colonnes
- Remplacer les valeurs manquantes dans les données des lignes
- Supprimer les virgules et convertir les types de données au format correct
- Suppression du signe de pourcentage (%) et conversion des types de données au format correct
- Modifier les types de données pour les colonnes numériques
Renommer les noms de colonnes
pandas dispose d’une méthode appelée rename() qui permet de modifier le nom d’une colonne spécifique à votre guise. Cette méthode est utile lorsque les noms de colonnes ne sont pas descriptifs ou lorsque vous souhaitez faciliter l’utilisation des noms de colonnes.
Pour renommer une colonne spécifique, vous transmettez un dictionnaire au paramètre columns, où les clés sont les noms de colonnes actuels et les valeurs sont les nouveaux noms que vous souhaitez attribuer. Appliquez cette méthode pour modifier les noms de colonnes suivants :
#àClassementVariation annuelleenVariation annuelle %Part mondialeenPart mondiale %
# Renommer les colonnes
df.rename(columns={'#': 'Rank'}, inplace=True)
df.rename(columns={'Yearly Change': 'Yearly Change %'}, inplace=True)
df.rename(columns={'World Share': 'World Share %'}, inplace=True)
# Afficher les 5 premières lignes
print(df.head())
Vos colonnes devraient maintenant ressembler à ceci :

Remplacer les valeurs manquantes
Les valeurs manquantes dans les données peuvent affecter les calculs, tels que les moyennes ou les sommes, conduisant à des résultats inexacts et à des conclusions erronées. Vous devez les supprimer, les remplacer ou les remplir avec des valeurs particulières avant d’effectuer tout calcul ou analyse sur l’ensemble de données.
La colonne « Urban Pop % » contient actuellement des valeurs manquantes étiquetées comme N.A.. Remplacez N.A. par 0 % à l’aide de la méthode replace() de pandas, comme ceci :
# Remplacer « N.A. » par « 0 % » dans la colonne « Urban Pop % »
df['Urban Pop %'] = df['Urban Pop %'].replace('N.A.', '0%')
Supprimer les signes de pourcentage et convertir les types de données
Les colonnes « Yearly Change % », « Urban Pop % » et « World Share % » contiennent des valeurs numériques suivies d’un signe de pourcentage (par exemple 37,0 %). Cela empêche d’effectuer des opérations mathématiques, telles que le calcul de la moyenne, du maximum et de l’écart type, à des fins d’analyse.
Pour remédier à cela, vous pouvez appliquer la méthode replace() pour supprimer le signe % puis appliquer la méthode astype() pour les convertir en type de données flottantes à des fins d’analyse :
# Supprimer le signe « % » et convertir en float
df['Yearly Change %'] = df['Yearly Change %'].replace('%', '', regex=True).astype(float)
df['Urban Pop %'] = df['Urban Pop %'].replace('%', '', regex=True).astype(float)
df['World Share %'] = df['World Share %'].replace('%', '', regex=True).astype(float)
# Afficher les 5 premières lignes
df.head()
Ce code supprime le signe % des valeurs des colonnes Variation annuelle %, Population urbaine % et Part mondiale % à l’aide de la méthode replace() avec une expression régulière. Il convertit ensuite les valeurs nettoyées en un type de données float à l’aide de astype(float). Enfin, il affiche les cinq premières lignes du DataFrame avec df.head().
Votre résultat devrait ressembler à ceci :

Supprimer les virgules et convertir les types de données
Actuellement, les colonnes Population (2024), Variation nette, Densité (P/Km²), Superficie (Km²) et Migrants (net) contiennent des valeurs numériques avec des virgules (par exemple 1 949 236). Cela rend impossible l’exécution d’opérations mathématiques à des fins d’analyse.
Pour remédier à cela, vous pouvez appliquer les fonctions replace() et astype() afin de supprimer les virgules et de convertir les nombres en type de données entier :
# Supprimer les virgules et convertir en nombres entiers
columns_to_convert = [
'Population (2024)', 'Variation nette', 'Densité (P/Km²)', 'Superficie (Km²)',
'Migrants (net)'
]
for column in columns_to_convert:
# S'assurer que la colonne est d'abord traitée comme une chaîne de caractères
df[column] = df[column].astype(str)
# Supprimer les virgules
df[column] = df[column].str.replace(',', '')
# Convertir en entiers
df[column] = df[column].astype(int)
Ce code définit une liste, columns_to_convert, contenant les noms des colonnes qui doivent être traitées. Pour chaque colonne de la liste, il s’assure que les valeurs des colonnes sont traitées comme des chaînes de caractères à l’aide de astype(str). Il supprime ensuite toutes les virgules des valeurs à l’aide de str.replace(',', ''), puis convertit les valeurs nettoyées en entiers avec astype(int), rendant les valeurs adaptées aux opérations mathématiques.
Modifier les types de données pour les colonnes numériques
Les colonnes Rank, Med. Age et Fert. Rate présentent des données qui sont stockées sous forme de type de données objet, mais qui contiennent des valeurs numériques. Convertissez les données de ces colonnes en types de données entiers ou flottants pour permettre les opérations mathématiques :
# Convertir en types de données entiers ou flottants et en entiers
df['Rank'] = df['Rank'].astype(int)
df['Med. Age'] = df['Med. Age'].astype(int)
df['Fert. Rate'] = df['Fert. Rate'].astype(float)
Ce code convertit les valeurs des colonnes Rank et Med. Age en type de données entier et les valeurs de Fert. Rate en type de données flottant.
