

Dans ce guide, vous apprendrez les éléments suivants :
- Qu’est-ce qu’un Scraper AliExpress et comment fonctionne-t-il ?
- Les types de données que vous pouvez récupérer automatiquement depuis AliExpress
- Comment créer un script de scraping AliExpress à l’aide de Python
C’est parti !
Qu’est-ce qu’un Scraper AliExpress ?
Un Scraper AliExpress récupère automatiquement des données spécifiques à partir des pages AliExpress. Il navigue sur les pages AliExpress en imitant les habitudes de navigation des utilisateurs. Il transforme le contenu des pages web en un format utilisable, tel que CSV ou JSON, et contrôle les interactions telles que la pagination. Son objectif final est de récupérer des informations structurées telles que les images des produits, les détails des produits, les commentaires des clients, les prix, etc.
Si vous souhaitez en savoir plus sur la création de scrapers web, consultez notre guide sur la création d’un bot de scraping.
Données que vous pouvez extraire d’AliExpress : guide étape par étape
AliExpress contient une grande quantité d’informations, telles que :
- Détails des produits: noms, descriptions, images, gammes de prix, informations sur les vendeurs, etc.
- Avis des clients: notes, avis sur les produits, etc.
- Catégories et balises: catégories de produits, balises pertinentes ou étiquettes.
Il est temps d’apprendre à les extraire !
Extraire des données d’AliExpress avec Python
Cette section du tutoriel fournit un guide étape par étape pour créer un Scraper AliExpress.
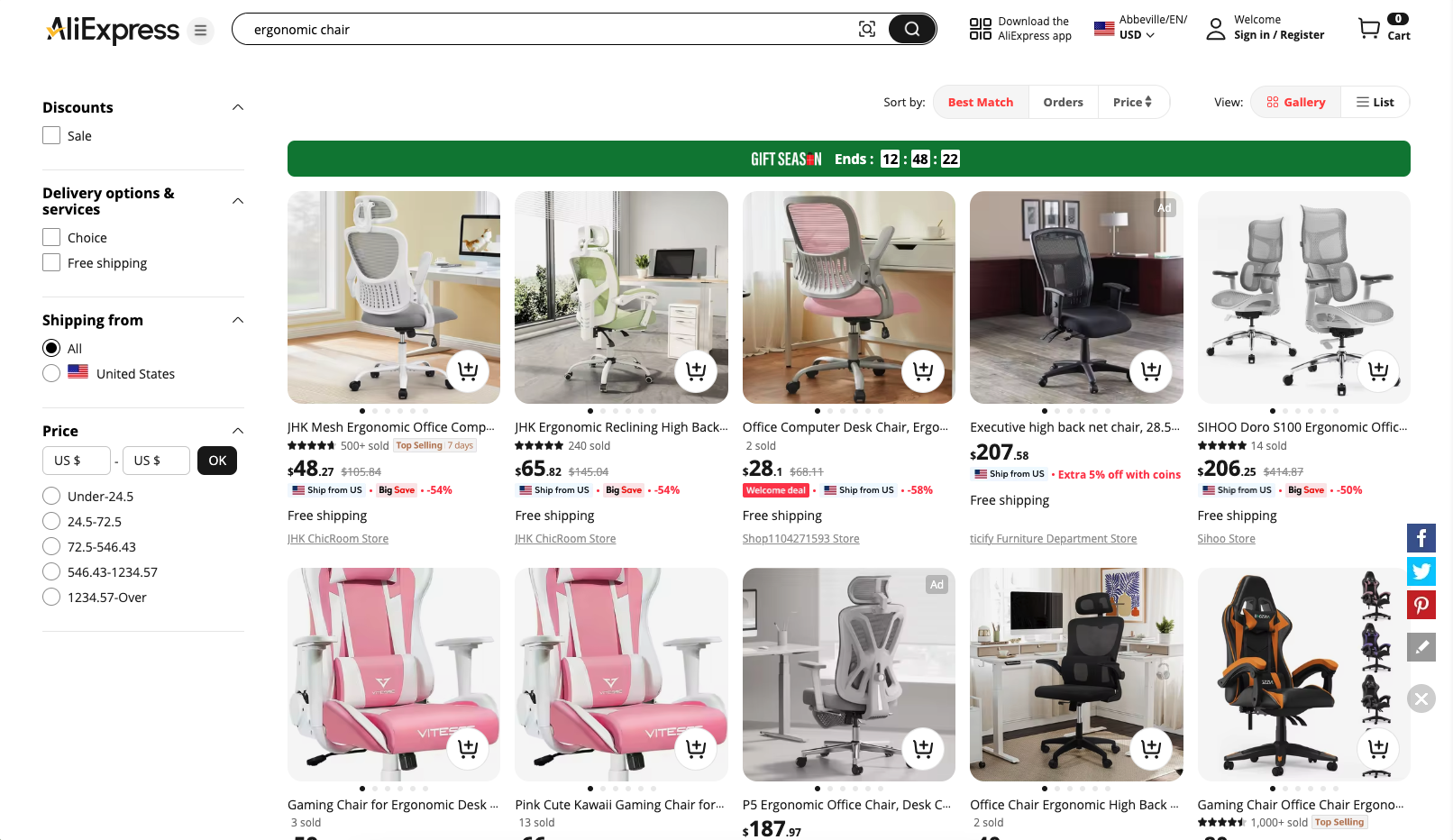
L’objectif est de vous guider dans l’écriture d’un script Python qui extrait automatiquement les informations de la page « chaise ergonomique » d’AliExpress:
Étape n° 1 : configuration du projet
Assurez-vous que Python 3 est installé sur votre ordinateur local. Si ce n’est pas le cas, téléchargez-le à partir de la documentation officielle et suivez l’assistant d’installation pour le configurer.
