

Dans ce tutoriel, vous apprendrez à créer un script Python pour scraper la section « Les gens recherchent aussi » de Google. Elle comprend les questions fréquemment posées liées à votre requête de recherche et contient des informations précieuses.
C’est parti !
Comprendre la fonction « Les gens recherchent aussi » de Google
« Les gens recherchent aussi » (PAA) est une section dans les pages de résultats du moteur de recherche qui propose une liste dynamique de questions liées à leur requête de recherche :

Cette section vous aide à explorer plus en profondeur les sujets liés à votre requête de recherche. Lancée vers 2015, la fonction PAA apparaît dans les résultats de recherche sous la forme d’une série de questions extensibles. Lorsque vous cliquez sur une question, elle se développe pour révéler une brève réponse provenant d’une page Web pertinente, ainsi qu’un lien vers la source :
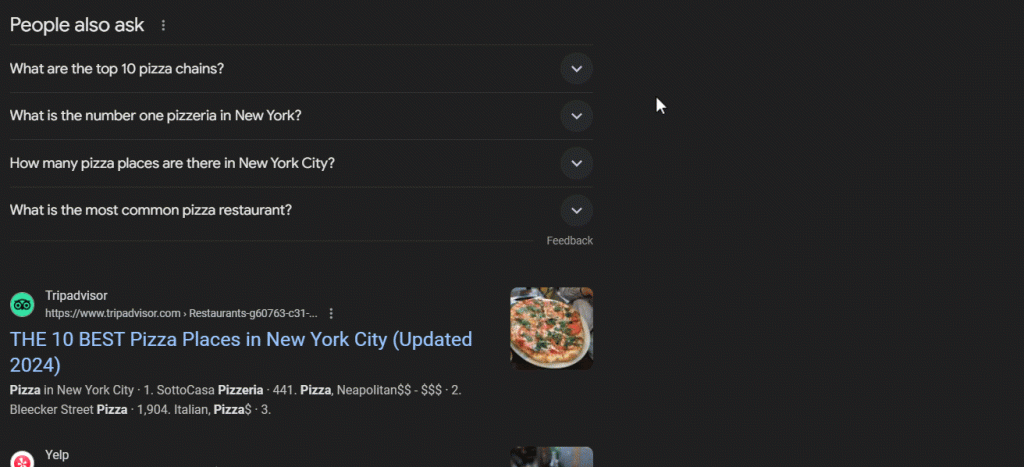
La section « Les gens recherchent aussi » est fréquemment mise à jour et s’adapte en fonction des requêtes des utilisateurs, offrant des informations fraîches et pertinentes. Les nouvelles questions sont chargées dynamiquement lorsque vous développez les menus déroulants.
Scraping de « Les gens recherchent aussi » sur Google : guide étape par étape
Suivez cette section guidée et apprenez à créer un script Python pour scraper « Les gens recherchent aussi » à partir d’une page de recherche Google.
Le but final est de récupérer les données contenues dans chaque question de la section « Les gens recherchent aussi » de la page. Si vous êtes plutôt intéressé par le scraping de Google, suivez notre tutoriel dans Scraping de pages de recherche.
Étape 1 : configuration du projet
Avant de commencer, assurez-vous que Python 3 est installé sur votre machine. Sinon, téléchargez-le, lancez l’exécutable et suivez-en les instructions.
Ensuite, utilisez les commandes ci-dessous pour initialiser un projet Python avec un environnement virtuel :
mkdir people-also-ask-scraper
cd people-also-ask-scraper
python -m venv env
Le répertoire scraper-les-gens-recherchent-aussi représente le dossier du projet de votre scraper PAA en Python.
Chargez le dossier du projet dans votre IDE Python préféré. PyCharm Community Edition ou Visual Studio Code avec l’extension Python sont deux excellentes options gratuites.
Dans le dossier du projet, créez un fichier scraper.py. Il s’agit pour l’instant d’un script vide, mais il contiendra bientôt la logique de scraping :

Dans le terminal de l’IDE, activez l’environnement virtuel. Sous Linux ou macOS, exécutez la commande suivante :
./env/bin/activate
Sous Windows, vous pouvez également exécuter :
env/Scripts/activate
Génial, vous avez maintenant un environnement Python pour votre scraper !
Étape 2 : installez Selenium
Google est une plate-forme qui nécessite une interaction de l’utilisateur. De plus, forger une URL de recherche Google valide peut être difficile. Ainsi, la meilleure façon de travailler avec le moteur de recherche est de passer par un navigateur.