Enfin, vérifiez que les données nettoyées ont les types de données corrects à l’aide de la méthode head():
print(df.head(10))
Votre résultat devrait ressembler à ceci :
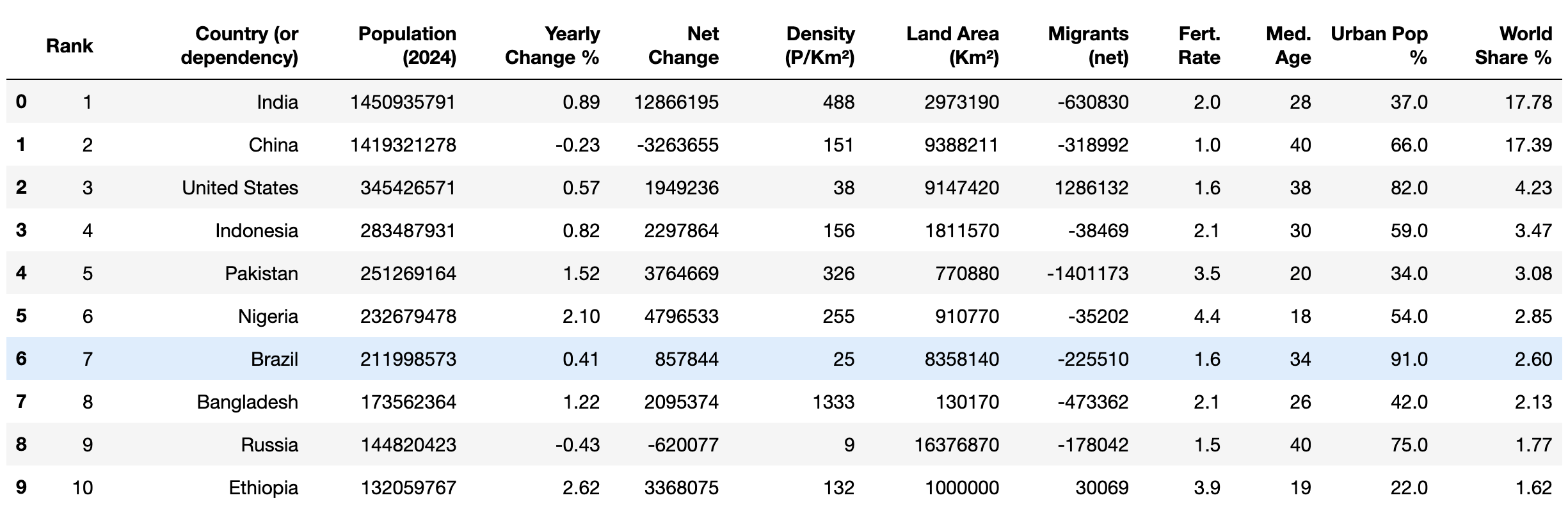
Une fois les données nettoyées, vous pouvez commencer à appliquer différentes opérations mathématiques, telles quela moyenne et le mode, ainsi que des méthodes analytiques, telles quela corrélation, pour examiner les données.
Exporter les données nettoyées au format CSV
Après avoir nettoyé vos données, il est important de les enregistrer pour une utilisation et une analyse futures. Vous pouvez exporter les données nettoyées dans un fichier CSV, ce qui vous permet de les partager facilement avec d’autres personnes ou de les traiter/analyser davantage à l’aide de différents outils et logiciels pris en charge.
La méthode to_csv() de pandas vous permet d’exporter les données d’un DataFrame vers un fichier CSV nommé world_population_by_country.csv:
# Enregistrer les données dans un fichier
filename = 'world_population_by_country.csv'
df.to_csv(filename, index=False)
Conclusion
Le package Python Beautiful Soup vous permet d’analyser des documents HTML et d’extraire des données d’un tableau HTML. Dans cet article, vous avez appris à extraire, nettoyer et exporter des données dans un fichier CSV.
Bien que ce tutoriel soit simple, l’extraction de données à partir de sites web complexes peut s’avérer difficile et fastidieuse. Par exemple, travailler avec des tableaux HTML paginés ou des structures imbriquées où les données sont intégrées dans des éléments parents et enfants nécessite une analyse minutieuse pour comprendre la mise en page. De plus, les structures des sites web peuvent changer au fil du temps, ce qui nécessite une maintenance continue de votre code et de votre infrastructure.
Pour gagner du temps et vous faciliter la tâche, pensez à utiliserl’API Bright Data Web Scraper. Cet outil puissant offre une solution de scraping préconfigurée, vous permettant d’extraire des données de sites web complexes avec un minimum de connaissances techniques. L’API automatise la collecte de données et gère les défis tels que le contenu dynamique, les pages rendues en JavaScript et la vérification CAPTCHA.
Inscrivez-vous et commencez votre essai gratuit de l’API Web Scraper !