Ensuite, utilisez la commande ci-dessous pour créer votre répertoire de projet :
mkdir aliexpress-scraper
Ce répertoire contiendra votre code Python.
Entrez le répertoire dans votre terminal et créez un environnement virtuel à l’intérieur :
cd aliexpress-Scraper
python -m venv env
Chargez le dossier du projet dans votre IDE Python préféré, tel que Visual Studio Code avec l’extension Python.
Dans le terminal de votre IDE, activez l’environnement virtuel. Exécutez la commande suivante si vous utilisez macOS ou Linux :
.env/bin/activate
De manière équivalente, sous Windows, utilisez cette commande :
env/Scripts/activate
Parfait !
Dans le répertoire racine de votre projet, créez un fichier Scraper.py. Votre projet devrait maintenant avoir la structure de dossiers suivante :
Parfait ! Votre environnement Python pour le Scraping web d’AliExpress est prêt.
Étape n° 2 : sélectionnez la bibliothèque de scraping
L’objectif actuel est de déterminer si AliExpress utilise des pages dynamiques ou statiques. Accédez à la page AliExpress cible en mode privé ou incognito dans votre navigateur. Ensuite, cliquez avec le bouton droit de la souris sur un espace vide en arrière-plan de la page Web, choisissez l’option « Inspecter », accédez à l’onglet « Réseau », appliquez le filtre « Fetch/XHR » et actualisez la page :
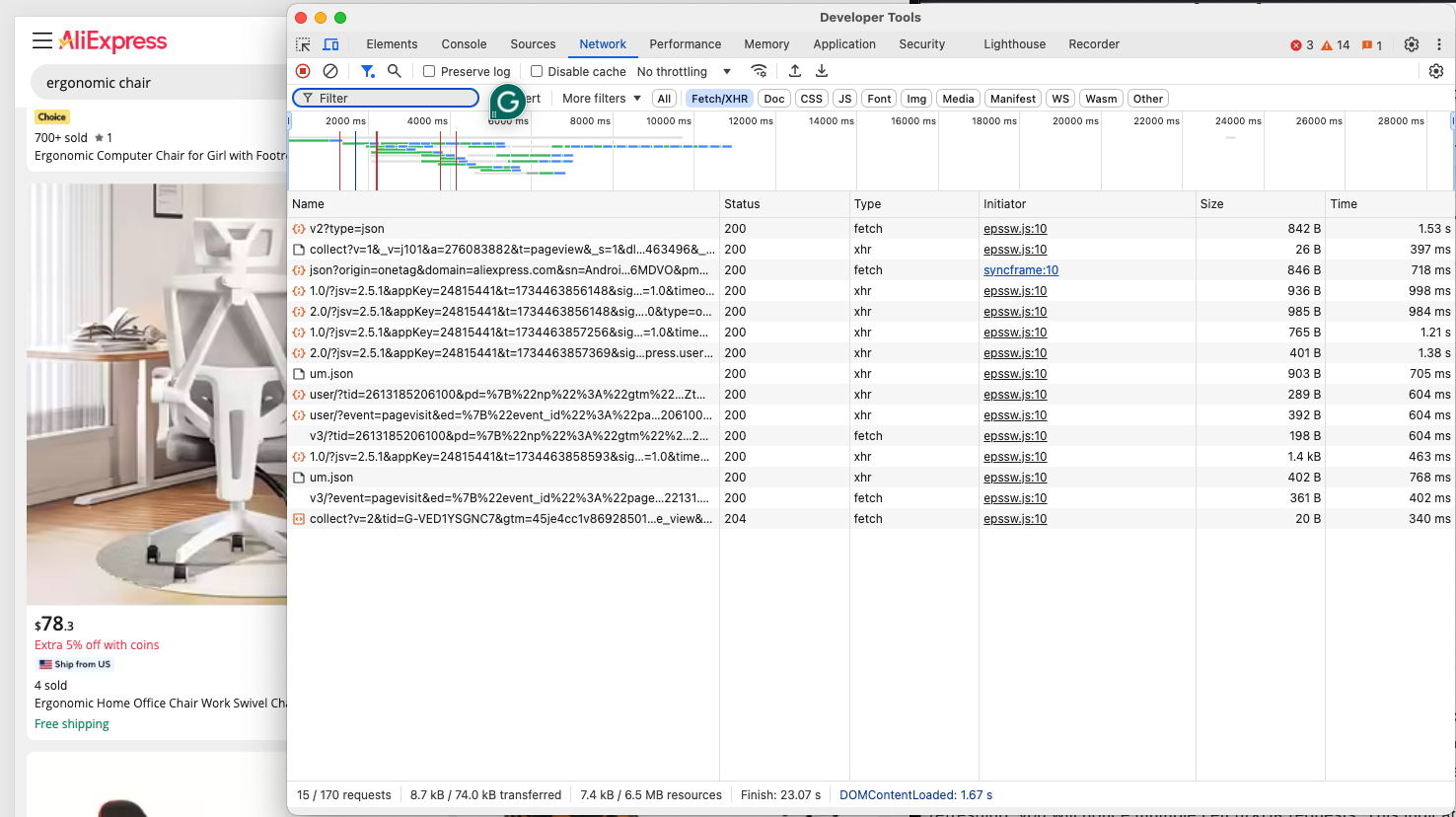
Vérifiez si la page effectue des requêtes dynamiques dans cette section DevTools. Après avoir actualisé la page, vous remarquerez plusieurs requêtes Fetch/XHR. Cela indique que la page utilise des requêtes dynamiques pour charger du contenu supplémentaire. Si vous comparez le DOM de la page au document HTML renvoyé par le serveur, vous verrez également qu’AliExpress utilise le rendu JavaScript.