En d’autres termes, pour scraper la section « Les gens recherchent aussi », vous avez besoin d’un outil d’automatisation de navigateur. Si vous n’êtes pas familier avec ce concept, les outils d’automatisation de navigateur vous permettent de rendre et d’interagir avec les pages Web dans un navigateur contrôlable. L’une des meilleures options de Python est Selenium !
Installez Selenium en exécutant la commande ci-dessous dans un environnement virtuel Python activé :
pip install selenium
Le package pip selenium sera ajouté aux dépendances de votre projet. Cela peut prendre un certain temps, soyez patient.
Pour plus de détails sur l’utilisation de cet outil, lisez notre guide sur le web scraping avec Selenium.
Merveilleux, vous avez maintenant tout ce dont vous avez besoin pour commencer à scraper des pages Google !
Étape 3 : accédez à la page d’accueil Google
Importez Selenium dans scraper.py et initialisez un objet WebDriver pour contrôler une instance Chrome en mode headless :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
Le snippet ci-dessus crée une instance Chrome WebDriver, l’objet qui permet de contrôler par programmation une fenêtre Chrome. L’option --headless configure Chrome pour qu’il s’exécute en mode headless. Pour le débogage, commentez cette ligne afin que vous puissiez observer les actions du script automatisé en temps réel.
Puis utilisez la méthode get() pour vous connecter à la page d’accueil de Google :
driver.get("https://google.com/")
N’oubliez pas de libérer les ressources du pilote à la fin du script :
driver.quit()
Réunissez tout cela, et vous obtiendrez :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google home page
driver.get("https://google.com/")
# scraping logic...
# close the browser and free up the resources
driver.quit()
Fantastique, tout est prêt pour scraper des sites Web dynamiques !
Étape 4 : gérez la boîte de dialogue des cookies dans le cadre du RGPD
Remarque : si vous n’êtes pas situé dans l’UE (Union européenne), vous pouvez sauter cette étape.
Exécutez le script scraper.py en mode headed. Ceci ouvrira brièvement une fenêtre de navigateur Chrome affichant une page Google avant que la commande quit() ne la ferme. Si vous êtes dans l’UE, voici ce que vous verrez :
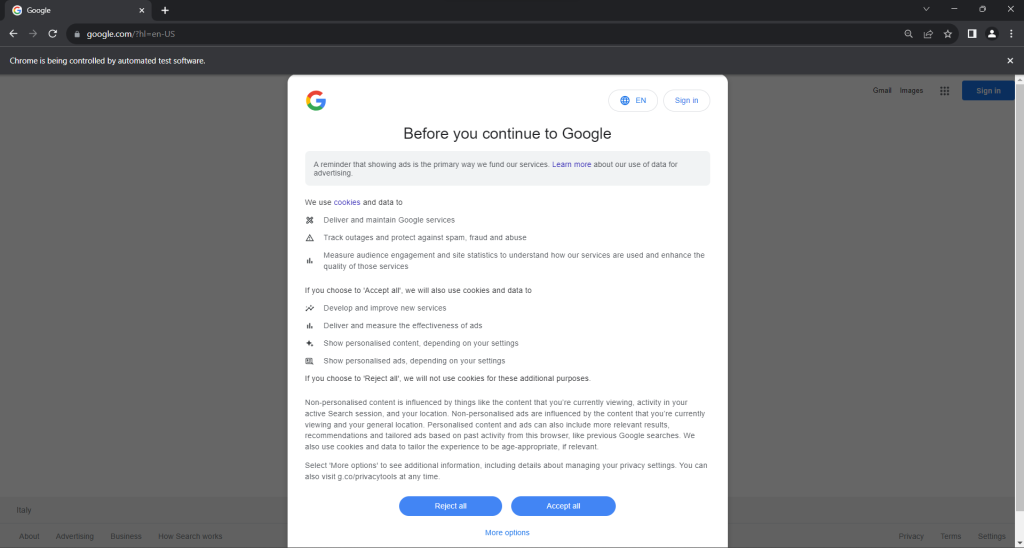
Le message « Chrome est contrôlé par un logiciel de test automatisé » signifie que Selenium contrôle Chrome comme souhaité.
Les utilisateurs de l’UE voient apparaître une boîte de dialogue relative à la politique en matière de cookies conformément au RGPD. Si c’est votre cas, vous devez la traiter si vous souhaitez interagir avec la page sous-jacente. Sinon, vous pouvez passer à l’étape 5.
