Dans ce guide, vous découvrirez :
- Tout ce que vous devez savoir pour vous lancer dans le scraping avec DuckDuckGo.
- Les approches les plus populaires et les plus efficaces pour le Scraping web DuckDuckGo.
- Comment créer un Scraper DuckDuckGo personnalisé.
- Comment utiliser la bibliothèque DDGS pour le scraping de DuckDuckGo.
- Comment récupérer les données des résultats des moteurs de recherche via l’API SERP de Bright Data.
- Comment fournir des données de recherche DuckDuckGo à un agent IA via MCP.
C’est parti !
Premiers pas avec le scraping DuckDuckGo
DuckDuckGo est un moteur de recherche qui offre une protection intégrée contre les traceurs en ligne. Les utilisateurs l’apprécient pour sa politique axée sur la confidentialité, car il ne suit pas les recherches ni l’historique de navigation. Il se distingue ainsi des plateformes de recherche traditionnelles et connaît une augmentation constante de son utilisation depuis plusieurs années.
Le moteur de recherche DuckDuckGo est disponible en deux variantes :
- Version dynamique: la version par défaut, qui nécessite JavaScript et comprend des fonctionnalités telles que «Search Assist », une alternative aux aperçus de l’IA de Google.
- Version statique : une version simplifiée qui fonctionne même sans rendu JavaScript.
Selon la version que vous choisissez, vous aurez besoin de différentes approches de scraping, comme le montre ce tableau récapitulatif :
| Fonctionnalité | Version SERP dynamique | Version SERP statique |
|---|---|---|
| JavaScript requis | Oui | Non |
| Format URL | https://duckduckgo.com/?q=<SEARCH_QUERY> |
https://html.duckduckgo.com/html/?q=<QUESTION_DE_RECHERCHE> |
| Contenu dynamique | Oui, comme les résumés IA et les éléments interactifs | Non |
| Pagination | Complexe, basé sur un bouton « Plus de résultats » | Simple, via un bouton « Suivant » traditionnel avec rechargement de la page |
| Approche de scraping | Outils d’automatisation du navigateur | Client HTTP + analyseur HTML |
Il est temps d’explorer les implications du scraping pour les deux versions de la SERP (page de résultats du moteur de recherche) de DuckDuckGo !
DuckDuckGo : version SERP dynamique
Par défaut, DuckDuckGo charge une page web dynamique qui nécessite un rendu JavaScript, avec une URL telle que :
https://duckduckgo.com/?q=<SEARCH_QUERY>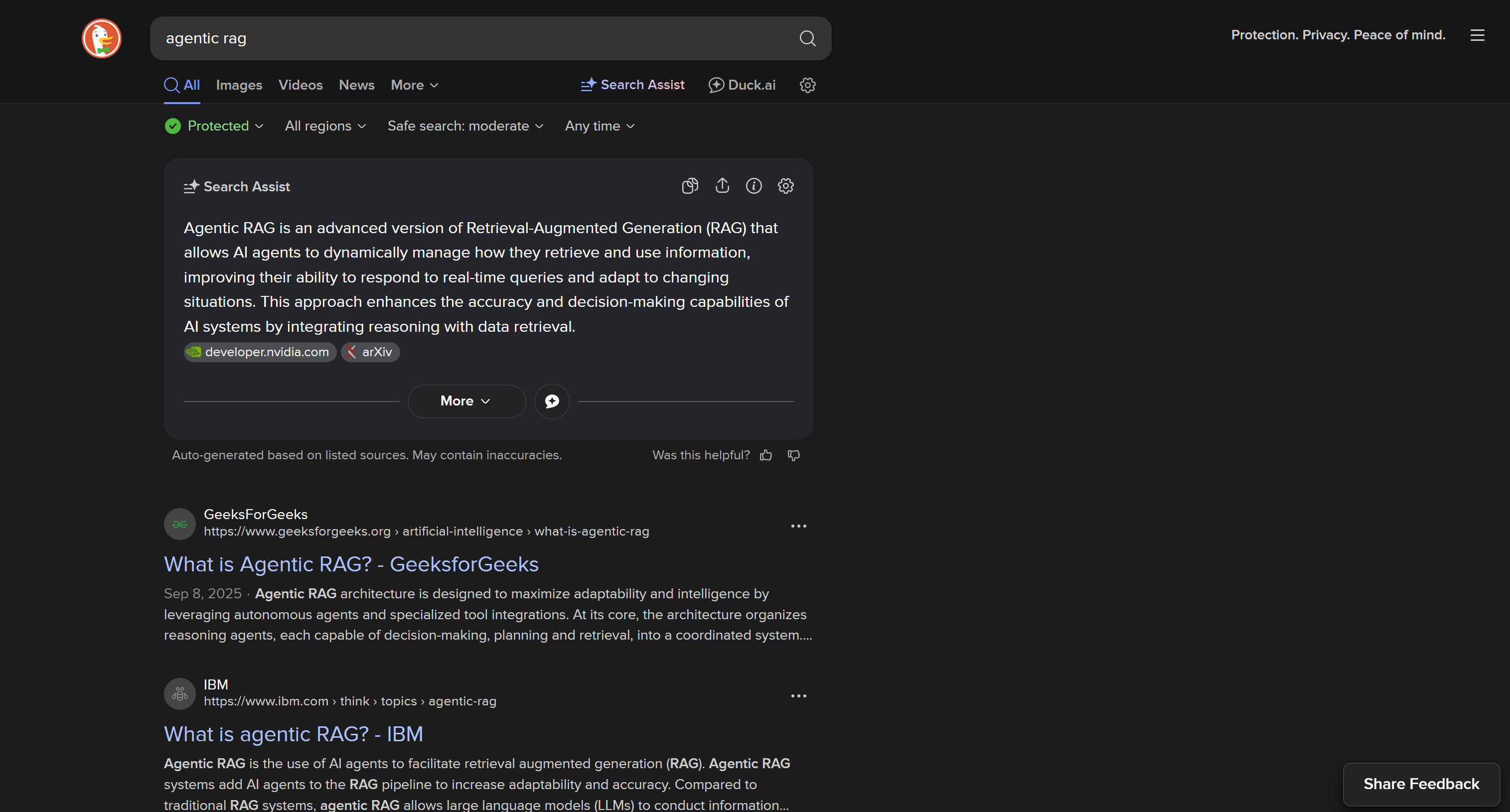
