

Etsy est un site réputé pour être difficile à scraper. Il utilise diverses tactiques de blocage et dispose de l’un des systèmes de blocage de bots les plus sophistiqués du web. De l’analyse détaillée des en-têtes à une vague apparemment infinie de CAPTCHA, Etsy est le cauchemar des Scrapers du monde entier. Si vous parvenez à surmonter ces obstacles, Etsy devient un site relativement facile à scraper.
Si vous parvenez à scraper Etsy, vous aurez accès à une mine de données sur les petites entreprises provenant de l’une des plus grandes places de marché que l’internet ait à offrir. Suivez-nous dès aujourd’hui et vous serez en mesure de scraper Etsy comme un pro en un rien de temps. Nous allons apprendre à scraper tous les types de pages suivants sur Etsy.
- Résultats de recherche
- Pages de produits
- Pages boutique
Pour commencer
Python Requests et BeautifulSoup seront nos outils de prédilection pour ce tutoriel. Vous pouvez les installer à l’aide des commandes ci-dessous. Requests nous permet d’effectuer des requêtes HTTP et de communiquer avec les serveurs d’Etsy. BeautifulSoup nous donne la possibilité d’analyser les pages web à l’aide de Python. Nous vous suggérons de lire d’abord notre guide sur l’utilisation de BeautifulSoup pour le Scraping web.
Installer Requests
pip install requests
Installer BeautifulSoup
pip install beautifulsoup4
Que récupérer sur Etsy
Si vous inspectez une page Etsy, vous risquez de vous retrouver pris dans un enchevêtrement complexe d’éléments imbriqués. Si vous savez où chercher, cela n’a rien de bien compliqué. Les pages Etsy utilisent des données JSON pour afficher la page dans le navigateur. Si vous parvenez à trouver le JSON, vous pouvez trouver toutes les données utilisées pour créer la page… sans avoir à fouiller trop profondément dans le code HTML du document.
Résultats de recherche
Les pages de recherche d’Etsy contiennent un ensemble d’objets JSON. Si vous regardez l’image ci-dessous, toutes ces données se trouvent dans un élément de script avec type="application/ld+json". Si vous regardez de très près, ces données JSON contiennent un ensemble appelé itemListElement. Si nous pouvons extraire cet ensemble, nous obtenons toutes les données utilisées pour créer la page.
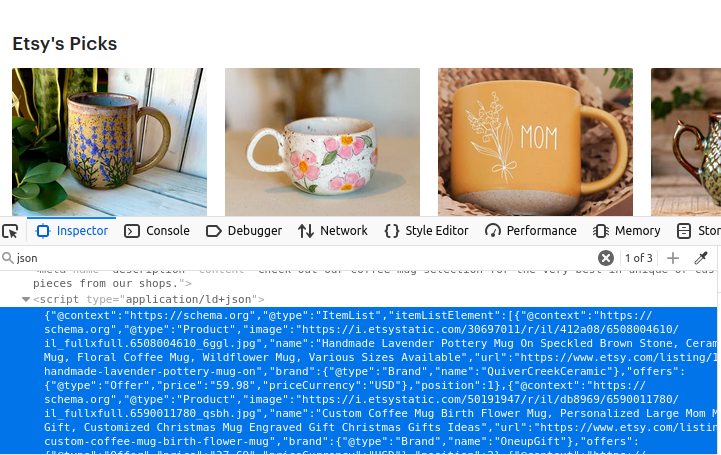
Informations sur les produits
Leurs pages de produits ne sont pas très différentes. Regardez l’image ci-dessous : une fois encore, nous avons une balise script avec type="application/ld+json". Cette balise contient toutes les informations qui ont été utilisées pour créer la page du produit.
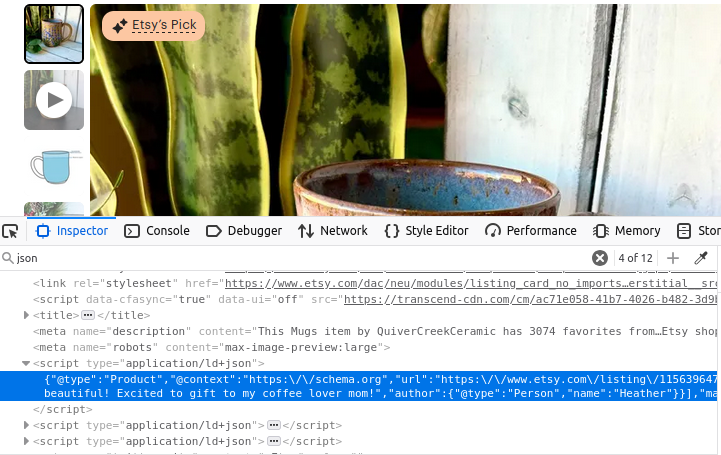
Boutiques
Vous l’avez sans doute deviné, nos pages boutique sont également construites de la même manière. Trouvez le premier objet script sur la page avec type="application/ld+json" et vous obtiendrez vos données.