Ouvrez une page Google en mode navigation privée et inspectez la boîte de dialogue relative aux cookies et au RGPD. Cliquez dessus avec le bouton droit de la souris et choisissez l’option « Inspecter » :
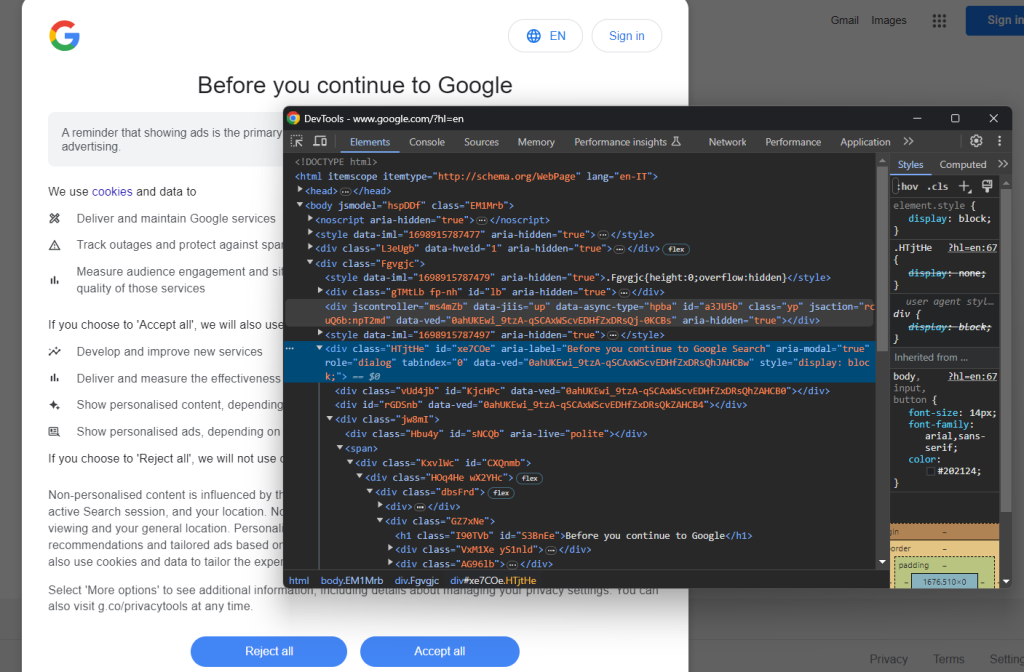
Notez que vous pouvez localiser la boîte de dialogue de l’élément HTML avec :
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
find_element() est une méthode fournie par Selenium pour localiser des éléments HTML sur la page via différentes stratégies. Dans ce cas, nous avons utilisé un sélecteur CSS.
N’oubliez pas d’importer By comme suit :
from selenium.webdriver.common.by import By
Maintenant, concentrez-vous sur le bouton « Accepter tout » :
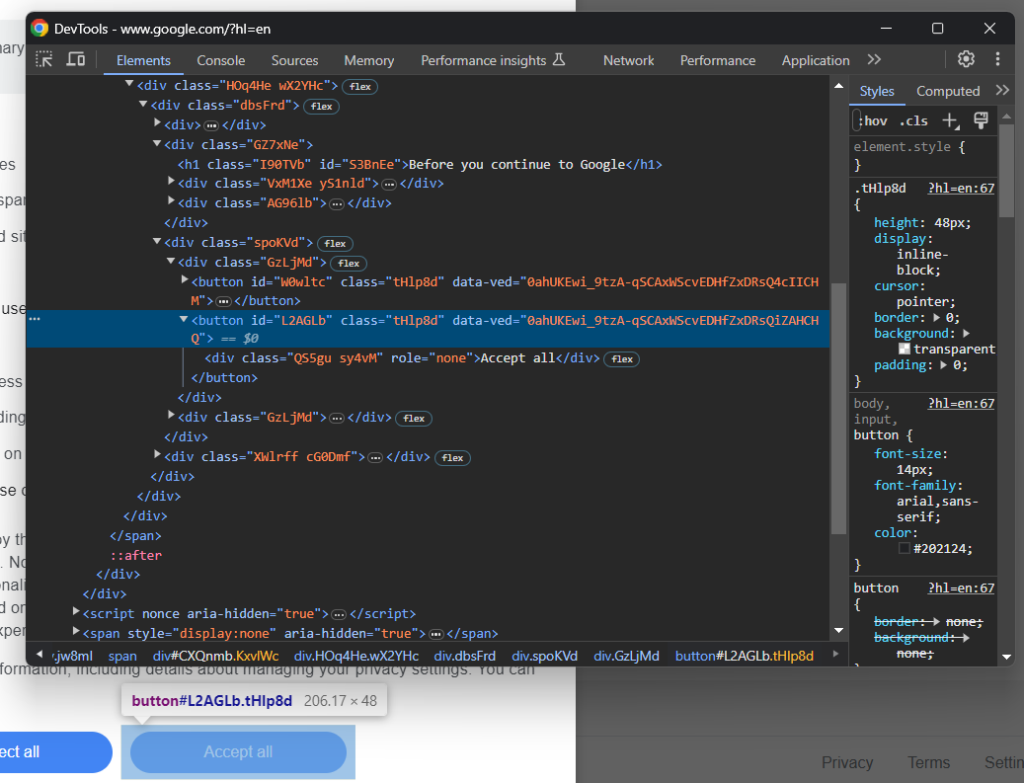
Comme vous pouvez le voir, il n’y a pas de moyen facile de le sélectionner, car sa classe CSS semble être générée de manière aléatoire. Vous pouvez donc le récupérer en utilisant une expression XPath qui cible son contenu :
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
Cette instruction localisera le premier bouton de la boîte de dialogue dont le texte contient la chaîne « Accept ». Pour plus d’informations, lisez notre guide XPath et sélecteur CSS.