Cette version comprend des interactions utilisateur complexes dans la page, telles que le bouton « Plus de résultats » qui permet de charger dynamiquement d’autres résultats :
La SERP dynamique de DuckDuckGo offre plus de fonctionnalités et des informations plus riches, mais nécessite des outils d’automatisation du navigateur pour le scraping. La raison en est que seul un navigateur peut rendre les pages qui dépendent de JavaScript.
Le problème est que le contrôle d’un navigateur introduit une complexité supplémentaire et une utilisation accrue des ressources. C’est pourquoi la plupart des Scrapers s’appuient sur la version statique du site !
DuckDuckGo : version SERP statique
Pour les appareils qui ne prennent pas en charge JavaScript, DuckDuckGo propose également une version statique de ses SERP. Ces pages suivent un format d’URL comme celui ci-dessous :
https://html.duckduckgo.com/html/?q=<SEARCH_QUERY>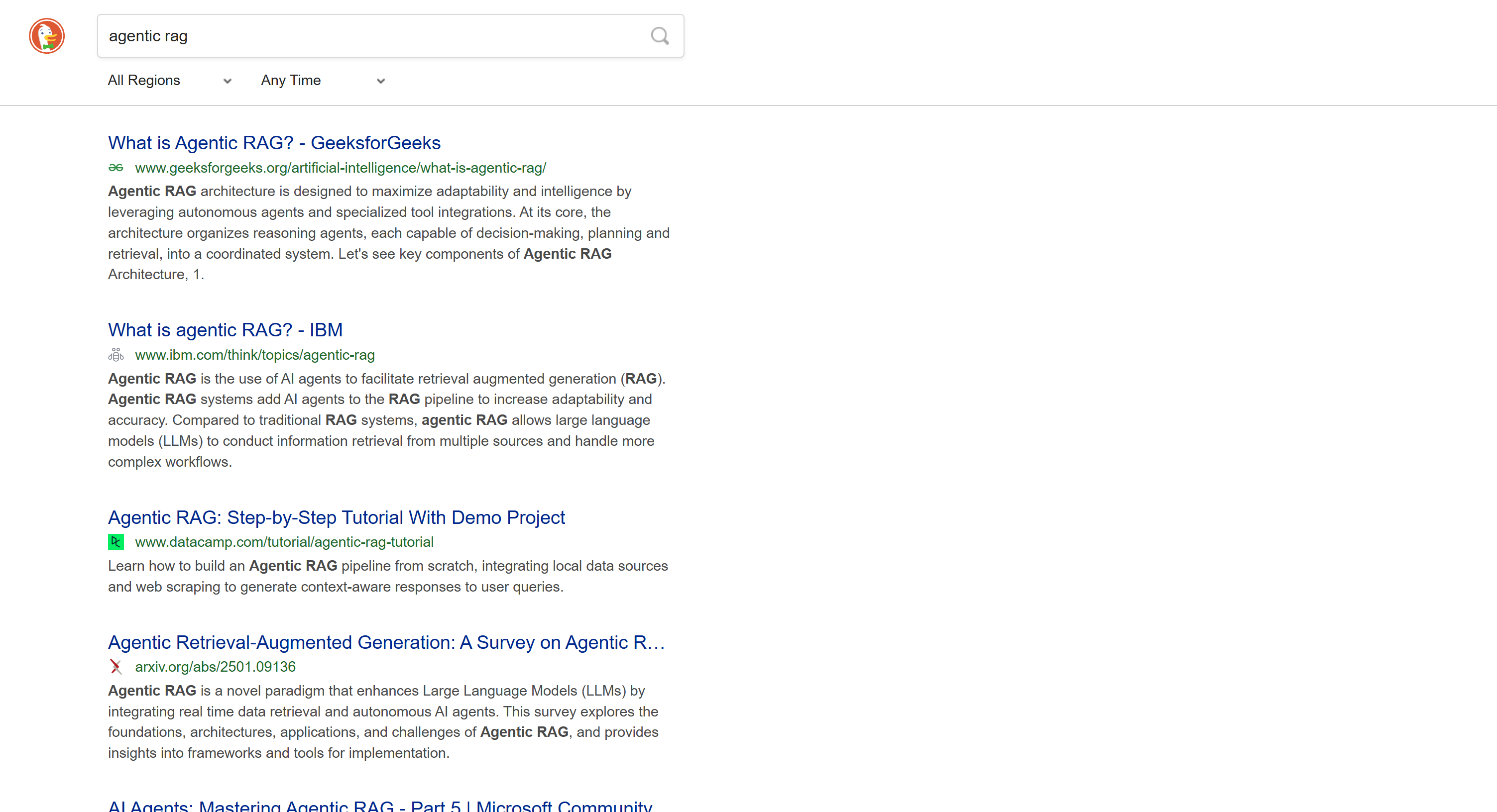
Cette version n’inclut pas de contenu dynamique tel que le résumé généré par l’IA. De plus, la pagination suit une approche plus traditionnelle avec un bouton « Suivant » qui vous amène à la page suivante :
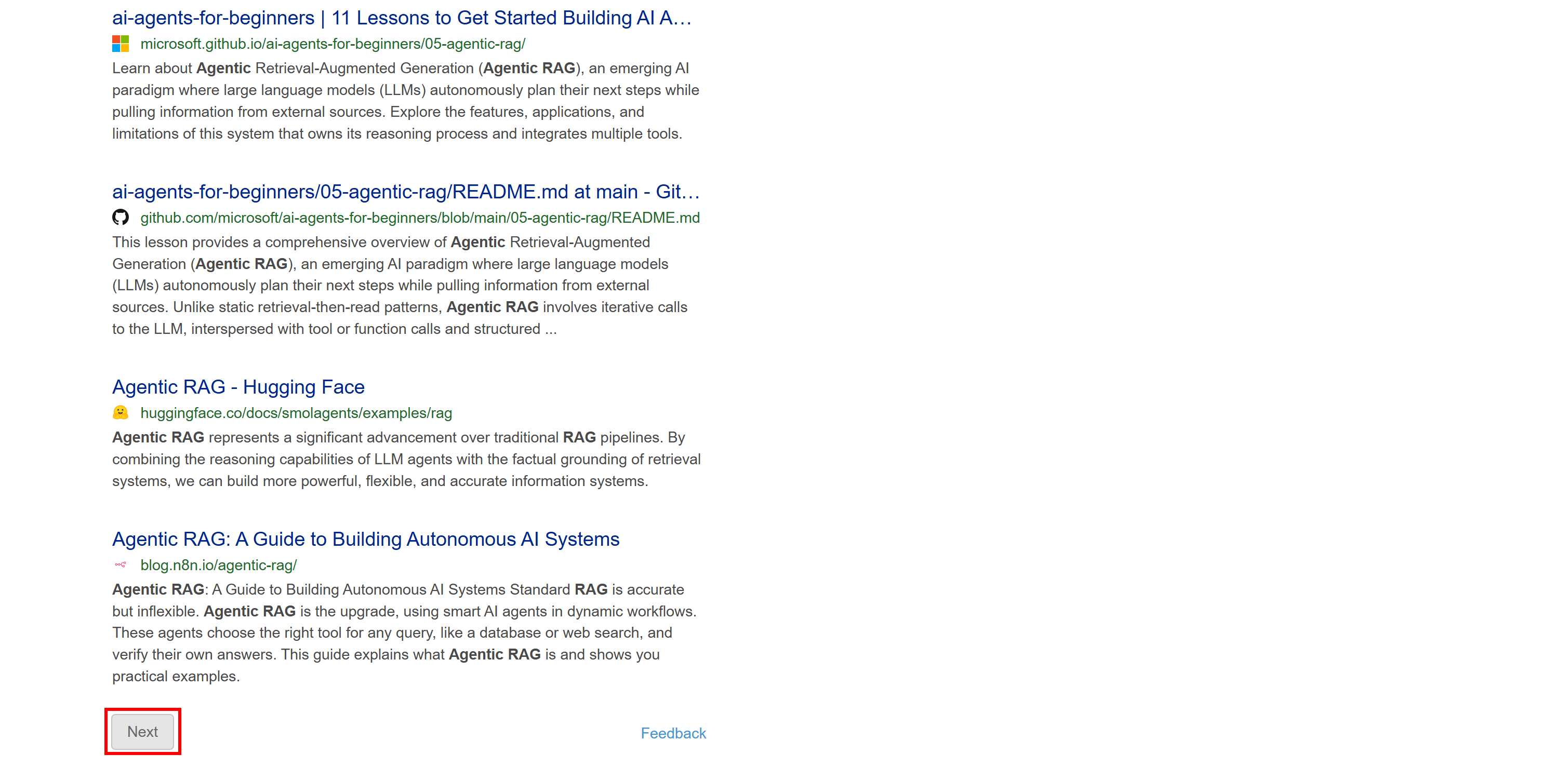
Comme cette SERP est statique, vous pouvez la scraper à l’aide d’une approche traditionnelle client HTTP + analyseur HTML. Cette méthode est plus rapide, plus facile à mettre en œuvre et consomme moins de ressources.
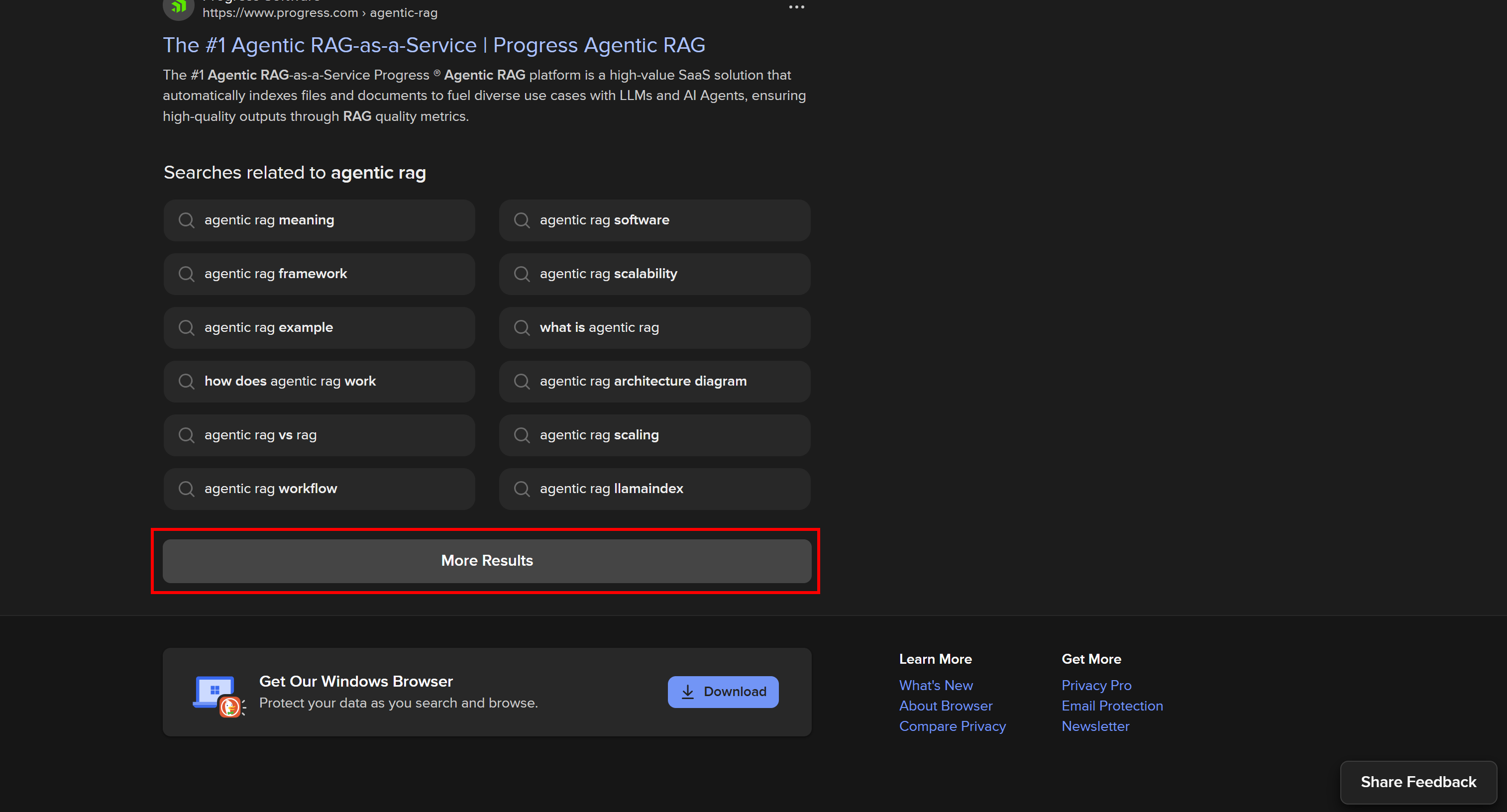
Approches possibles pour extraire DuckDuckGo
Découvrez les quatre approches possibles pour le Scraping web sur DuckDuckGo que nous vous présentons dans cet article :
| Approche | Complexité de l’intégration | Nécessite | Tarification | Risque de blocage | Évolutivité |
|---|---|---|---|---|---|
| Créer un Scraper personnalisé | Moyen/élevé | Compétences en programmation Python | Gratuit (peut nécessiter des Proxy premium pour éviter les blocages) | Possible | Limité |
| S’appuie sur une bibliothèque de scraping DuckDuckGo | Faible | Compétences en Python / utilisation de l’interface CLI | Gratuit (peut nécessiter des Proxy premium pour éviter les blocages) | Possible | Limité |
| Utilisation de l’API SERP de Bright Data | Faible | Tout client HTTP | Payant | Aucun | Illimité |
| Intégrer le serveur Web MCP | Faible | Cadres/solutions d’agent IA prenant en charge MCP | Niveau gratuit disponible, puis payant | Aucun | Illimité |
Vous en apprendrez davantage sur chacun d’entre eux au fur et à mesure que vous avancerez dans ce tutoriel.
