

Google Trendsest un outil gratuit qui fournit des informations sur ce que les gens recherchent en ligne. En analysant ces tendances de recherche, les entreprises peuvent identifier les tendances émergentes du marché, comprendre le comportement des consommateurs et prendre des décisions fondées sur des données afin de stimuler leurs efforts de vente et de marketing. L’extraction de données à partir de Google Trends permet aux entreprises de garder une longueur d’avance sur la concurrence en adaptant leurs stratégies.
Dans cet article, vous apprendrez comment extraire des données de Google Trends à l’aide de Python et comment stocker et analyser ces données de manière efficace.
Pourquoi extraire les données de Google Trends
L’extraction et l’analyse des données de Google Trends peuvent s’avérer utiles dans divers scénarios, notamment les suivants :
- Recherche de mots-clés :les créateurs de contenu et les spécialistes du référencement doivent savoir quels mots-clés gagnent en popularité afin de pouvoir générer davantage de trafic organique vers leurs sites web. Google Trends permet d’explorer les termes de recherche tendance par région, catégorie ou période, ce qui vous permet d’optimiser votre stratégie de contenu en fonction de l’évolution des intérêts des utilisateurs.
- Étude de marché :les spécialistes du marketing doivent comprendre les intérêts des clients et anticiper les changements dans la demande afin de prendre des décisions éclairées. L’extraction et l’analyse des données de Google Trends leur permettent de comprendre les habitudes de recherche des clients et de suivre les tendances au fil du temps.
- Études sociétales :plusieurs facteurs, notamment les événements locaux et mondiaux, les innovations technologiques, les changements économiques et les développements politiques, peuvent avoir un impact significatif sur l’intérêt du public et les tendances de recherche. Les données de Google Trends fournissent des informations précieuses sur ces tendances changeantes au fil du temps, permettant une analyse complète et des prévisions éclairées pour l’avenir.
- Surveillance de la marque :les entreprises et les équipes marketing doivent surveiller la façon dont leur marque est perçue sur le marché. Lorsque vous récupérez les données de Google Trends, vous pouvez comparer la visibilité de votre marque à celle de vos concurrents et réagir rapidement aux changements dans la perception du public.
L’alternative de Bright Data au scraping de Google Trends : l’API SERP de Bright Data
Au lieu de récupérer manuellement les données de Google Trends, utilisez l’API SERP de Bright Data pour automatiser la collecte de données en temps réel à partir des moteurs de recherche. L’API SERP offre des données structurées telles que les résultats de recherche et les tendances, avec un ciblage géographique précis et sans risque de blocage ou de CAPTCHA. Vous ne payez que pour les requêtes réussies, et les données sont fournies aux formats JSON ou HTML pour une intégration facile.
Cette solution est plus rapide, plus évolutive et élimine le besoin de scripts de scraping complexes. Commencez votre essai gratuit et rationalisez votre collecte de données avec le scraper Google Trends de Bright Data.
Comment extraire des données de Google Trends
Google Trends ne propose pas d’API officielles pour extraire les données de tendances, mais vous pouvez utiliser plusieurs API et bibliothèques tierces pour accéder à ces informations, commepytrends, une bibliothèque Python qui fournit des API conviviales vous permettant de télécharger automatiquement des rapports depuis Google Trends. Cependant, bien que pytrends soit facile à utiliser, il fournit des données limitées car il ne peut pas accéder aux données rendues dynamiquement ou situées derrière des éléments interactifs. Pour remédier à ce problème, vous pouvez utiliserSeleniumavecBeautiful Souppour extraire Google Trends et extraire des données à partir de pages web rendues dynamiquement. Selenium est un outil open source permettant d’interagir avec des sites web et d’en extraire des données qui utilise JavaScript pour charger du contenu de manière dynamique. Beautiful Soup aide à analyser le contenu HTML extrait, vous permettant d’extraire des données spécifiques à partir de pages web.