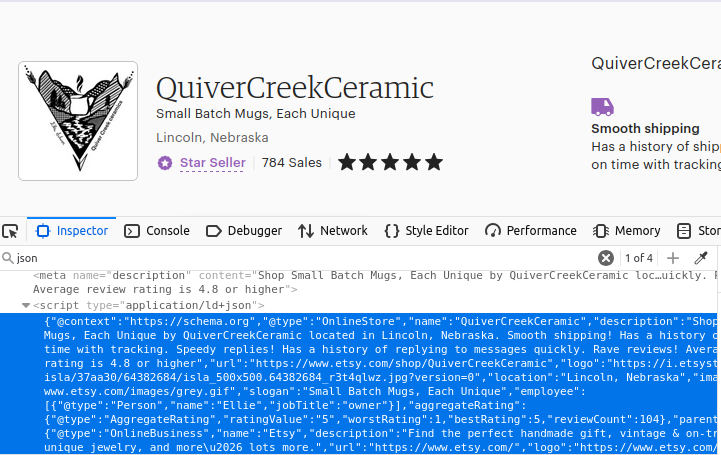
Comment scraper Etsy avec Python
Nous allons maintenant passer en revue tous les composants nécessaires à la construction. Comme mentionné précédemment, Etsy utilise diverses tactiques pour nous empêcher d’accéder au site. Nous utilisons Web Unlocker comme un couteau suisse pour contourner ces blocages. Non seulement il gère les connexions Proxy pour nous, mais il résout également tous les CAPTCHA qui se présentent à nous. Vous pouvez essayer sans Proxy, mais lors de nos premiers tests, nous n’avons pas réussi à contourner les systèmes de blocage d’Etsy sans Web Unlocker.
Une fois que vous disposez d’une instance Web Unlocker, vous pouvez configurer votre connexion Proxy en créant un simple dict. Nous utilisons le certificat SSL de Bright Data pour garantir que nos données restent cryptées pendant leur transfert. Dans le code ci-dessous, nous spécifions le chemin d’accès à notre certificat SSL, puis utilisons notre nom d’utilisateur, notre nom de zone et notre mot de passe pour créer l’URL du Proxy. Nos proxys sont créés en construisant une URL personnalisée qui transfère toutes nos requêtes via l’un des services Proxy de Bright Data.
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<VOTRE-NOM-D'UTILISATEUR>-zone-<VOTRE-NOM-DE-ZONE>:<VOTRE-MOT-DE-PASSE>@brd.superproxy.io:33335',
'https': 'http://brd-customer-<VOTRE-NOM-D'UTILISATEUR>-zone-<VOTRE-NOM-DE-ZONE>:<VOTRE-MOT-DE-PASSE>@brd.superproxy.io:33335'
}
Résultats de recherche
Pour extraire nos résultats de recherche, nous effectuons une requête à l’aide de nos Proxies. Nous utilisons ensuite BeautifulSoup pour analyser le document HTML entrant. Nous trouvons les données à l’intérieur de la balise script et les chargeons sous forme d’objet JSON. Ensuite, nous renvoyons le champ itemListElement à partir du JSON.
def etsy_search(keyword):
encoded_keyword = urlencode({"q": keyword})
url = f"https://www.etsy.com/search?{encoded_keyword}"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
full_json = json.loads(script.text)
return full_json["itemListElement"]
Informations sur les produits
Nos informations sur les produits sont extraites essentiellement de la même manière. La seule différence réelle est l’absence d'itemListElement. Cette fois-ci, nous utilisons notre listing_id pour créer notre URL et nous extrayons l’objet JSON dans son intégralité.
def etsy_product(listing_id) :
url = f"https://www.etsy.com/listing/{listing_id}/"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)
Boutiques
Pour extraire les boutiques, nous suivons le même modèle que celui utilisé pour les produits. Nous utilisons le nom de la boutique (shop_name) pour construire l’URL. Une fois que nous avons obtenu la réponse, nous trouvons le JSON, le chargeons en tant que JSON et renvoyons les données extraites de la page.
def etsy_shop(shop_name):
url = f"https://www.etsy.com/shop/{shop_name}"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)
Stockage des données
Nos données sont structurées en JSON dès leur extraction. Nous pouvons écrire notre sortie dans un fichier à l’aide de la gestion de fichiers de base de Python et de json.dumps(). Nous l’écrivons avec indent=4 afin qu’il soit clair et lisible lorsque des humains consultent le fichier.
with open("products.json", "w") as file:
json.dump(products, file, indent=4)
Tout assembler
Maintenant que nous savons comment construire nos éléments, nous allons tout assembler. Le code ci-dessous utilise les fonctions que nous venons d’écrire et renvoie les données souhaitées au format JSON. Nous écrivons ensuite chacun de ces objets dans leurs propres fichiers JSON individuels.