Quelle que soit l’approche que vous adoptez, la requête de recherche cible dans cet article de blog sera « agentic rag ». En d’autres termes, vous verrez comment récupérer les résultats de recherche DuckDuckGo pour cette requête.
Nous partons du principe que vous avez déjà installé Python localement et que vous le maîtrisez.
Approche n° 1 : créer un Scraper personnalisé
Utilisez un outil d’automatisation de navigateur ou un client HTTP combiné à un analyseur HTML pour créer un bot de Scraping web DuckDuckGo à partir de zéro.
👍 Avantages:
- Contrôle total sur la logique de scraping.
- Peut être personnalisé pour extraire exactement ce dont vous avez besoin.
👎 Inconvénients:
- Nécessite une configuration et du codage.
- Peut rencontrer des blocages IP en cas de scraping à grande échelle.
Approche n° 2 : s’appuyer sur une bibliothèque de scraping DuckDuckGo
Utilisez une bibliothèque de scraping existante pour DuckDuckGo, telle que DDGS (Duck Distributed Global Search), qui fournit toutes les fonctionnalités dont vous avez besoin sans avoir à écrire une seule ligne de code.
👍 Avantages:
- Configuration minimale requise.
- Gère automatiquement les tâches de scraping des moteurs de recherche, via du code Python ou de simples commandes CLI.
👎 Inconvénients:
- Moins flexible qu’un Scraper personnalisé, avec un contrôle limité sur les cas d’utilisation avancés.
- Rencontre toujours des blocages d’IP.
Approche n° 3 : utiliser l’API SERP de Bright Data
Tirez parti du point de terminaison API SERP premium de Bright Data, que vous pouvez appeler depuis n’importe quel client HTTP. Il prend en charge plusieurs moteurs de recherche, dont DuckDuckGo. Il gère toutes les complexités à votre place tout en offrant un scraping évolutif et à haut volume.
👍 Avantages:
- Évolutivité illimitée.
- Évite les interdictions d’IP et les mesures anti-bot.
- S’intègre aux clients HTTP dans n’importe quel langage de programmation, ou même à des outils visuels tels que Postman.
👎 Inconvénients:
- Service payant.
Approche n° 4 : intégrer le serveur Web MCP
Dotez votre agent IA de capacités de scraping DuckDuckGo en accédant gratuitement à l’API SERP de Bright Data via le Web MCP de Bright Data.
👍 Avantages:
- Intégration facile de l’IA.
- Niveau gratuit disponible.
- Facile à utiliser dans les agents IA et les flux de travail.
👎 Inconvénients:
- Vous ne pouvez pas contrôler entièrement les LLM.
Approche n° 1 : créer un Scraper DuckDuckGo personnalisé avec Python
Suivez les étapes ci-dessous pour apprendre à créer un script de scraping DuckDuckGo personnalisé en Python.
Remarque: pour simplifier et accélérer l’analyse des données, nous utiliserons la version statique de DuckDuckGo. Si vous souhaitez collecter des « aides à la recherche » générées par l’IA, consultez notre guide sur le scraping des résultats d’aperçu IA de Google. Vous pouvez facilement l’adapter à DuckDuckGo.
Étape n° 1 : configurez votre projet
Commencez par ouvrir votre terminal et créez un nouveau dossier pour votre projet de Scraper DuckDuckGo :
mkdir duckduckgo-ScraperLe dossier duckduckgo-Scraper/ contiendra votre projet de scraping.
Ensuite, accédez au répertoire du projet et créez un environnement virtuel Python à l’intérieur :
cd duckduckgo-Scraper
python -m venv .venvOuvrez maintenant le dossier du projet dans votre IDE Python préféré. Nous vous recommandons Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Créez un nouveau fichier nommé scraper.py à la racine du répertoire de votre projet. La structure de votre projet devrait ressembler à ceci :
duckduckgo-Scraper/
├── .venv/
└── agent.pyDans le terminal, activez l’environnement virtuel. Sous Linux ou macOS, exécutez :
source venv/bin/activateDe manière équivalente, sous Windows, exécutez :
venv/Scripts/activateUne fois l’environnement virtuel activé, installez les dépendances du projet à l’aide de la commande suivante :
pip install requests beautifulsoup4Les deux bibliothèques requises sont :
requests: un client HTTP Python populaire. Il sera utilisé pour récupérer la version statique du SERP DuckDuckGo.beautifulsoup4: une bibliothèque Python pour l’analyse syntaxique du HTML, qui vous permet d’extraire des données de la page de résultats DuckDuckGo.
Parfait ! Votre environnement de développement Python est maintenant prêt à créer un script de scraping DuckDuckGo.
Étape n° 2 : se connecter à la page cible
Commencez par importer requests dans scraper.py:
import requestsEnsuite, effectuez une requête GET similaire à celle d’un navigateur vers la version statique de DuckDuckGo à l’aide de la méthode requests.get():
# URL de base de la version statique de DuckDuckGo
base_url = "https://html.duckduckgo.com/html/"
# Exemple de requête de recherche
search_query = "agentic rag"
# Pour simuler une requête de navigateur et éviter les erreurs 403
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
# Se connecter à la page SERP cible
params = {
"q": search_query
}
response = requests.get(base_url, params=params, headers=headers)Si vous n’êtes pas familier avec cette syntaxe, consultez notre guide sur les requêtes HTTP Python.
L’extrait ci-dessus enverra une requête HTTP GET à https://html.duckduckgo.com/html/?q=agentic+rag (la SERP cible de ce tutoriel) avec l’en-tête User-Agent suivant :
Mozilla/5.0 (Windows NT 10.0 ; Win64 ; x64) AppleWebKit/537.36 (KHTML, comme Gecko) Chrome/140.0.0.0 Safari/537.36Il est nécessaire de définir un User-Agent réel comme celui ci-dessus pour éviter de recevoir des erreurs 403 Forbidden de DuckDuckGo. En savoir plus sur l’importance de l’en-tête User-Agent dans le Scraping web.
Le serveur répondra à la requête GET avec le code HTML de la page statique DuckDuckGo. Accédez-y avec :
html = response.textVérifiez le contenu de la page en l’imprimant :
print(html)Vous devriez voir un code HTML similaire à celui-ci :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=3.0, user-scalable=1" />
<meta name="referrer" content="origin" />
<meta name="HandheldFriendly" content="true" />
<meta name="robots" content="noindex, nofollow" />
<title>agentic rag chez DuckDuckGo</title>
<!-- Omis pour plus de concision... -->
</head>
<!-- Omis pour plus de concision... -->
<body>
<div>
<div class="serp__results">
<div id="links" class="results">
<div class="result results_links results_links_deep web-result">
<div class="links_main links_deep result__body">
<h2 class="result__title">
<a rel="nofollow" class="result__a"
href="//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.geeksforgeeks.org%2Fartificial%2Dintelligence%2Fwhat%2Dis%2Dagentic%2Drag%2F&rut=db125a181b0852a6be3a488cb8060da7f7359f97d50cdc2b70fd9cd4dd3d1df9">
Qu'est-ce que l'AGENTIC RAG ? - GeeksforGeeks
</a>
</h2>
<!-- Omission pour plus de concision... -->
</div>
</div>
<!-- Autres résultats... -->
</div>
</div>
</div>
</body>
</html>Parfait ! Ce code HTML contient tous les liens SERP que vous souhaitez extraire.
Étape n° 3 : analyser le code HTML
Importez Beautiful Soup dans scraper.py:
from bs4 import BeautifulSoupEnsuite, utilisez-le pour analyser la chaîne HTML récupérée précédemment en une structure arborescente navigable :
soup = BeautifulSoup(html, "html.parser")Cela analyse le code HTML à l’aide du « html.parser » intégré à Python. Vous pouvez également configurer d’autres analyseurs, tels que lxml ou html5lib, comme expliqué dans notre guide de Scraping web BeautifulSoup.
Bravo ! Vous pouvez désormais utiliser l’API BeautifulSoup pour sélectionner des éléments HTML sur la page et extraire les données dont vous avez besoin.