Avant de commencer ce tutoriel, vous devez avoir installé et configuréPythonsur votre machine. Vous devez également créer un répertoire de projet vide pour les scripts Python que vous allez créer dans les sections suivantes.
Créer un environnement virtuel
Un environnement virtuel vous permet d’isoler les paquets Python dans des répertoires séparés afin d’éviter les conflits de version. Pour créer un nouvel environnement virtuel, exécutez la commande suivante dans votre terminal :
# accédez à la racine de votre répertoire de projet avant d'exécuter la commande
python -m venv myenv
Cette commande crée un dossier nommé myenv dans le répertoire du projet. Activez l’environnement virtuel en exécutant la commande suivante :
source myenv/bin/activate
Toutes les commandes Python ou pip suivantes seront également exécutées dans cet environnement.
Installez vos dépendances
Comme indiqué précédemment, vous avez besoin de Selenium et Beautiful Soup pour extraire et analyser les pages web. De plus, pour analyser et visualiser les données extraites, vous devez installer les modules PythonpandasetMatplotlib. Utilisez la commande suivante pour installer ces paquets :
pip install beautifulsoup4 pandas matplotlib selenium
Rechercher des données de recherche Google Trends
Letableau de bord Google Trendsvous permet d’explorer les tendances de recherche par région, période et catégorie. Par exemple, cette URL affiche les tendances de recherche pour le café aux États-Unis au cours des sept derniers jours :
https://trends.google.com/trends/explore?date=now%207-d&geo=US&q=coffee
Lorsque vous ouvrez cette page Web dans votre navigateur, vous remarquerez que les données se chargent dynamiquement à l’aide de JavaScript. Pour extraire du contenu dynamique, vous pouvez utiliserSelenium WebDriver, qui imite les interactions de l’utilisateur, telles que les clics, la saisie ou le défilement.
Vous pouvez utiliserwebdriverdans votre script Python pour charger la page Web dans une fenêtre de navigateur et extraire son code source une fois le contenu chargé. Pour gérer le contenu dynamique, vous pouvez ajouter explicitementtime.sleepafin de vous assurer que tout le contenu est chargé avant de récupérer le code source de la page. Si vous souhaitez en savoir plus sur les techniques permettant de gérer le contenu dynamique, consultezce guide.
Créez un fichier main.py à la racine du projet et ajoutez-y l’extrait de code suivant :
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def get_driver():
# mettez à jour le chemin d'accès à l'emplacement de votre binaire Chrome
CHROME_PATH = "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome"
options = Options()
# options.add_argument("--headless=new")
options.binary_location = CHROME_PATH
driver = webdriver.Chrome(options=options)
return driver
def get_raw_trends_data(
driver: webdriver.Chrome, date_range: str, geo: str, query: str)
-> str:
url = f"https://trends.google.com/trends/explore?date={date_range}&geo={geo}&q={query}"
print(f"Récupération des données depuis {url}")
driver.get(url)
# solution de contournement pour obtenir la source de la page après l'erreur 429 initiale
driver.get(url)
driver.maximize_window()
# Attendre le chargement de la page
time.sleep(5)
return driver.page_source
La méthode get_raw_trends_data accepte comme paramètres la plage de dates, la région géographique et le nom de la requête, et utilise Chrome WebDriver pour récupérer le contenu de la page. Notez que la méthode driver.get est appelée deux fois comme solution de contournement pour corriger l'erreur 429 initiale générée par Google lors du premier chargement de l’URL.
Vous utiliserez cette méthode dans les sections suivantes pour récupérer des données.