Pour scraper efficacement AliExpress, vous aurez besoin d’un outil d’automatisation de navigateur tel que Selenium, car la page cible repose sur JavaScript pour le rendu. Notre blog sur le Scraping web avec Selenium est une excellente ressource pour les débutants.
Avec Selenium, vous pouvez manipuler un navigateur web, imiter les interactions des utilisateurs et extraire du contenu rendu en JavaScript. Installez-le et commencez à l’utiliser !
Étape n° 3 : installer et configurer Selenium
Dans l’environnement virtuel activé, installez Selenium à l’aide de cette commande :
pip install -U selenium
Dans le fichier scraper.py, importez WebDriver depuis Selenium et initialisez-le.
from selenium import webdriver
# Initialiser le pilote Chrome
driver = webdriver.Chrome()
# logique de scraping...
# Fermer le pilote
driver.quit()
Un WebDriver est initialisé dans le code ci-dessus pour gérer une instance Chrome. Il convient de noter qu’AliExpress a mis en place des mesures anti-scraping qui pourraient empêcher les navigateurs sans interface graphique d’accéder au site.
Il n’est donc pas conseillé de définir le drapeau--headless. Envisagez plutôt une option alternative telle que Playwright Stealth.
Maintenant que vous êtes entièrement configuré pour commencer à scraper AliExpress, examinons comment se connecter à la page cible.
Étape n° 4 : se connecter à la page cible
Utilisez la méthode get() exposée par l’objet Selenium WebDriver pour visiter la page cible. Le fichier scraper.py devrait maintenant ressembler à ceci :
from selenium import webdriver
# Initialiser le pilote Chrome
driver = webdriver.Chrome()
# URL de la page cible
url = "https://www.aliexpress.com/w/wholesale-ergonomic-chair.html?spm=a2g0o.productlist.search.0"