Étape n° 4 : se préparer à extraire tous les résultats SERP
Avant de vous plonger dans la logique du scraping, vous devez vous familiariser avec la structure des SERP de DuckDuckGo. Ouvrez cette page web en mode incognito (pour garantir une session propre) dans votre navigateur :
https://html.duckduckgo.com/html/?q=agentic+ragEnsuite, cliquez avec le bouton droit de la souris sur un élément du résultat SERP et sélectionnez l’option « Inspecter » pour ouvrir les outils de développement du navigateur :
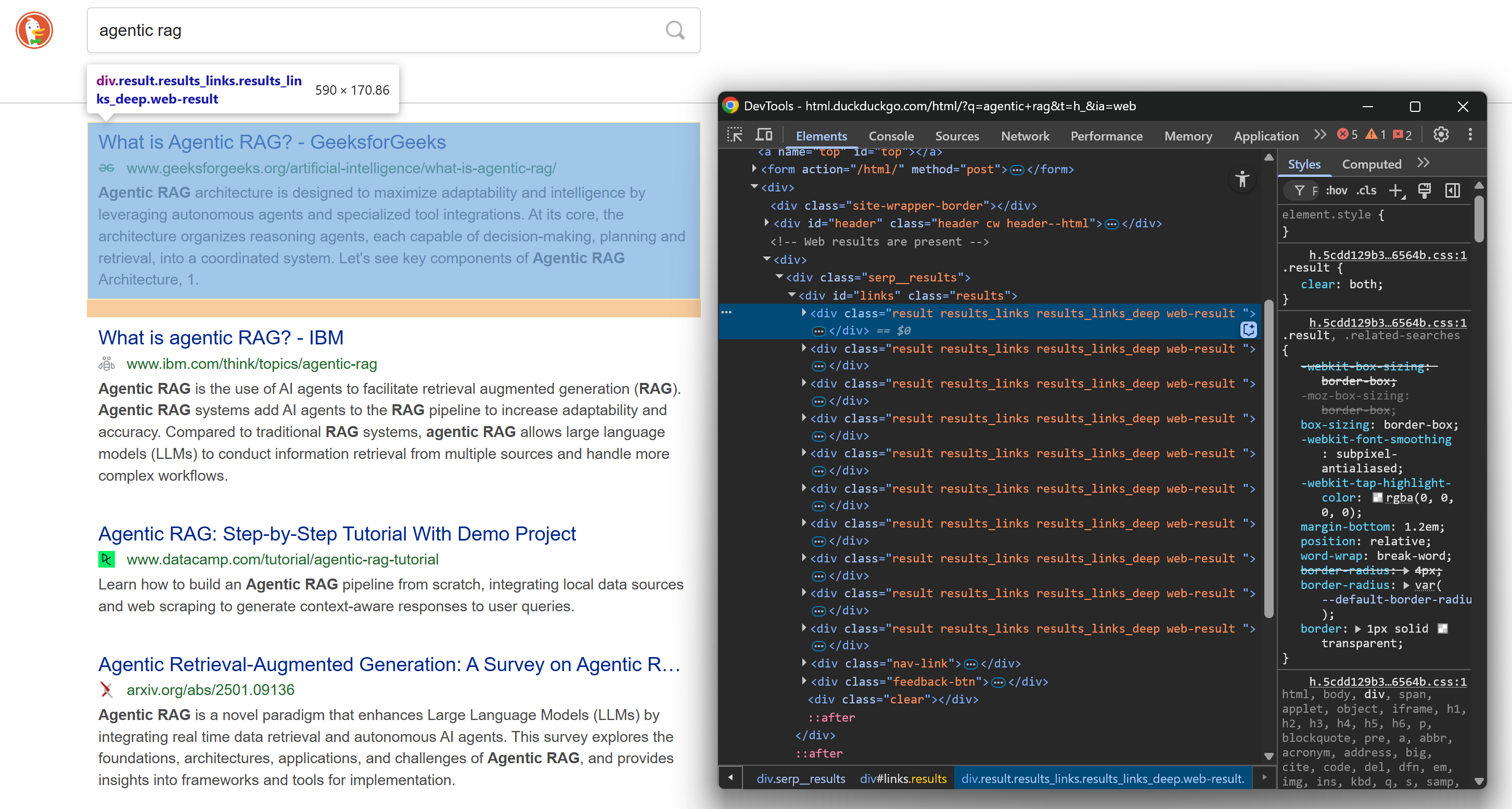
Examinez la structure HTML. Notez que chaque élément SERP possède la classe « result » et est contenu dans un élément <div> identifié par l’ID « links ». Cela signifie que vous pouvez sélectionner tous les éléments de résultats de recherche à l’aide de ce sélecteur CSS :
#links .resultAppliquez ce sélecteur à la page analysée à l’aide de la méthode select() de Beautiful Soup :
result_elements = soup.select("#links .result") Comme la page contient plusieurs éléments SERP, vous aurez besoin d’une liste pour stocker les données extraites. Initialisez-en une comme ceci :
serp_results = []Enfin, parcourez chaque élément HTML sélectionné. Préparez-vous à appliquer votre logique de scraping pour extraire les résultats de recherche DuckDuckGo et remplir la liste serp_results:
for result_element in result_elements:
# Logique d'analyse des données...Super ! Vous êtes maintenant sur le point d’atteindre votre objectif de scraping DuckDuckGo.
Étape n° 5 : extraire les données des résultats
Une fois encore, inspectez la structure HTML d’un élément SERP sur la page de résultats :
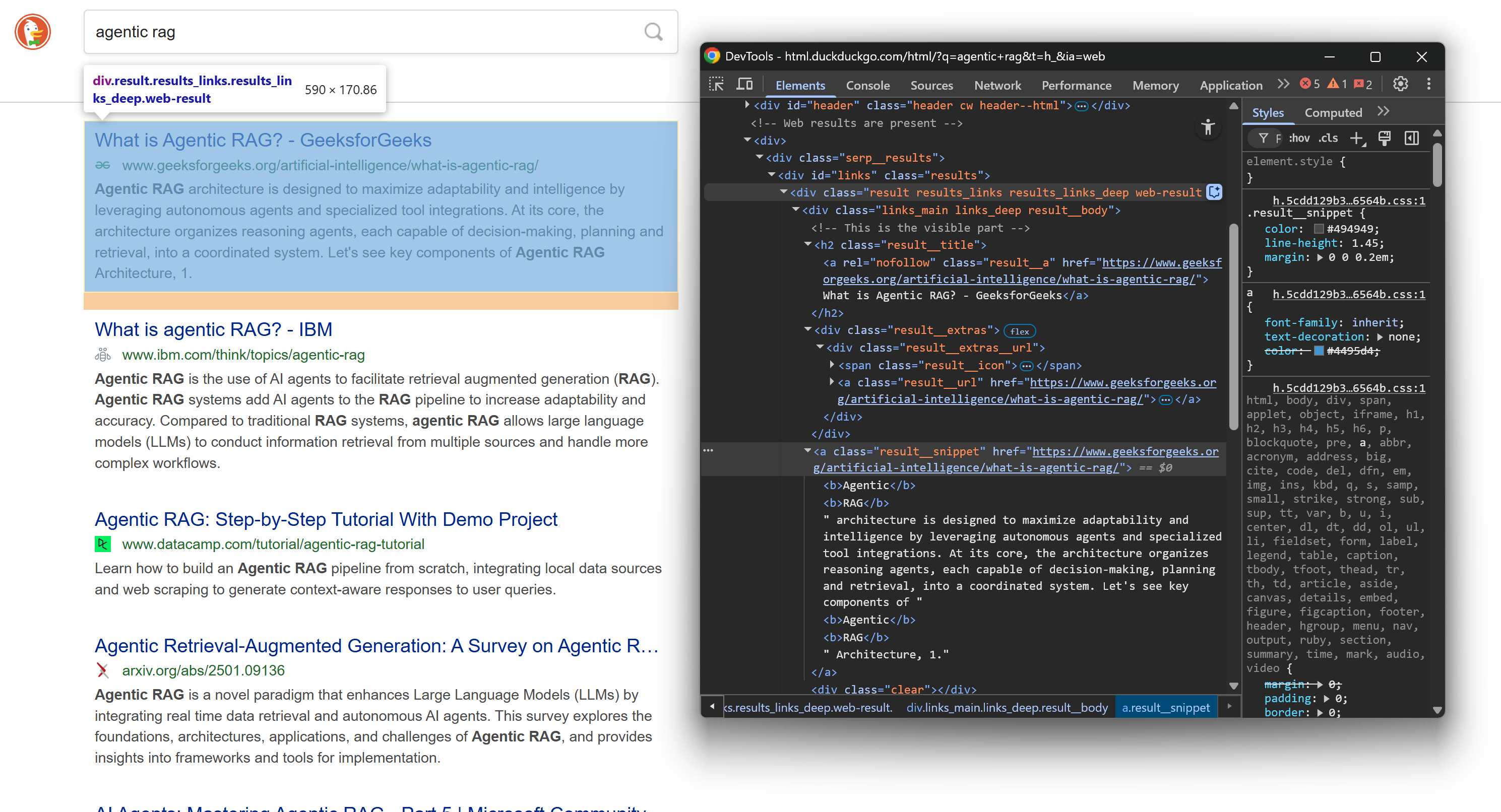
Cette fois-ci, concentrez-vous sur ses nœuds HTML imbriqués. Comme vous pouvez le voir, à partir de ces éléments, vous pouvez scraper :
- Le titre du résultat à partir du texte
.result__a - L’URL du résultat à partir de l’attribut
.result__ahref - L’URL d’affichage à partir du texte
.result__url - L’extrait/la description du résultat à partir du texte
.result__snippet
Appliquez la méthode select_one() de BeautifulSoup pour sélectionner le nœud spécifique, puis utilisez soit .get_text() pour extraire le texte, soit [<attribute_name>] pour accéder à un attribut HTML.
Implémentez la logique de scraping avec :
title_element = result_element.select_one(".result__a")
url = "https:" + title_element["href"]
title = title_element.get_text(strip=True)
url_element = result_element.select_one(".result__url")
display_url = url_element.get_text(strip=True)
snippet_element = result_element.select_one(".result__snippet")
snippet = snippet_element.get_text(strip=True)Remarque: strip=True est utile car il supprime les espaces blancs au début et à la fin du texte extrait.
Si vous vous demandez pourquoi vous devez concaténer « https: » à title_element["href"], c’est parce que le code HTML renvoyé par le serveur est légèrement différent de celui affiché dans votre navigateur. Le code HTML brut, que votre Scraper analyse réellement, contient des URL dans un format comme celui-ci :
//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.geeksforgeeks.org%2Fartificial%2Dintelligence%2Fwhat%2Dis%2Dagentic%2Drag%2F&rut=db125a181b0852a6be3a488cb8060da7f7359f97d50cdc2b70fd9cd4dd3d1df9Comme vous pouvez le constater, l’URL commence par // au lieu d’inclure le schéma (https://). En ajoutant « https: » au début, vous vous assurez que l’URL devient plus utilisable (en dehors des navigateurs, qui prennent également en charge ce format).