Analyser les données à l’aide de Beautiful Soup
La page Tendances d’un terme de recherche comprend un widget Intérêt par sous-région qui contient des enregistrements paginés avec des valeurs comprises entre 0 et 100, indiquant la popularité du terme de recherche en fonction de l’emplacement. Utilisez l’extrait de code suivant pour analyser ces données avec Beautiful Soup :
# Ajouter l'importation
from bs4 import BeautifulSoup
def extract_interest_by_sub_region(content: str) -> dict:
soup = BeautifulSoup(content, "html.parser")
interest_by_subregion = soup.find("div", class_="geo-widget-wrapper geo-resolution-subregion")
related_queries = interest_by_subregion.find_all("div", class_="fe-atoms-generic-content-container")
# Dictionnaire pour stocker les données extraites
interest_data = {}
# Extraire le nom de la région et le pourcentage d'intérêt
for query in related_queries:
items = query.find_all("div", class_="item")
for item in items:
region = item.find("div", class_="label-text").text.strip()
interest = item.find("div", class_="progress-value").text.strip()
interest_data[region] = interest
return interest_data
Cet extrait de code recherche la balise div correspondante pour les données de sous-région à l’aide de son nom de classe et itère sur le résultat pour construire un dictionnaire interest_data.
Notez que le nom de la classe pourrait changer à l’avenir et que vous devrez peut-être utiliser lafonctionnalitéInspecterl’élément de Chrome DevToolspour trouver le nom correct.
Maintenant que vous avez défini les méthodes d’aide, utilisez l’extrait de code suivant pour interroger les données relatives au « café » :
# Paramètres
date_range = « now 7-d »
geo = « US »
query = « coffee »
# Obtenir les données brutes
driver = get_driver()
raw_data = get_raw_trends_data(driver, « now 7-d », « US », « coffee »)
# Extraire l'intérêt par région
interest_data = extract_interest_by_sub_region(raw_data)
# Imprimer les données extraites
for region, interest in interest_data.items():
print(f"{region}: {interest}")
Votre résultat ressemble à ceci :
Hawaï : 100
Montana : 96
Oregon : 90
Washington : 86
Californie : 84
Gérer la pagination des données
Comme les données du widget sont paginées, l’extrait de code de la section précédente ne renvoie que les données de la première page du widget. Pour récupérer davantage de données, vous pouvez utiliser Selenium WebDriver pour trouver et cliquer sur le bouton Suivant. De plus, votre script doit gérer la bannière de consentement aux cookies en cliquant sur le bouton Accepter afin de s’assurer que la bannière n’obstrue pas les autres éléments de la page.
Pour gérer les cookies et la pagination, ajoutez cet extrait de code à la fin de main.py:
# Ajouter l'importation
from selenium.webdriver.common.by import By
all_data = {}
# Accepter les cookies
driver.find_element(By.CLASS_NAME, "cookieBarConsentButton").click()
# Obtenir les données d'intérêt paginées
while True:
# Cliquer sur le bouton md pour charger plus de données si disponibles
try:
geo_widget = driver.find_element(
By.CSS_SELECTOR, "div.geo-widget-wrapper.geo-resolution-subregion"
)
# Trouver le bouton « Charger plus » avec le nom de classe « md-button » et l'étiquette aria « Next »
load_more_button = geo_widget.find_element(
By.CSS_SELECTOR, "button.md-button[aria-label='Next']"
)
icon = load_more_button.find_element(By.CSS_SELECTOR, ".material-icons")
# Vérifier si le bouton est désactivé en vérifiant que le nom de classe inclut arrow-right-disabled
if "arrow-right-disabled" in icon.get_attribute("class"):
print("Plus de données à charger")
break
load_more_button.click()
time.sleep(2)
extracted_data = extract_interest_by_sub_region(driver.page_source)
all_data.update(extracted_data)
except Exception as e:
print("Plus de données à charger", e)
break
driver.quit()
Cet extrait utilise l’instance de pilote existante pour trouver et cliquer sur le bouton Suivant en le faisant correspondre à son nom de classe. Il vérifie la présence de la classe arrow-right-disabled dans l’élément pour déterminer si le bouton est désactivé, indiquant que vous avez atteint la dernière page du widget. Il quitte la boucle lorsque cette condition est remplie.