# Connexion à la page cible
driver.get(url)
# Logique de scraping...
# Fermer le pilote
driver.quit()
Placez un point d’arrêt de débogage sur la dernière ligne et lancez le script avec le débogueur. Le navigateur Chrome contrôlé devrait s’ouvrir automatiquement comme indiqué ci-dessous :
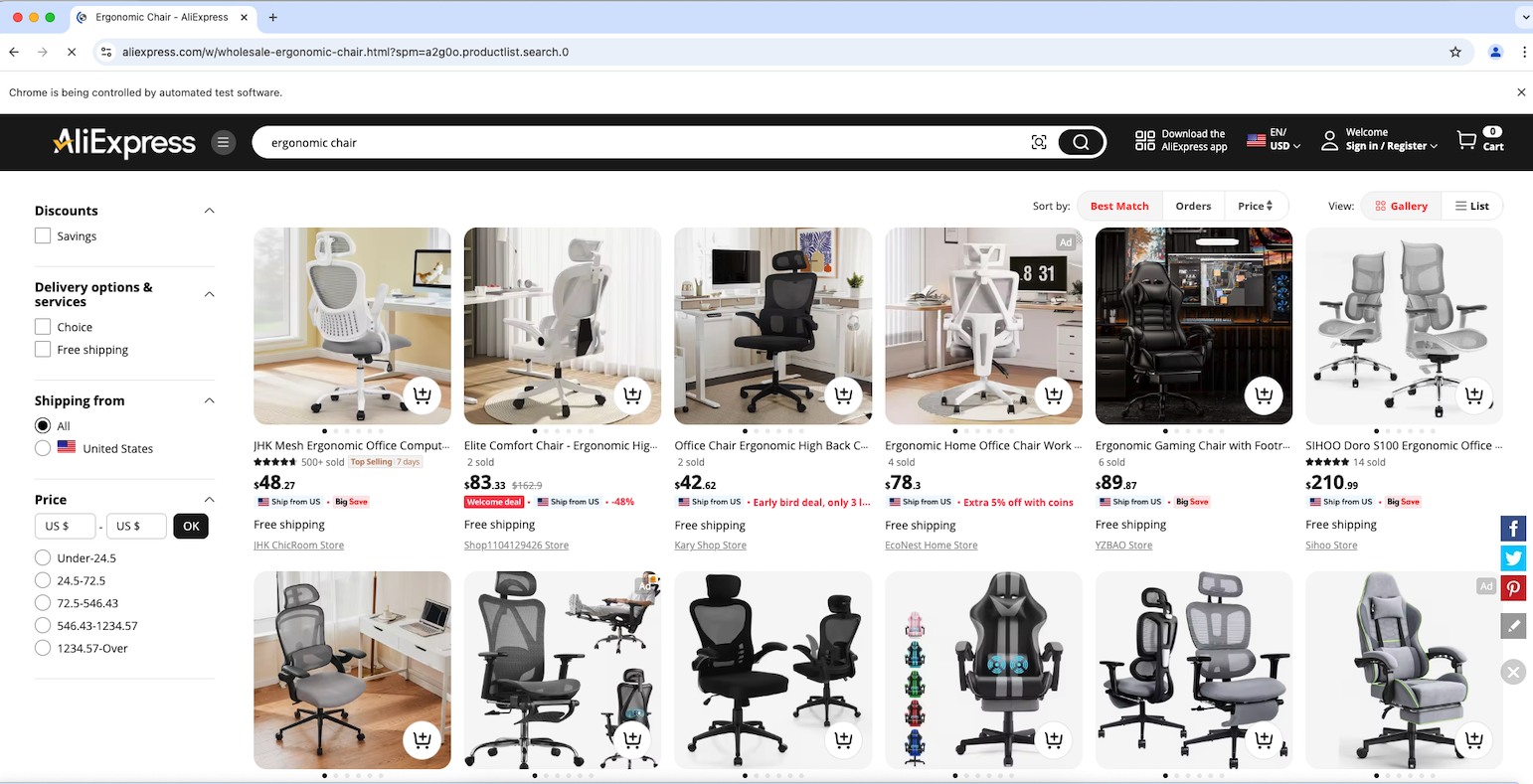
Parfait ! La notification « Chrome est contrôlé par un logiciel de test automatisé » indique que Selenium contrôle correctement Chrome conformément à la configuration.
Étape n° 5 : sélectionner les éléments du produit
Étant donné que la page produit AliExpress contient plusieurs produits, vous devez d’abord initialiser une structure de données pour stocker les données récupérées. À cette fin, un tableau fonctionnera parfaitement :
products = []
Pour vous assurer que votre Scraper continue de fonctionner même lorsque la mise en page du site change, vous devez créer une fonction d’aide qui rend vos sélecteurs plus résistants à ces changements :
def find_element_smart(parent, by_list):
"""Essayer plusieurs sélecteurs jusqu'à ce qu'un élément soit trouvé"""
for by_type, selector in by_list:
try:
element = parent.find_element(by_type, selector)
if element.is_displayed():
return element
except:
continue
return None
La fonction find_element_smart() parcourt une liste de stratégies de sélection by_list pour localiser un élément dans un élément parent donné. Elle essaie chaque paire <by_type, selector> jusqu’à ce qu’elle trouve un élément visible, qu’elle renvoie si elle réussit. Sinon, elle renvoie None si aucun élément correspondant n’est trouvé.
Ensuite, inspectez les éléments HTML des produits sur la page pour comprendre comment les sélectionner, identifier le type de données qu’ils contiennent et déterminer comment extraire ces données.