Vérifiez ce comportement par vous-même. Cliquez avec le bouton droit de la souris sur la page et sélectionnez l’option « Afficher la source de la page ». Cela vous permettra de voir le document HTML brut renvoyé par le serveur (sans aucun rendu du navigateur). Vous verrez les liens SERP dans ce format :
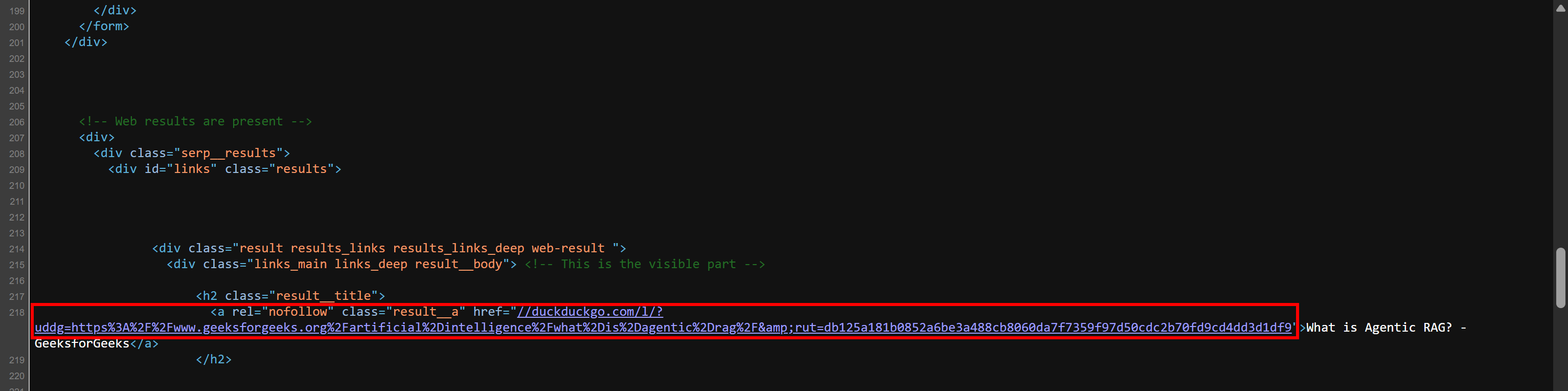
À présent, à l’aide des champs de données extraits, créez un dictionnaire pour chaque résultat de recherche et ajoutez-le à la liste serp_results:
serp_result = {
"url": url,
"title": title,
"display_url": display_url,
"snippet": snippet
}
serp_results.append(serp_result) Parfait ! Votre logique de Scraping web DuckDuckGo est terminée. Il ne reste plus qu’à exporter les données scrapées.
Étape n° 6 : exporter les données extraites au format CSV
À ce stade, vous disposez des résultats de recherche DuckDuckGo stockés dans une liste Python. Pour que ces données puissent être utilisées par d’autres équipes ou outils, exportez-les dans un fichier CSV à l’aide de la bibliothèque csv intégrée à Python :
with open("duckduckgo_results.csv", "w", newline="", encoding="utf-8") as f:
headers = serp_results[0].keys()
writer = csv.DictWriter(f, fieldnames=headers)
# Écrire l'en-tête
writer.writeheader()
# Écrire toutes les lignes de données
writer.writerows(serp_results)N’oubliez pas d’importer csv:
import csvDe cette façon, votre Scraper DuckDuckGo produira un fichier de sortie nommé duckduckgo_results.csv contenant tous les résultats scrapés au format CSV. Mission accomplie !
Étape n° 7 : tout assembler
Le code final contenu dans scraper.py est le suivant :
import requests
from bs4 import BeautifulSoup
import csv
# URL de base de la version statique de DuckDuckGo
base_url = "https://html.duckduckgo.com/html/"
# Exemple de requête de recherche
search_query = "agentic rag"
# Pour simuler une requête de navigateur et éviter les erreurs 403
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
# Se connecter à la page SERP cible
params = {
"q": search_query
}
response = requests.get(base_url, params=params, headers=headers)
# Récupérer le contenu HTML de la réponse
html = response.text
# Analyser le HTML
soup = BeautifulSoup(html, "html.parser")
# Trouver tous les conteneurs de résultats
result_elements = soup.select("#links .result")
# Où stocker les données extraites
serp_results = []
# Parcourir chaque résultat SERP et en extraire les données
for result_element in result_elements:
# Logique d'analyse des données
title_element = result_element.select_one(".result__a")
url = "https:" + title_element["href"]
title = title_element.get_text(strip=True)
url_element = result_element.select_one(".result__url")
display_url = url_element.get_text(strip=True)
snippet_element = result_element.select_one(".result__snippet")
snippet = snippet_element.get_text(strip=True)
# Remplir un nouvel objet SERP result et l'ajouter à la liste
serp_result = {
"url": url,
"title": title,
"display_url": display_url,
"snippet": snippet
}
serp_results.append(serp_result)
# Exporter les données extraites au format CSV
with open("duckduckgo_results.csv", "w", newline="", encoding="utf-8") as f:
headers = serp_results[0].keys()
writer = csv.DictWriter(f, fieldnames=headers)
# Écrire l'en-tête
writer.writeheader()
# Écrire toutes les lignes de données
writer.writerows(serp_results)Waouh ! En moins de 65 lignes de code, vous venez de créer un script de récupération de données DuckDuckGo.
Lancez-le avec cette commande :
python Scraper.pyLe résultat sera un fichier duckduckgo_results.csv, qui apparaîtra dans votre dossier de projet. Ouvrez-le et vous devriez voir les données récupérées comme ceci :

Et voilà ! Vous avez transformé les résultats de recherche non structurés d’une page web DuckDuckGo en un fichier CSV structuré.
[Supplément] Intégrez des proxys rotatifs pour éviter les blocages
Le Scraper ci-dessus fonctionne bien pour les petites exécutions, mais il ne sera pas très évolutif. En effet, DuckDuckGo commencera à bloquer vos requêtes s’il constate un trafic trop important provenant de la même adresse IP. Lorsque cela se produit, ses serveurs commencent à renvoyer des pages d’erreur 403 Forbidden contenant un message comme celui-ci :
Si le problème persiste, veuillez <a href="mailto:[email protected]?subject=Error getting results">nous envoyer un e-mail</a>.<br />
Notre adresse e-mail d'assistance comprend un code d'erreur anonymisé qui nous aide à comprendre le contexte de votre recherche.Cela signifie que le serveur a identifié votre requête comme automatisée et l’a bloquée, généralement en raison d’un problème de limitation de débit. Pour éviter les blocages, vous devez faire tourner votre adresse IP.
La solution consiste à envoyer les requêtes via un Proxy rotatif. Si vous souhaitez en savoir plus sur ce mécanisme, consultez notre guide sur la façon de faire tourner une adresse IP.
Bright Data propose des proxys rotatifs soutenus par un réseau de plus de 150 millions d’adresses IP. Découvrez comment les intégrer à votre Scraper DuckDuckGo pour éviter les blocages !
Suivez le guide officiel de configuration du Proxy et vous obtiendrez une chaîne de connexion Proxy qui ressemble à ceci :
<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335
Configurez le Proxy dans Requests, comme ci-dessous :
proxy_url = "http://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335"
proxies = {
"http": proxy_url,
"https": proxy_url,
}
# définition des paramètres et des en-têtes...
response = requests.get(
base_url,
params=params,
headers=headers,
proxies=proxies, # acheminer la requête via le Proxy rotatif
verify=False,
)Remarque: verify=False désactive la vérification du certificat SSL. Cela évitera les erreurs liées à la validation du certificat Proxy, mais ce n’est pas sécurisé. Pour une implémentation plus adaptée à la production, consultez notre page de documentation sur la validation des certificats SSL.
Désormais, vos requêtes GET vers DuckDuckGo seront acheminées via le réseau de 150 millions de Proxys résidentiels IP de Bright Data, ce qui vous garantit une nouvelle adresse IP à chaque fois et vous aide à éviter les blocages liés à l’adresse IP.
Approche n° 2 : s’appuyer sur une bibliothèque de scraping DuckDuckGo telle que DDGS
Dans cette section, vous apprendrez à utiliser la bibliothèque DDGS. Ce projet open source, qui compte plus de 1 800 étoiles sur GitHub, était auparavant connu sous le nom de duckduckgo-search, car il se concentrait spécifiquement sur DuckDuckGo. Récemment, il a été rebaptisé DDGS (Dux Distributed Global Search), car il prend désormais en charge d’autres moteurs de recherche.
Nous allons ici voir comment l’utiliser à partir de la ligne de commande pour scraper les résultats de recherche DuckDuckGo !
Étape n° 1 : installer DDGS
Installez DDGS globalement ou dans un environnement virtuel via le paquet PyPI ddgs:
pip install -U ddgsUne fois installé, vous pouvez y accéder via l’outil en ligne de commande ddgs. Vérifiez l’installation en exécutant :
ddgs --helpLe résultat devrait ressembler à ceci :
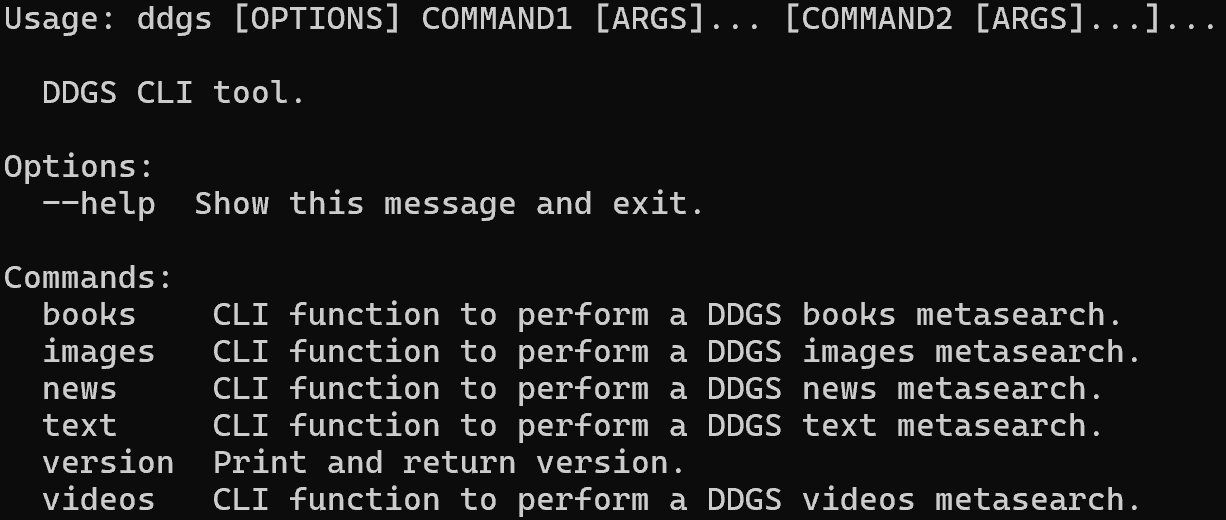
Comme vous pouvez le constater, la bibliothèque prend en charge plusieurs commandes permettant d’extraire différents types de données (par exemple, du texte, des images, des actualités, etc.). Dans ce cas, vous utiliserez la commande text, qui cible les résultats de recherche provenant des SERP.