Visualiser les données
Pour accéder facilement aux données que vous avez récupérées et les analyser plus en détail, vous pouvez enregistrer les données extraites de la sous-région dans un fichier CSV à l’aide d’un csv.DictWriter.
Commencez par définir save_interest_by_sub_region dans main.py pour enregistrer le dictionnaire all_data dans un fichier CSV :
# Ajouter l'importation
import csv
def save_interest_by_sub_region(interest_data: dict):
interest_data = [{"Region": region, "Interest": interest} for region, interest in interest_data.items()]
csv_file = "interest_by_region.csv"
# Ouvrir le fichier CSV pour l'écriture
with open(csv_file, mode='w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=["Region", "Interest"])
writer.writeheader() # Écrire l'en-tête
writer.writerows(interest_data) # Écrire les données
print(f"Données enregistrées dans {csv_file}")
return csv_file
Vous pouvez ensuite utiliserpandaspour ouvrir le fichier CSV en tant queDataFrameet effectuer des analyses, telles que le filtrage des données selon des conditions spécifiques, l’agrégation des données à l’aide d’opérationsde regroupementou la visualisation des tendances à l’aide de graphiques.
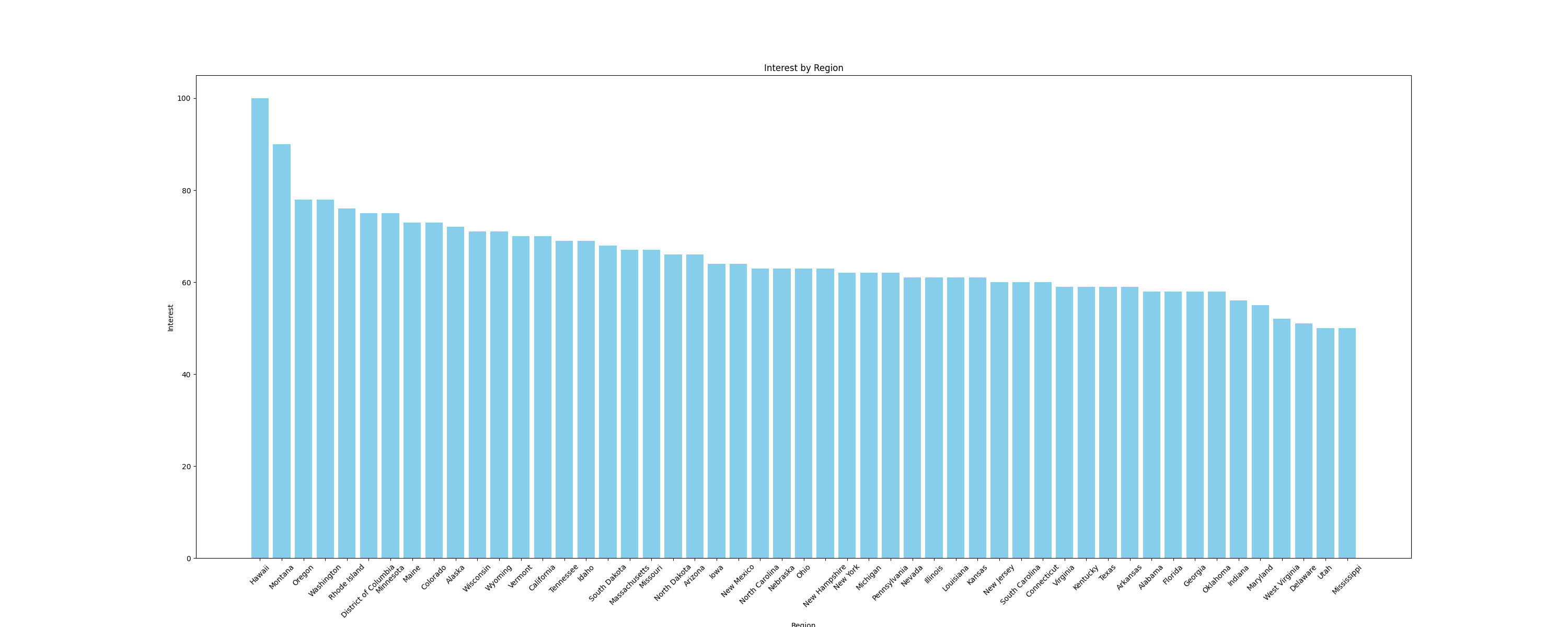
Par exemple, visualisons les données sous forme degraphique à barrespour comparer l’intérêt par sous-région. Pour créer des graphiques, utilisez la bibliothèque Pythonmatplotlib, qui fonctionne parfaitement avec les DataFrames. Ajoutez la fonction suivante au fichiermain.pypour créer un graphique à barres et l’enregistrer sous forme d’image :
# Ajouter les importations
import pandas as pd
import matplotlib.pyplot as plt
def plot_sub_region_data(csv_file_path, output_file_path):
# Charger les données à partir du fichier CSV
df = pd.read_csv(csv_file_path)
# Créer un graphique à barres pour comparer les régions
plt.figure(figsize=(30, 12))
plt.bar(df["Region"], df["Interest"], color="skyblue")
# Ajouter des titres et des étiquettes
plt.title('Intérêt par région')
plt.xlabel('Région')
plt.ylabel('Intérêt')
# Faire pivoter les étiquettes de l'axe x si nécessaire
plt.xticks(rotation=45)
# Afficher le graphique
plt.savefig(output_file_path)
Ajoutez l’extrait de code suivant à la fin du fichier main.py pour appeler les fonctions précédentes :