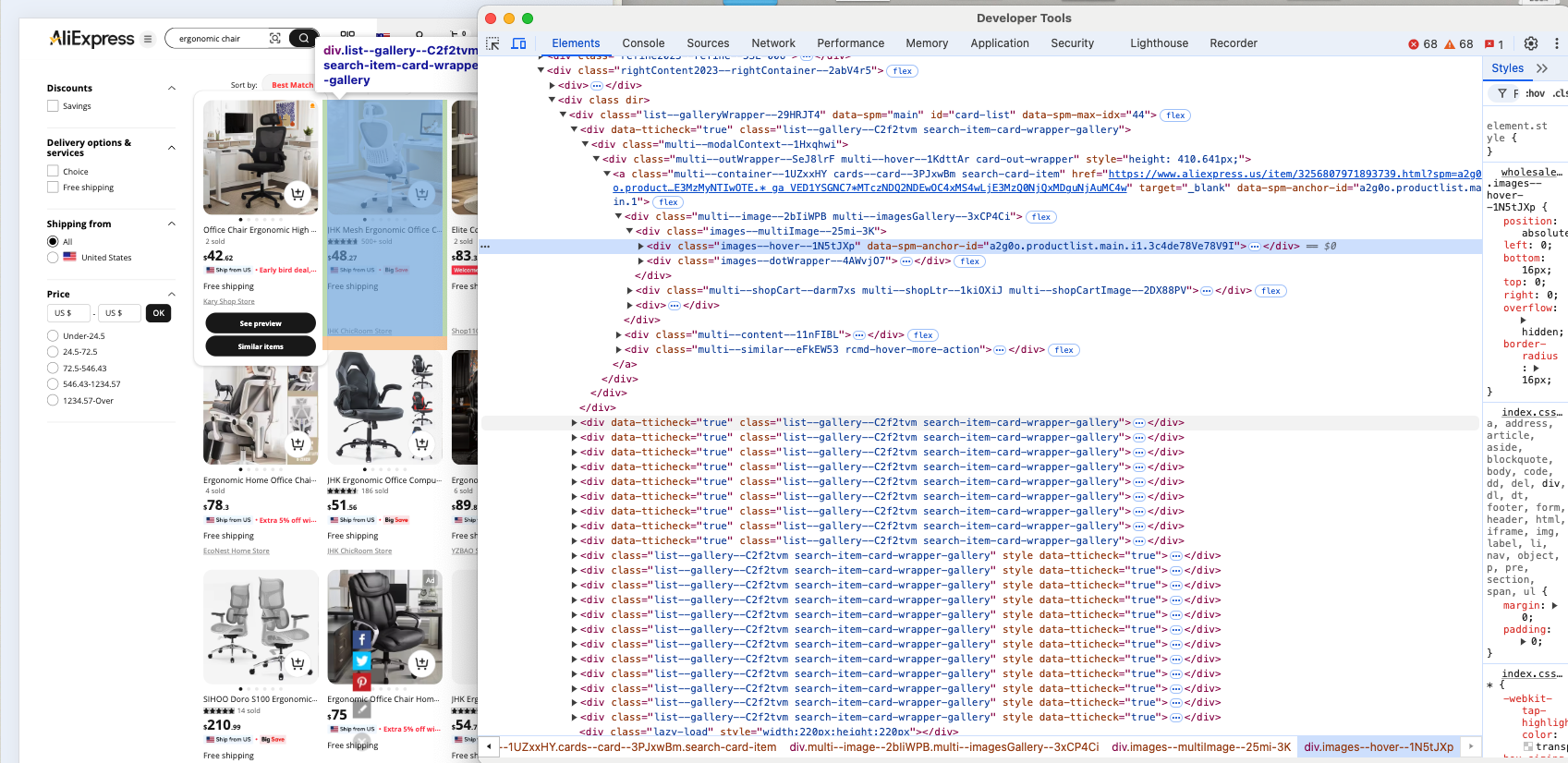
Il est évident que chaque élément de produit est un nœud .list-–gallery—-C2f2tvm.
Notez que list--gallery--C2f2tvm peut changer à tout moment car il contient une chaîne générée aléatoirement. Vous ne devez donc pas vous fier à cette classe pour sélectionner les éléments. Vous devez plutôt commencer par rechercher les produits en fonction de leur structure, comme les éléments div qui contiennent à la fois des images et des liens. Si cela ne fonctionne pas, essayez de rechercher les produits en fonction de leur contenu ou concentrez-vous sur des éléments HTML plus spécifiques.
Implémentez la logique de sélection des produits comme suit :
# Recherchez d'abord les produits à l'aide de modèles structurels, puis utilisez les modèles de classe en dernier recours.
product_selectors = [
(By.XPATH, "//div[.//img and .//a[contains(@href, 'item')]]"),
(By.XPATH, "//div[.//img and .//*[contains(text(), '$')]]"),
(By.CSS_SELECTOR, "div[class*='gallery']")
]
# Attendre et récupérer les produits
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[class*='gallery']")))
products_found = []
for selector_type, selector in product_selectors:
try:
elements = wait.until(EC.presence_of_all_elements_located((selector_type, selector)))
if elements:
products_found = elements
break
except:
continue
Le code ci-dessus applique la stratégie de sélection pour récupérer les éléments de la page à l’aide de sélecteurs CSS génériques.
Incluez l’importation suivante dans votre script Python :
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
Ensuite, introduisez une instance WebDriverWait juste après l’initialisation du WebDriver, mais avant toute interaction avec la page :
wait = WebDriverWait(driver, 20)
Au lieu de rechercher immédiatement des éléments sur une page lors du scraping de sites web dynamiques comme AliExpress, WebDriverWait demande au Scraper d’être patient et d’attendre jusqu’à la durée spécifiée (20 secondes dans ce cas) pour que les éléments apparaissent. Ceci est important car les pages web chargent les éléments à des vitesses différentes, et sans une attente appropriée, le Scraper pourrait récupérer des éléments qui ne sont pas encore chargés, ce qui provoquerait des erreurs.
Vous n’êtes plus qu’à un pas de terminer le scraping d’AliExpress !