Remarque: vous pouvez également appeler ces commandes via l’API DDGS dans le code Python, comme expliqué dans la documentation.
Étape n° 2 : Utilisez DDGS via l’interface CLI pour le Scraping web DuckDuckGo
Commencez par vous familiariser avec la commande text en exécutant :
ddgs text --helpCela affichera tous les indicateurs et options pris en charge :
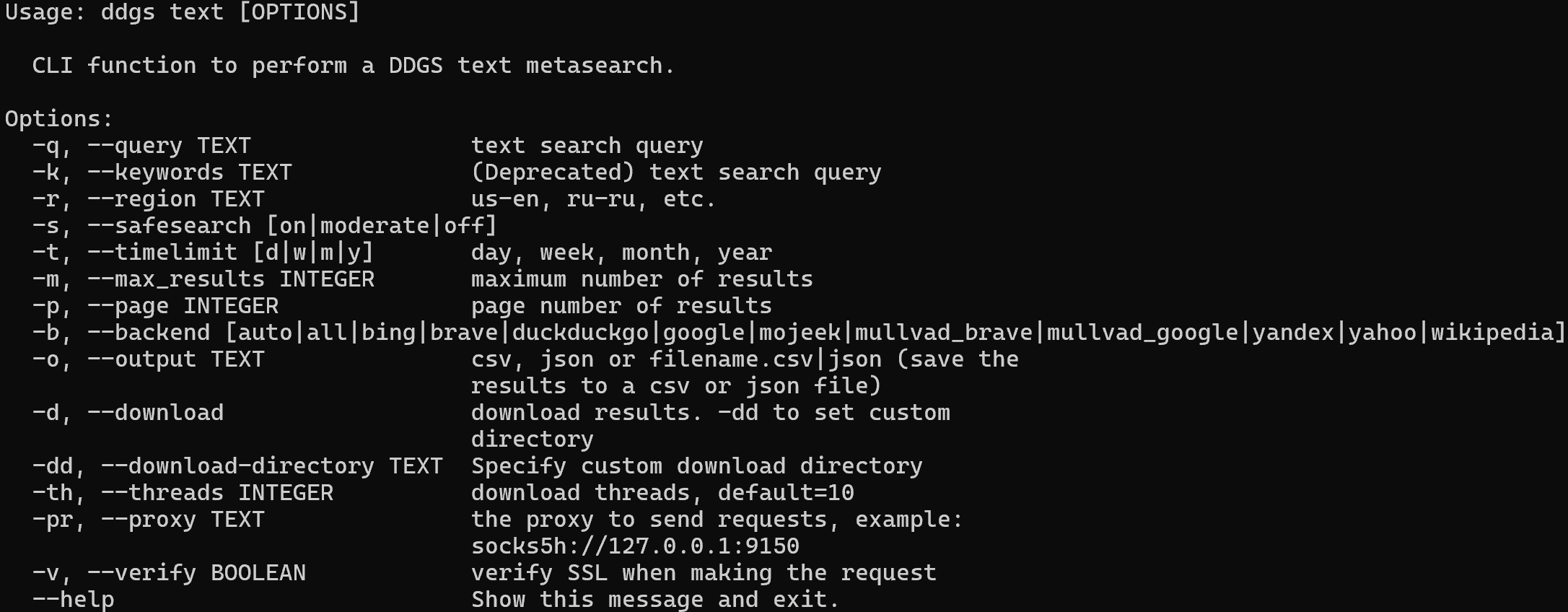
Pour extraire les résultats de recherche DuckDuckGo pour « agentic rag » et les exporter vers un fichier CSV, exécutez :
ddgs text -q « agentic rag » -b duckduckgo -o duckduckgo_results.csvLe résultat sera un fichier duckduckgo_results.csv. Ouvrez-le et vous devriez voir quelque chose comme :

Incroyable ! Vous avez obtenu les mêmes résultats de recherche qu’avec le Scraper Python DuckDuckGo personnalisé, mais avec une seule commande CLI.
[Supplément] Intégrer un Proxy rotatif
Comme vous venez de le constater, DDGS est un outil de recherche SERP et de Scraping web extrêmement puissant. Cependant, il n’est pas magique. Dans le cadre de projets de scraping à grande échelle, il se heurtera aux mêmes interdictions et blocages d’IP mentionnés précédemment.
Pour éviter ces problèmes, comme précédemment, vous avez besoin d’un Proxy rotatif. Il n’est donc pas étonnant que DDGS prenne en charge nativement l’intégration de proxys via le drapeau -pr (ou --proxy).
Récupérez l’URL de votre Proxy rotatif Bright Data et définissez-la dans votre commande CLI ddgs comme suit :
ddgs text -q « agentic rag » -b duckduckgo -o duckduckgo_results.csv -pr <BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335C’est fait ! Les requêtes Web sous-jacentes effectuées par la bibliothèque seront désormais acheminées via le réseau de Proxy rotatifs Bright Data. Cela vous permet d’effectuer du Scraping web en toute sécurité sans vous soucier des blocages liés à l’adresse IP.
Approche n° 3 : utilisation de l’API SERP de Bright Data
Dans ce chapitre, vous apprendrez à utiliser l’API SERP tout-en-un de Bright Data pour récupérer par programmation les résultats de recherche de la version dynamique de DuckDuckGo. Suivez les instructions ci-dessous pour commencer !
Remarque: pour une configuration simplifiée et plus rapide, nous partons du principe que vous disposez déjà d’un projet Python avec la bibliothèque requests installée.
Étape n° 1 : configurez votre zone API SERP Bright Data
Commencez par créer un compte Bright Data ou connectez-vous si vous en avez déjà un. Vous trouverez ci-dessous des instructions pour configurer le produit API SERP pour le scraping de DuckDuckGo.
Pour une configuration plus rapide, vous pouvez également vous référer au guide officiel « Quick Start » (Démarrage rapide) de l’API SERP. Sinon, passez aux étapes suivantes.
Une fois connecté, accédez à votre compte Bright Data et cliquez sur l’option « Proxy & Scraping » pour accéder à cette page :
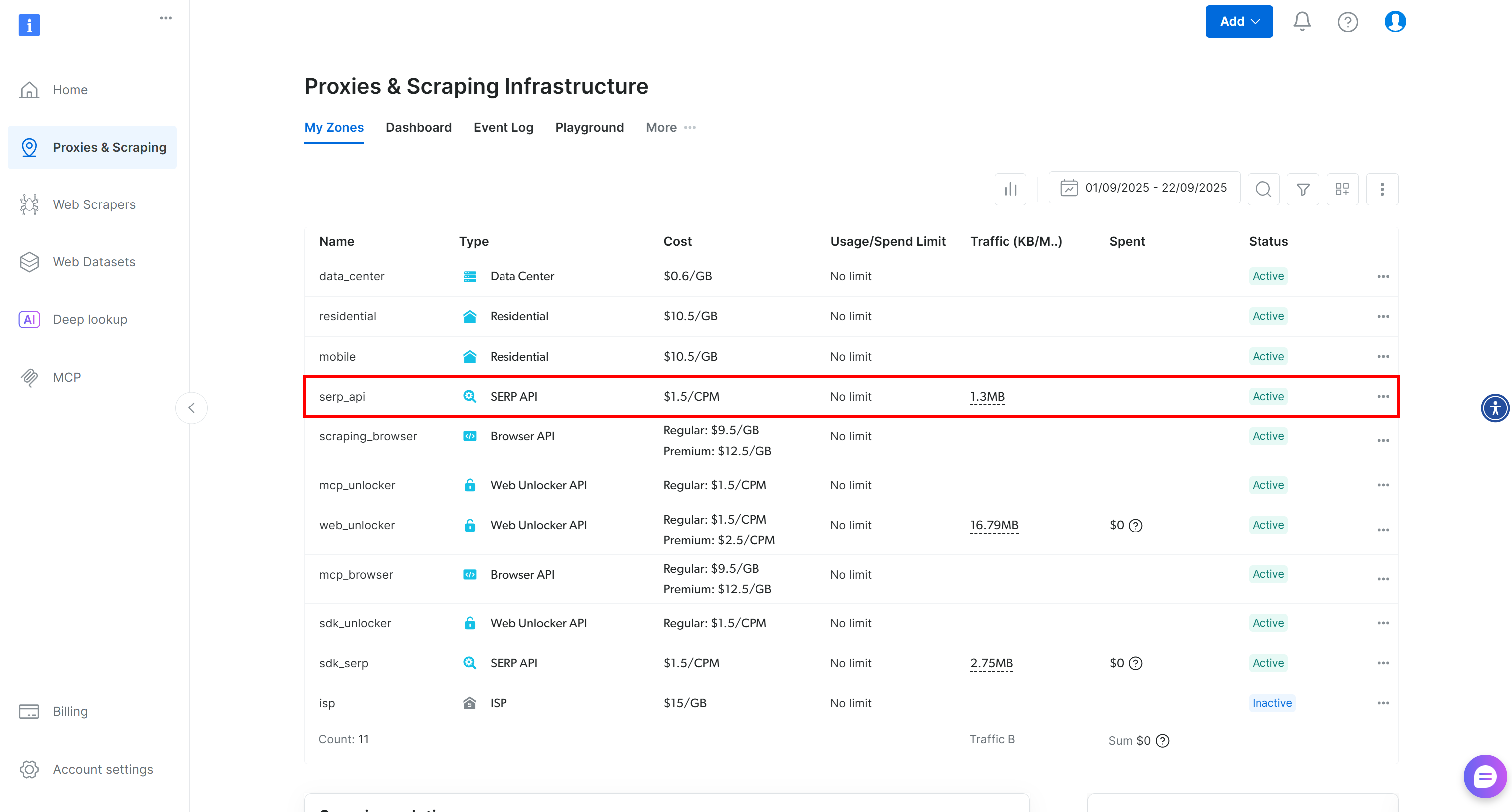
Consultez le tableau « Mes zones », qui répertorie vos produits Bright Data configurés. Si une zone API SERP active existe déjà, vous êtes prêt à commencer. Copiez simplement le nom de la zone (serp_api, dans ce cas), car vous en aurez besoin plus tard.