Voici comment tout s’intègre pour gérer la boîte de dialogue facultative des cookies Google :
try:
# select the dialog and accept the cookie policy
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
if accept_button is not None:
accept_button.click()
except NoSuchElementException:
print("Cookie dialog not present")
L’instruction click() clique sur le bouton « Accepter tout » pour fermer la boîte de dialogue et permettre l’interaction de l’utilisateur. Si la boîte de dialogue de la politique en matière de cookies n’est pas présente, une NoSuchElementException sera lancée à la place. Le script l’interceptera et continuera.
N’oubliez pas d’importer la NoSuchElementException :
from selenium.common import NoSuchElementException
Bravo ! Vous êtes prêt à accéder à la page avec la section « Les gens recherchent aussi ».
Étape 5 : envoyez le formulaire de recherche
Accédez à la page d’accueil Google dans votre navigateur et inspectez le formulaire de recherche. Cliquez dessus avec le bouton droit de la souris et choisissez l’option « Inspecter » :
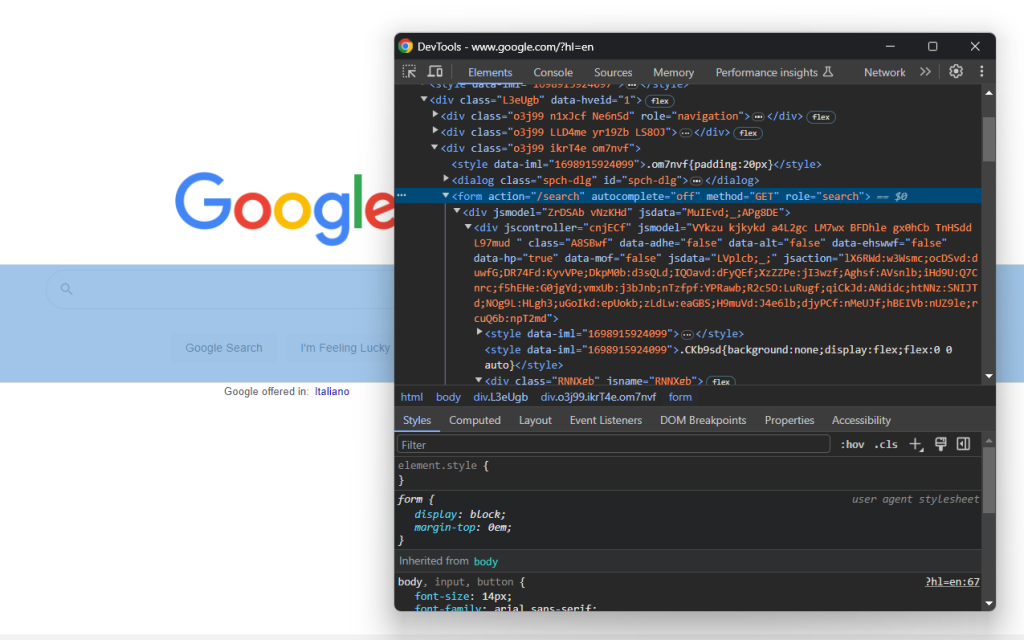
Cet élément n’a pas de classe CSS, mais vous pouvez le sélectionner via son attribut action :