Étape n° 6 : extraire les éléments des produits AliExpress
Inspectez un élément de produit pour comprendre sa structure HTML :
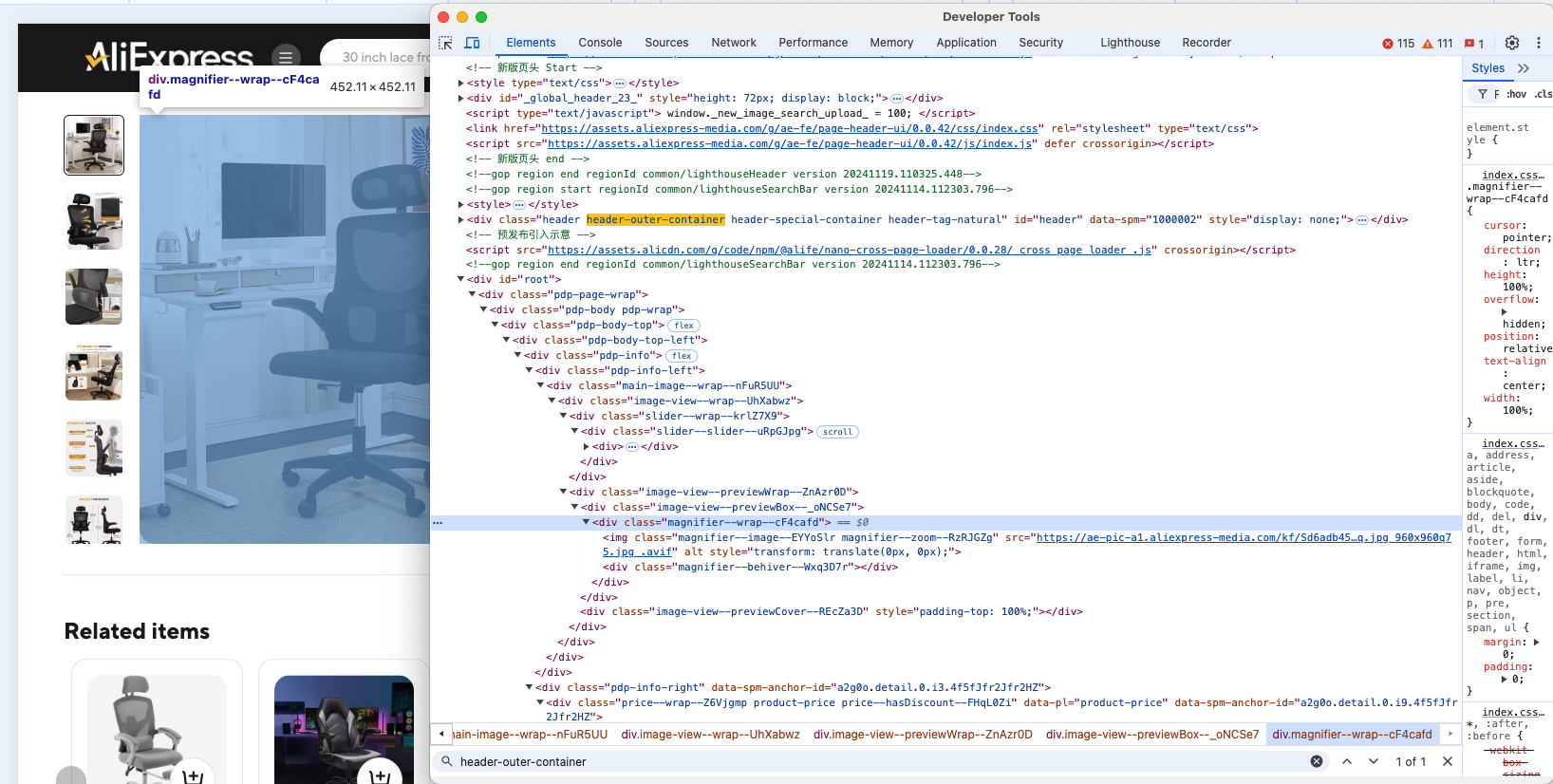
Il est évident que vous pouvez scraper l’image du produit, l’URL, le nom ou le titre, le prix et la remise.
Avant de scraper chaque produit, vérifiez s’il est visible dans la fenêtre d’affichage :
wait.until(EC.visibility_of(product))
Configurez maintenant les sélecteurs pour extraire les données de chaque produit. Au lieu d’utiliser des noms de classe spécifiques qui pourraient ne plus fonctionner, utilisez des modèles tels que ceux-ci :
# Obtenir l'image - rechercher les images du produit par modèles de source
img_element = find_element_smart(product, [
(By.XPATH, ".//img[contains(@src, 'item') or contains(@src, 'product')]"),
(By.CSS_SELECTOR, "img[src*='item']"),
(By.CSS_SELECTOR, "img[class*='image']")
])
# Obtenir l'URL - rechercher les liens vers les produits
url_element = find_element_smart(product, [
(By.CSS_SELECTOR, "a[href*='item']"),
(By.XPATH, ".//a[contains(@href, 'product')]")
])
# Obtenir le titre - rechercher d'abord l'élément de texte le plus long
price_element = find_element_smart(product, [
(By.CSS_SELECTOR, "*[class*='price-sale']"),
(By.CSS_SELECTOR, "*[class*='price']"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
# Obtenir le prix - rechercher les symboles/modèles de devise
price_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '$') or contains(text(), 'US') or contains(text(), 'GHS')]"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
# Essayer d'obtenir une remise si disponible
discount_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '%') or contains(text(), 'OFF')]"),
(By.CSS_SELECTOR, "[class*='discount']")
])
La fonction find_element() renvoie le premier élément qui correspond au sélecteur CSS spécifié. Vous pouvez ensuite utiliser l’attribut text pour extraire son contenu textuel.