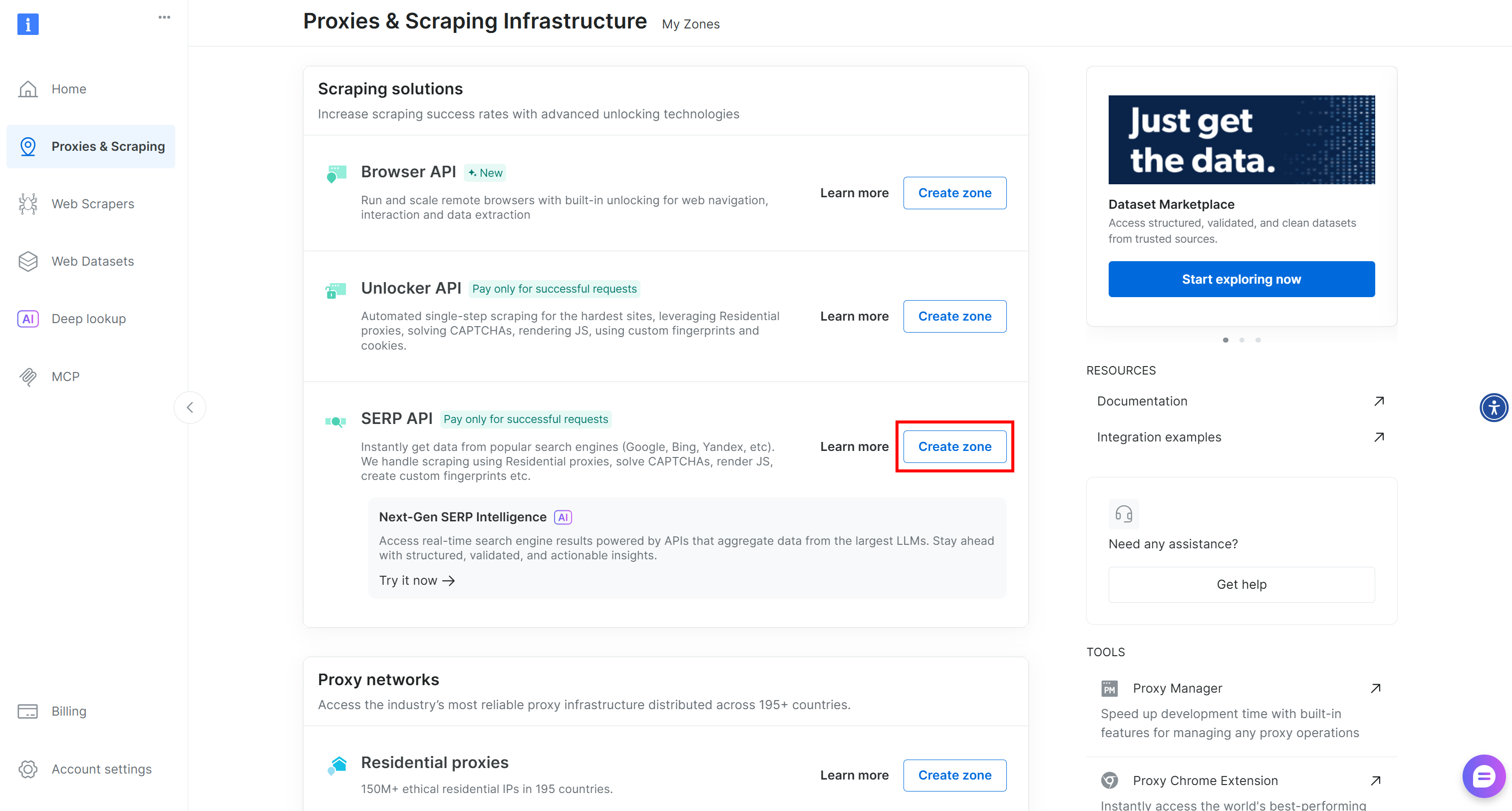
Si aucune zone n’existe, faites défiler vers le bas jusqu’à la section « Scraping Solutions » (Solutions de scraping) et cliquez sur le bouton « Create Zone » (Créer une zone) sur la carte « API SERP » :
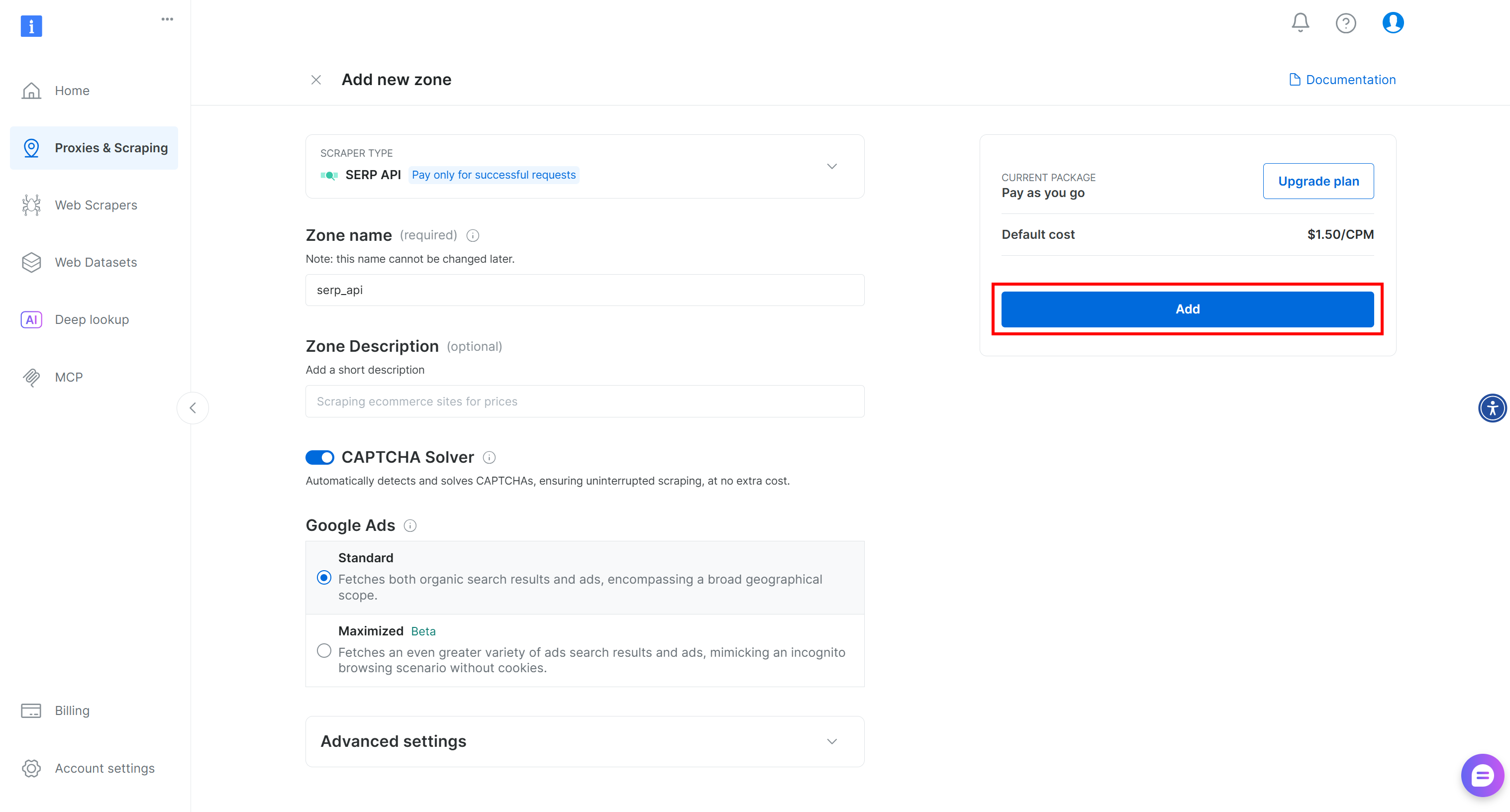
Donnez un nom à votre zone (par exemple, API SERP) et appuyez sur « Ajouter » :
Ensuite, accédez à la page produit de la Zone et assurez-vous qu’elle est activée en basculant le commutateur sur « Active » :
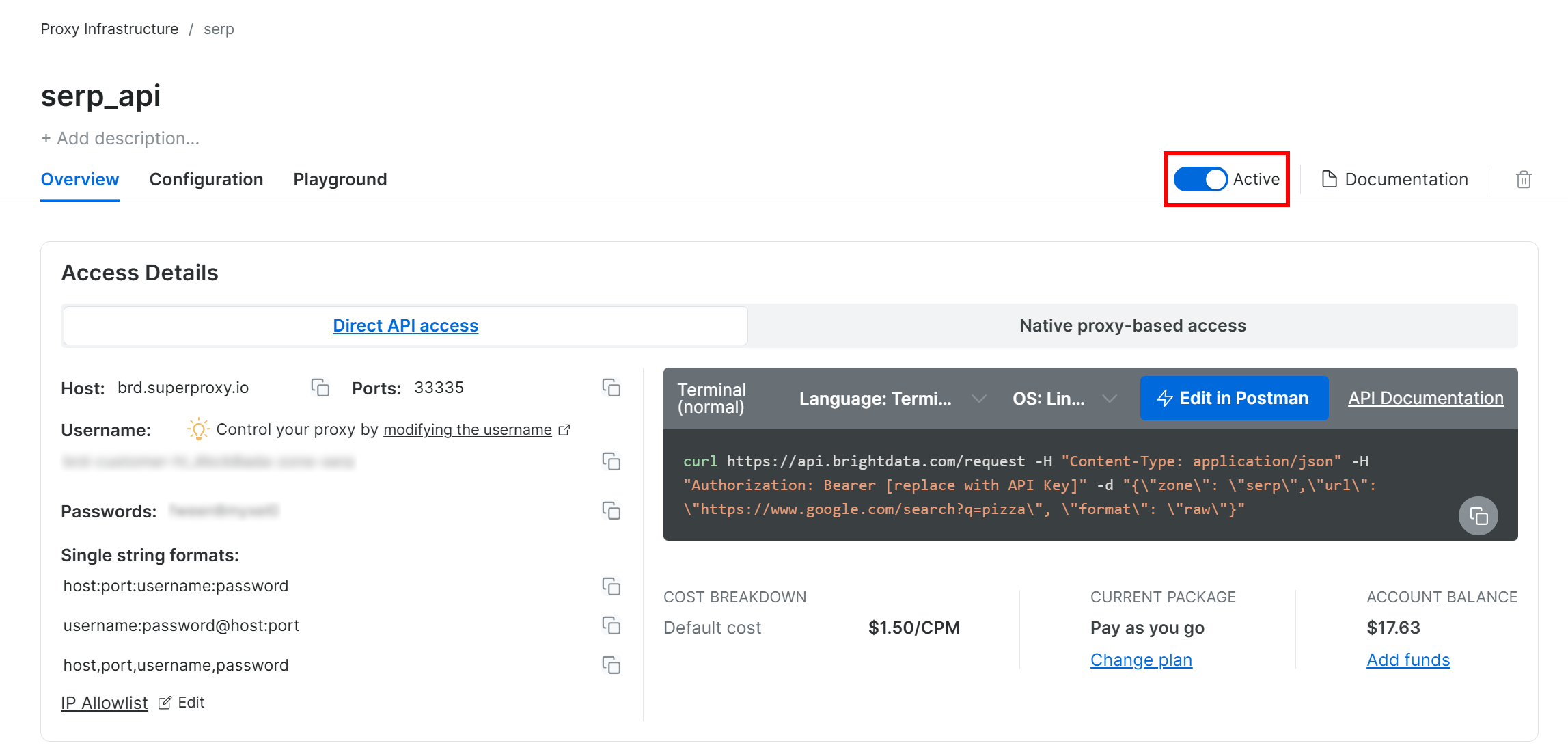
Parfait ! Vous avez maintenant configuré avec succès l’API SERP de Bright Data.
Étape n° 2 : récupérez votre clé API Bright Data
La méthode recommandée pour authentifier les requêtes API SERP consiste à utiliser votre clé API Bright Data. Si vous n’en avez pas encore généré, suivez le guide officiel pour obtenir la vôtre.
Lorsque vous effectuez une requête POST vers l’API SERP, incluez la clé API dans l’en-tête d'autorisation comme suit pour l’authentification :
« Authorization: Bearer <BRIGHT_DATA_API_KEY> »Parfait ! Vous disposez désormais de tous les éléments nécessaires pour appeler l’API SERP de Bright Data dans un script Python (ou via tout autre client HTTP).
Étape n° 3 : appeler l’API SERP
Assemblez le tout et appelez l’API SERP de Bright Data sur la page de recherche DuckDuckGo « agentic rag » à l’aide de cet extrait de code Python :
# pip install requests
import requests
# Identifiants Bright Data (À FAIRE : remplacer par vos valeurs)
bright_data_api_key = "<YOUR_BRIGHT_DATA_API_KEY>"
bright_data_serp_api_zone_name = "<YOUR_SERP_API_ZONE_NAME>"
# Votre page de recherche DuckDuckGo cible
duckduckgo_page_url = "https://duckduckgo.com/?q=agentic+rag"
# Effectuer une requête à l'API SERP de Bright Data
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
},
json={
"zone": bright_data_serp_api_zone_name,
"url": duckduckgo_page_url,
"format": "raw"
})
# Accéder au HTML rendu à partir de la version dynamique de DuckDuckGo
html = response.text
# Logique d'analyse...Pour un exemple plus complet, consultez le « Bright Data API SERP Python Project » sur GitHub.
Notez que, cette fois-ci, l’URL cible peut être la version dynamique de DuckDuckGo (par exemple, https://duckduckgo.com/?q=agentic+rag). L’API SERP gère le rendu JavaScript, s’intègre au réseau Proxy Bright Data pour la rotation des adresses IP et gère d’autres mesures anti-scraping telles que l’empreinte digitale du navigateur et les CAPTCHA. Il n’y aura donc aucun problème lors du scraping des SERP dynamiques.
La variable html contiendra le code HTML entièrement rendu de la page DuckDuckGo. Vérifiez cela en imprimant le code HTML avec :
print(html)Vous obtiendrez quelque chose comme ceci :
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Agentic RAG at DuckDuckGo</title>
<!-- Omission pour plus de concision ... -->
</head>
<body>
<div class="site-wrapper" style="min-height: 825px;">
<div id="content">
<div id="duckassist-answer" class="answer-container">
<DIV class="answer-content-block">
<P class="answer-text">
<SPAN class="highlight">Agentic RAG</SPAN> est une version avancée de Retrieval-Augmented Generation (RAG) qui permet aux agents IA de gérer de manière dynamique la façon dont ils récupèrent et utilisent les informations, améliorant ainsi leur capacité à répondre aux requêtes en temps réel et à s'adapter à des situations changeantes. Cette approche améliore la précision et les capacités de prise de décision des systèmes IA en intégrant le raisonnement à la récupération de données.