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
Si vous avez ignoré l’étape 4, importez By avec :
from selenium.webdriver.common.by import By
Développez le code HTML du formulaire et examinez la zone de texte de recherche :
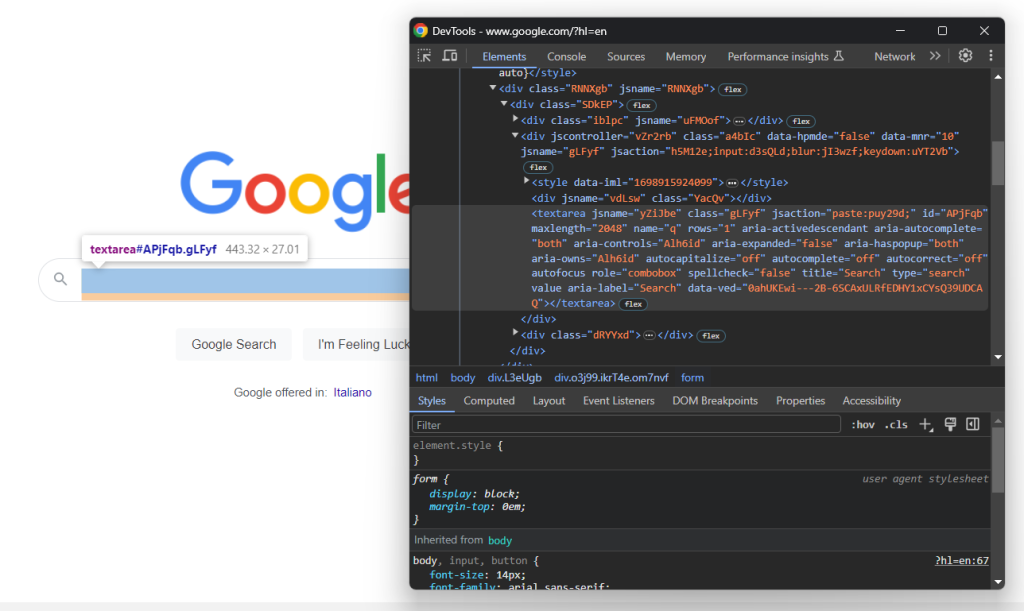
La classe CSS de ce nœud semble être générée de manière aléatoire. En conséquence, sélectionnez-le via son attribut aria-label. Ensuite, utilisez la méthode send_keys() pour saisir la requête de recherche cible :
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
search_query = "Bright Data"
search_textarea.send_keys(search_query)
Dans cet exemple, la requête de recherche est « Bright Data », mais toute autre recherche est possible.
Envoyez le formulaire pour déclencher un changement de page :
search_form.submit()
Génial ! Le navigateur contrôlé va maintenant être redirigé vers la page Google contenant la section « Les gens recherchent aussi ».
Si vous exécutez le script en mode headed, voici ce que vous devriez voir avant que le navigateur se ferme :
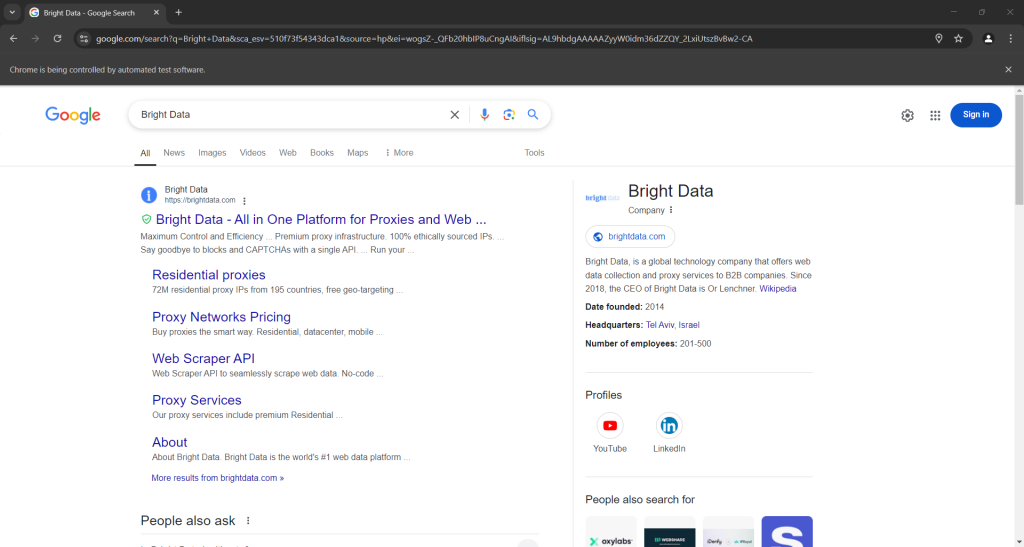
Notez la section « Les gens recherchent aussi » en bas de la capture d’écran ci-dessus.