Ajoutez les données récupérées au tableau des produits et utilisez-les pour remplir un dictionnaire de produits :
products.append({
"image_url": img_element.get_attribute("src"),
"product_url": url_element.get_attribute("href"),
"product_title": title_element.text.strip(),
"product_price": price_element.text.strip(),
"product_discount": discount_element.text.strip() if discount_element else "N/A"
})
Votre logique d’extraction de données est désormais complète et prête à être utilisée.
Étape n° 7 : exporter les données extraites au format CSV
Dans votre configuration actuelle, les données récupérées sont stockées dans le tableau products. Pour les rendre partageables et accessibles à d’autres, vous devez les exporter dans un format lisible par l’homme, tel qu’un fichier CSV. Voici comment créer et remplir un fichier CSV avec les données récupérées :
# Écrire les données dans un fichier CSV
csv_file_name = "aliexpress_products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
fieldnames = ["image_url", "product_url", "product_title", "product_price", "product_discount"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for product in products:
writer.writerow(product)
Ce code crée un fichier CSV qui fonctionne comme une feuille de calcul : chaque produit dispose de sa propre ligne, et les différentes informations le concernant (image, URL, titre, prix et remise éventuelle) sont réparties dans des colonnes distinctes. Lorsque vous ouvrez le fichier final aliexpress_products.csv, vous voyez toutes les informations sur les produits AliExpress récupérées, présentées de manière claire dans des colonnes.
Enfin, à partir de la bibliothèque standard Python, importez la bibliothèque csv dans votre script :
import csv
Étape n° 8 : Assemblez le tout
Voici à quoi devrait ressembler votre script de scraping final après avoir rassemblé tout le code :
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
def find_element_smart(parent, by_list):
"""Essayer plusieurs sélecteurs jusqu'à ce qu'un élément soit trouvé"""
for by_type, selector in by_list:
try:
element = parent.find_element(by_type, selector)
if element.is_displayed():
return element
except:
continue
return None
# Initialise le pilote
driver = webdriver.Chrome()
wait = WebDriverWait(driver, 20)
# URL cible
url = "https://www.aliexpress.com/w/wholesale-ergonomic-chair.html?spm=a2g0o.productlist.search.0"
driver.get(url)
# Attendre le chargement des produits initiaux
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "div[class*='gallery']")))
# Où stocker les données extraites
products = []
# Rechercher d'abord les produits à l'aide de modèles, puis se rabattre sur les modèles de classe
product_selectors = [
(By.XPATH, "//div[.//img and .//a[contains(@href, 'item')]]"),
(By.XPATH, "//div[.//img and .//*[contains(text(), '$')]]"),
(By.CSS_SELECTOR, "div[class*='gallery']")
]
# Attendre et récupérer les produits
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[class*='gallery']")))
products_found = []
for selector_type, selector in product_selectors:
try:
elements = wait.until(EC.presence_of_all_elements_located((selector_type, selector)))
if elements:
products_found = elements
break
except:
continue
# Itérer sur les produits trouvés et extraire les données
for product in products_found:
# Attendre que le produit soit visible et interactif
wait.until(EC.visibility_of(product))
# Obtenir l'image - rechercher les images du produit par modèles de source
img_element = find_element_smart(product, [
(By.XPATH, ".//img[contains(@src, 'item') or contains(@src, 'product')]"),
(By.CSS_SELECTOR, "img[src*='item']"),
(By.CSS_SELECTOR, "img[class*='image']")
])
# Obtenir l'URL - rechercher les liens vers les produits
url_element = find_element_smart(product, [
(By.CSS_SELECTOR, "a[href*='item']"),
(By.XPATH, ".//a[contains(@href, 'product')]")
])
# Obtenir le titre - rechercher d'abord l'élément de texte le plus long
title_element = find_element_smart(product, [
(By.XPATH, ".//div[string-length(text()) > 20]"),
(By.XPATH, « .//*[contains(@class, 'title')] »),
(By.CSS_SELECTOR, « [class*='name'] »)
])
# Obtenir le prix
price_element = find_element_smart(product, [
(By.CSS_SELECTOR, "*[class*='price-sale']"),
(By.CSS_SELECTOR, "*[class*='price']"),
(By.XPATH, « .//*[contains(@class, 'price')] »)
])
if all([img_element, url_element, title_element, price_element]):
# Obtenir la remise si disponible
discount_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '%') or contains(text(), 'OFF')]"),
(By.CSS_SELECTOR, "[class*='discount']")
])
products.append({
"image_url": img_element.get_attribute("src"),
"product_url": url_element.get_attribute("href"),
"product_title": title_element.text.strip(),
"product_price": price_element.text.strip(),
"product_discount": discount_element.text.strip() if discount_element else "N/A"
})
# Enregistrer les résultats
csv_file_name = "aliexpress_products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["image_url", "product_url", "product_title", "product_price", "product_discount"])
writer.writeheader()
writer.writerows(products)
driver.quit()
Maintenant, lancez le Scraper avec la commande suivante :
python Scraper.py
Le script devrait s’exécuter correctement et le fichier aliexpress_products.csv devrait contenir les données extraites comme indiqué :
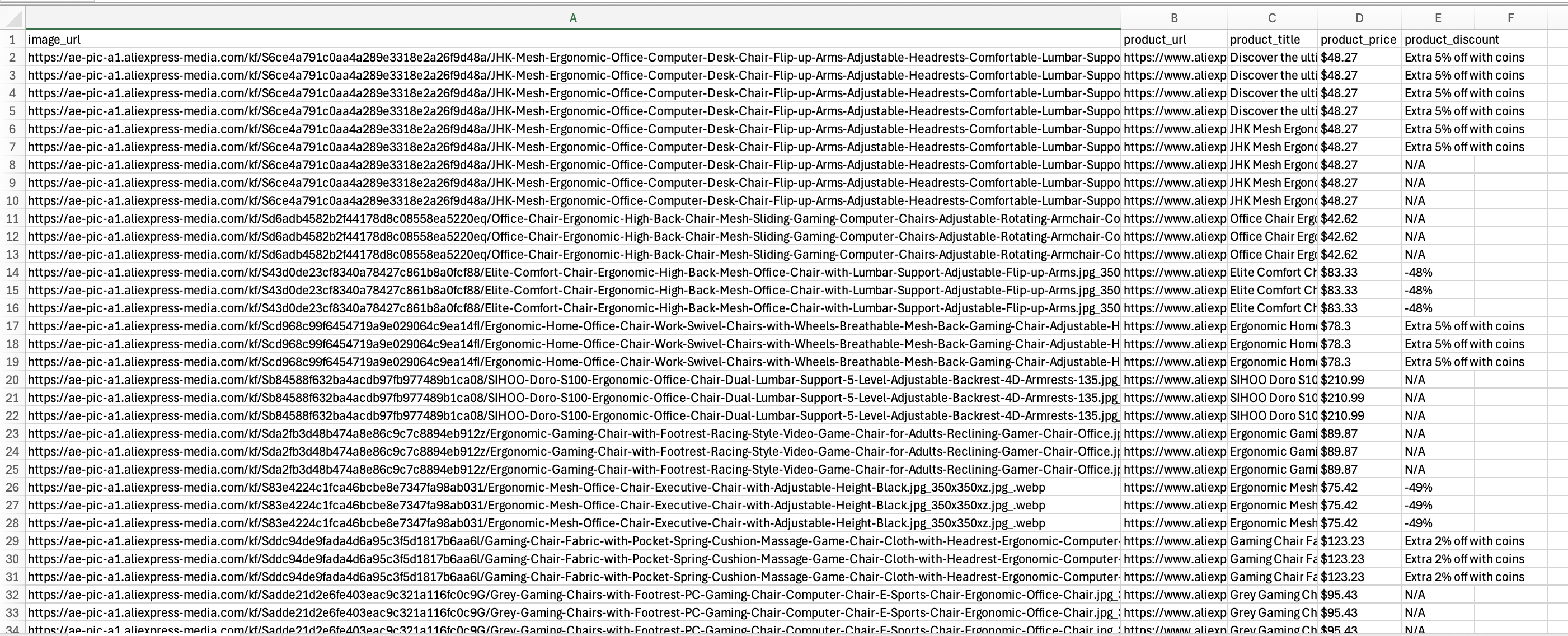
Une fois que vous avez créé un script de scraping fonctionnel, vous pouvez effectuer plusieurs étapes supplémentaires. Il s’agit notamment d’automatiser le processus d’exécution et de mettre en œuvre des optimisations pour garantir que le Scraper continue à fournir des données utiles au fil du temps.
Conclusion
Dans ce guide, vous avez découvert ce qu’est un Scraper AliExpress et les types de données qu’il peut extraire. Vous avez également appris à créer un script Python pour scraper les produits AliExpress avec un minimum de code.
Cependant, le scraping d’AliExpress présente plusieurs défis. La plateforme met en œuvre des protections anti-bot strictes et utilise des fonctionnalités telles que la pagination, qui ajoutent de la complexité au processus de scraping. Développer une solution de scraping Alibaba performante peut s’avérer assez difficile.
Notre API AliExpress Scraper offre une solution spécialisée qui vous permettra d’éliminer ces défis. Grâce à des appels API simples, vous pouvez récupérer de manière transparente les données du site cible tout en réduisant le risque d’être bloqué. Vous avez besoin de données rapidement ?
Vous souhaitez essayer nos API de scraping ou explorer nos Jeux de données? Créez un compte Bright Data dès aujourd’hui et commencez votre essai gratuit !