</P>
<!-- Omis pour plus de concision ... -->
</DIV>
<!-- Omis pour plus de concision ... -->
</DIV>
<ul class="results-list">
<li class="result-item">
<article class="result-card">
<div <!-- Omission pour plus de concision ... -->
<div class="result-body">
<h2 class="result-title">
<a href="https://www.geeksforgeeks.org/artificial-intelligence/what-is-agentic-rag/" rel="noopener" target="_blank" class="result-link">
<span class="title-text">Qu'est-ce que l'Agentic RAG ? - GeeksforGeeks</span>
</a>
</h2>
<div class="result-snippet-container">
<div class="result-snippet">
<div>
<span class="snippet-text">
<span class="snippet-date">8 septembre 2026</span>
<span>
<b>L'architecture Agentic RAG</b> est conçue pour maximiser l'adaptabilité et l'intelligence en tirant parti d'agents autonomes et d'intégrations d'outils spécialisés. À la base, l'architecture organise des agents de raisonnement, chacun capable de prendre des décisions, de planifier et de récupérer des informations, dans un système coordonné. Voyons les composants clés de l'architecture <b>Agentic RAG</b>, 1.
</span>
</span>
</div>
</div>
</div>
</div>
</article>
</li>
<!-- Autres résultats de recherche ... -->
</ul>
<!-- Omis pour plus de concision ... -->
</div>
<!-- Omis pour plus de concision ... -->
</div>
</body>
</html>Remarque: le code HTML généré peut également inclure le résumé généré par l’IA « Search Assist », car vous avez affaire à la version dynamique de la page.
Maintenant, analysez ce code HTML comme indiqué dans la première approche pour accéder aux données DuckDuckGo dont vous avez besoin !
Approche n° 4 : intégration d’un outil de scraping DuckDuckGo dans un agent IA via MCP
N’oubliez pas que le produit API SERP est également accessible via l’outil search_engine disponible dans le Bright Data Web MCP.
Ce serveur MCP open source fournit un accès IA aux solutions de récupération de données web de Bright Data, y compris les capacités de scraping DuckDuckGo. Plus précisément, l’outil search_engine est disponible dans la version gratuite du Web MCP, ce qui vous permet de l’intégrer à vos agents IA ou à vos flux de travail sans aucun coût.
Pour intégrer le Web MCP à votre solution IA, vous devez généralement installer Node.js localement et disposer d’un fichier de configuration comme celui-ci :
{
"mcpServers": {
"Bright Data Web MCP": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>"
}
}
}
}Par exemple, cette configuration fonctionne avec Claude Code. Découvrez d’autres intégrations dans la documentation.
Grâce à cette intégration, vous pourrez récupérer des données SERP en langage naturel et les utiliser dans vos workflows ou agents alimentés par l’IA.
Conclusion
Dans ce tutoriel, vous avez découvert les quatre méthodes recommandées pour scraper DuckDuckGo :
- Via un scraper personnalisé
- En utilisant DDGS
- Avec l’API de recherche DuckDuckGo
- Grâce à Web MCP
Comme démontré, la seule façon fiable de scraper DuckDuckGo à grande échelle tout en évitant les blocages est d’utiliser une solution de scraping structurée, soutenue par une technologie anti-bot robuste et un vaste réseau de Proxys, comme Bright Data.
Créez un compte Bright Data gratuit et commencez à explorer nos solutions de scraping !