Étape 6 : sélectionnez le nœud « Les gens recherchent aussi »
Inspectez l’élément HTML « Les gens recherchent aussi » :
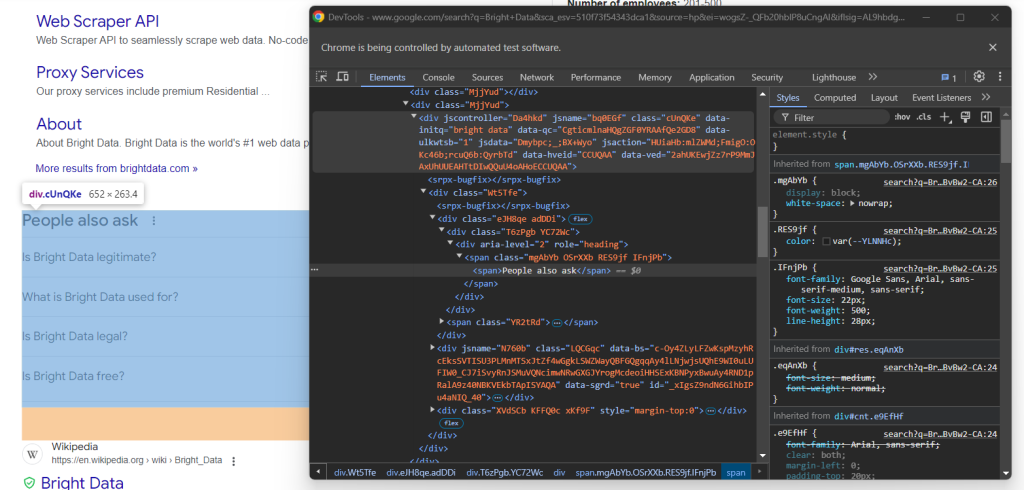
Encore une fois, il n’y a pas de moyen facile de le sélectionner. Cette fois, ce que vous pouvez faire est de récupérer l’élément <div> avec les attributs jscontroller, jsname et jsaction qui contient un div avec role=heading avec le texte « Les gens recherchent aussi » :
people_also_ask_div = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((
By.XPATH, "//div[@jscontroller and @jsname and @jsaction][.//div[@role='heading' and contains(., 'People also ask')]]"
))
)
WebDriverWait est une classe spéciale Selenium qui interrompt le script jusqu’à ce qu’une condition spécifique soit remplie sur la page. Au-dessus, elle attend jusqu’à 5 secondes que l’élément HTML souhaité apparaisse. Ceci est nécessaire pour laisser la page se charger complètement après avoir soumis le formulaire.
L’expression XPath utilisée dans presence_of_element_located() est complexe, mais décrit avec précision les critères nécessaires pour sélectionner l’élément « Les gens recherchent aussi ».
N’oubliez pas d’ajouter les importations requises :
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
Il est temps de scraper la section « Les gens recherchent aussi » de Google !
Étape 7 : scraper la section « Les gens recherchent aussi »
Tout d’abord, initialisez une structure de données dans laquelle stocker les informations scrapées :
people_also_ask_questions = []
Cela doit être un tableau, car la section « Les gens recherchent aussi » contient plusieurs questions.
Maintenant, inspectez la première liste déroulante de questions dans le nœud « Les gens recherchent aussi » :
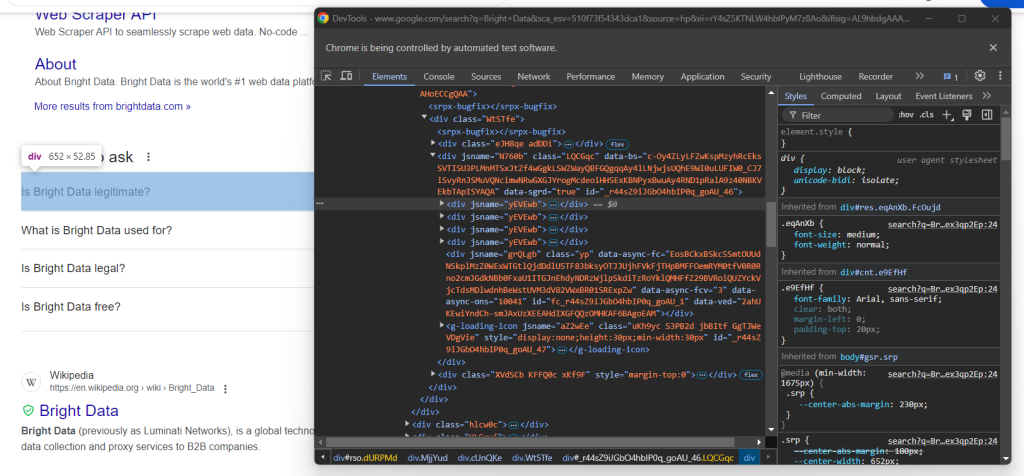
Ici, vous pouvez voir que les éléments qui vous intéressent sont les enfants de data-sgrd="true" <div> dans l’élément « Les gens recherchent aussi » avec seulement l’attribut jsname. Les deux derniers enfants sont utilisés par Google comme espaces réservés et sont remplis dynamiquement lorsque vous ouvrez des listes déroulantes.