csv_file_path = save_interest_by_sub_region(all_data)
output_file_path = "interest_by_region.png"
plot_sub_region_data(csv_file_path, output_file_path)
Cet extrait crée un graphique qui ressemble à ceci :
Tout le code de ce tutoriel est disponible dansce dépôt GitHub.
Défis liés au scraping
Dans ce tutoriel, vous avez scrapé une petite quantité de données à partir de Google Trends, mais à mesure que vos scripts de scraping gagnent en taille et en complexité, vous risquez de rencontrer des défis tels que les interdictions d’IP et les CAPTCHA.
Par exemple, si vous envoyez plus fréquemment du trafic vers un site web à l’aide de ce script, vous pourriez être confronté à des interdictions d’IP, car de nombreux sites web ont mis en place des mesures de protection pour détecter et bloquer le trafic des robots. Pour éviter cela, vous pouvez utiliser la rotation manuelle des IP ou l’un des meilleurs services de proxy. Si vous ne savez pas quel type de proxy utiliser, lisez notre article qui présente les meilleurs types de proxy pour le Scraping web.
Les CAPTCHA ou reCAPTCHA sont un autre défi courant auquel les sites web sont confrontés lorsqu’ils détectent ou soupçonnent un trafic de robots ou des anomalies. Pour éviter cela, vous pouvez réduire la fréquence des requêtes, utiliser des en-têtes de requête appropriés ou faire appel à des services tiers capables de résoudre ces problèmes.
Conclusion
Dans cet article, vous avez appris à extraire les données de Google Trends avec Python à l’aide de Selenium et Beautiful Soup.
Au fur et à mesure que vous progresserez dans votre apprentissage du Scraping web, vous rencontrerez peut-être des défis tels que les interdictions d’IP et les CAPTCHA. Plutôt que de gérer des scripts de scraping complexes, envisagez d’utiliser l’API SERP de Bright Data, qui automatise le processus de collecte de données précises et en temps réel sur les moteurs de recherche, y compris Google Trends. L’API SERP gère le contenu dynamique, le ciblage basé sur la localisation et garantit des taux de réussite élevés, vous permettant ainsi d’économiser du temps et des efforts.
Inscrivez-vous dès maintenant et commencez votre essai gratuit de l’API SERP !