import requests
import json
from bs4 import BeautifulSoup
from urllib.parse import urlencode
# Configuration du Proxy et du certificat (IDENTIFIANTS HARD-CODÉS)
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<VOTRE-NOM-D'UTILISATEUR>-zone-<VOTRE-NOM-DE-ZONE>:<VOTRE-MOT-DE-PASSE>@brd.superproxy.io:22225',
'https': 'http://brd-customer-<VOTRE-NOM-D'UTILISATEUR>-zone-<VOTRE-NOM-DE-ZONE>:<VOTRE-MOT-DE-PASSE>@brd.superproxy.io:22225'
}
def fetch_etsy_data(url):
"""Récupère et analyse les données JSON-LD d'une page Etsy."""
try:
response = requests.get(url, proxies=proxies, verify=path_to_cert)
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"Échec de la requête : {e}")
return None
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
if not script:
print("Script JSON-LD introuvable sur la page.")
return None
try:
return json.loads(script.text)
except json.JSONDecodeError as e:
print(f"Erreur d'analyse JSON : {e}")
return None
def etsy_search(keyword):
"""Recherche un mot-clé donné sur Etsy et renvoie les résultats."""
encoded_keyword = urlencode({"q": keyword})
url = f"https://www.etsy.com/search?{encoded_keyword}"
data = fetch_etsy_data(url)
return data.get("itemListElement", []) if data else None
def etsy_product(listing_id):
"""Récupère les détails d'un produit à partir d'une annonce Etsy."""
url = f"https://www.etsy.com/listing/{listing_id}/"
return fetch_etsy_data(url)
def etsy_shop(shop_name):
"""Récupérer les détails d'une boutique à partir d'une page de boutique Etsy."""
url = f"https://www.etsy.com/shop/{shop_name}"
return fetch_etsy_data(url)
def save_to_json(data, filename):
"""Enregistrer les données dans un fichier JSON avec gestion des erreurs."""
try:
with open(filename, "w", encoding="utf-8") as file:
json.dump(data, file, indent=4, ensure_ascii=False, default=str)
print(f"Données enregistrées avec succès dans {filename}")
except (IOError, TypeError) as e:
print(f"Erreur lors de l'enregistrement des données dans {filename} : {e}")
if __name__ == "__main__":
# Recherche de produit
products = etsy_search("coffee mug")
if products:
save_to_json(products, "products.json")
# Article spécifique
item_info = etsy_product(1156396477)
if item_info:
save_to_json(item_info, "item.json")
# Boutique Etsy
shop = etsy_shop("QuiverCreekCeramic")
if shop:
save_to_json(shop, "shop.json")
Vous trouverez ci-dessous quelques exemples de données issues du fichier products.json.
{
"@context": "https://schema.org",
"@type": "Product",
"image": "https://i.etsystatic.com/34923795/r/il/8f3bba/5855230678/il_fullxfull.5855230678_n9el.jpg",
"name": "Tasse à café personnalisée avec photo, tasse à café personnalisée avec image, cadeau anniversaire pour lui/elle, tasse personnalisable avec logo/texte pour hommes/femmes",
« url » : « https://www.etsy.com/listing/1193808036/custom-coffee-mug-with-photo »,
« brand » : {
« @type » : « Brand »,
« name » : « TheGiftBucks »
},
« offers » : {
« @type » : « Offer »,
« price » : « 14,99 »,
« priceCurrency » : « USD »
},
« position » : 1
},
Envisagez d’utiliser des jeux de données
Nos jeux de données constituent une excellente alternative au Scraping web. Vous pouvez acheter des jeux de données Etsy prêts à l’emploi ou l’un de nos autres jeux de données e-commerce et éliminer complètement votre processus de scraping ! Une fois que vous avez créé un compte, rendez-vous sur notre marché de données.
Tapez « Etsy » et cliquez sur l’ensemble de données Etsy.

Vous aurez ainsi accès à des millions d’enregistrements provenant des données Etsy… à portée de main. Vous pouvez même télécharger des exemples de données pour voir comment elles fonctionnent.
Conclusion
Dans ce tutoriel, nous avons exploré en détail le scraping Etsy. Vous avez suivi un cours accéléré sur l’intégration des Proxies. Vous savez comment utiliser Web Unlocker pour contourner même les bloqueurs de bots les plus stricts. Vous savez comment extraire les données et vous savez également comment les stocker. Vous avez également pu découvrir nos Jeux de données prêts à l’emploi qui vous évitent complètement d’avoir à effectuer du scraping. Quelle que soit la manière dont vous obtenez vos données, nous avons ce qu’il vous faut.
Inscrivez-vous dès maintenant et commencez votre essai gratuit.