Sélectionnez les listes déroulantes de questions avec la logique suivante :
people_also_ask_inner_div = people_also_ask_div.find_element(By.CSS_SELECTOR, "[data-sgrd='true']")
people_also_ask_inner_div_children = people_also_ask_inner_div.find_elements(By.XPATH, "./*")
for child in people_also_ask_inner_div_children:
# if the current element is a question dropdown
if child.get_attribute("jsname") is not None and child.get_attribute("class") == '':
# scraping logic...
Cliquez sur l’élément pour le développer :
child.click()
Ensuite, concentrez-vous sur le contenu des éléments de question :
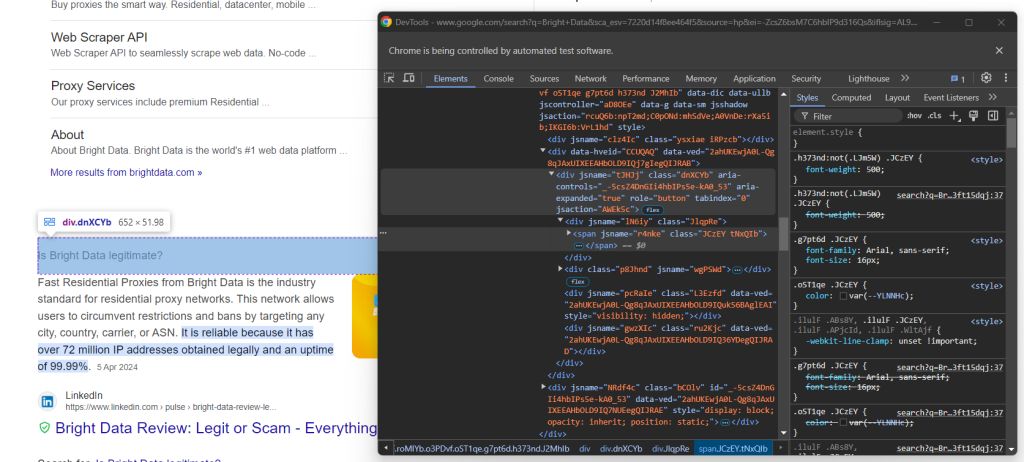
Notez que la question est contenue dans le <span> à l’intérieur du nœud aria-expanded="true". Scrapez-le comme suit :
question_title_element = child.find_element(By.CSS_SELECTOR, "[aria-expanded='true'] span")
question_title = question_title_element.text
Examinez ensuite l’élément de réponse :
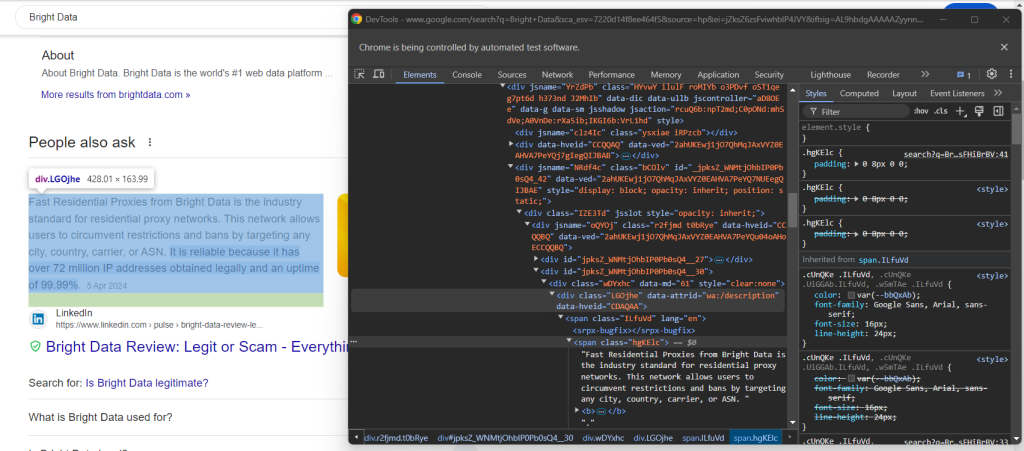
Notez comment vous pouvez le récupérer en recueillant le texte dans le nœud <span> avec l’attribut lang à l’intérieur de l’élément data-attrid="wa:/description" :
question_description_element = child.find_element(By.CSS_SELECTOR, "[data-attrid='wa:/description'] span[lang]")
question_description = question_description_element.text
Examinez ensuite l’image facultative dans la zone de réponse :
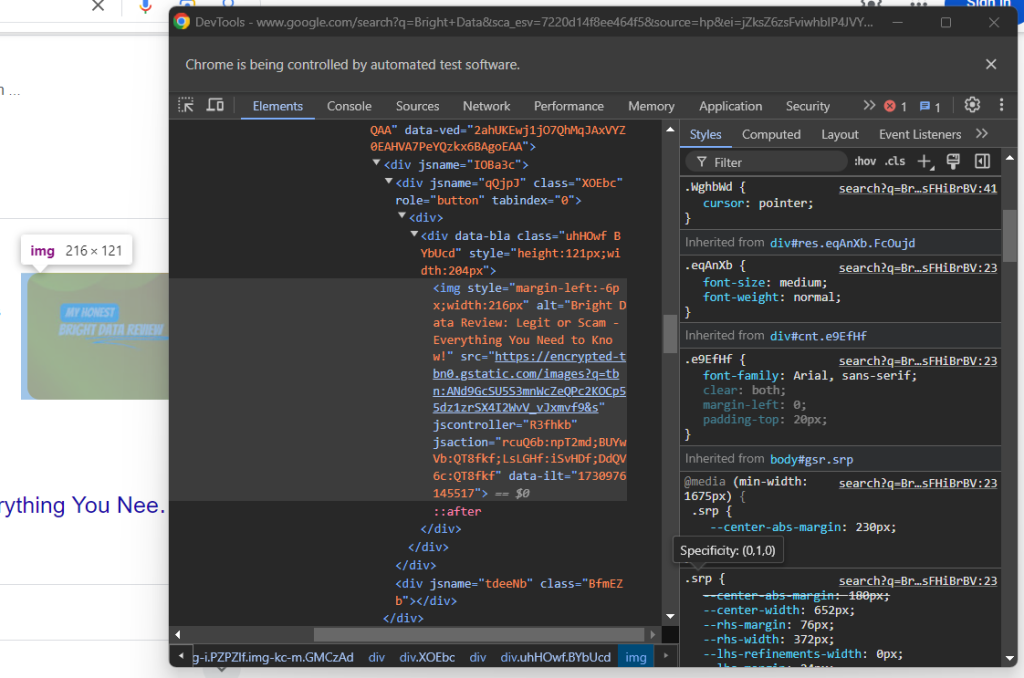
Vous pouvez obtenir son URL en accédant à l’attribut src depuis l’élément <img> avec l’attribut data-ilt :
try:
question_image_element = child.find_element(By.CSS_SELECTOR, "img[data-ilt]")
question_image = question_image_element.get_attribute("src")
except NoSuchElementException:
question_image = None
Comme l’élément image est optionnel, vous devez envelopper le code ci-dessus avec un bloc try ... except. Si le nœud n’est pas présent dans la question actuelle, find_element() déclenchera une NoSuchElementException. Le code va l’intercepter et continuer, dans ce cas,
Si vous avez ignoré l’étape 4, importez l’exception :
from selenium.common import NoSuchElementException
Enfin, inspectez la section source :
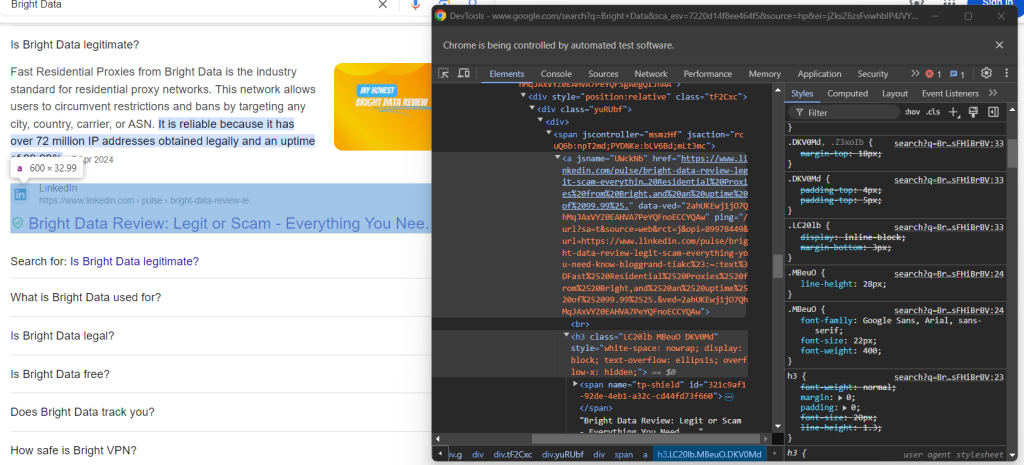
Vous pouvez obtenir l’URL de la source en sélectionnant le parent <a> de l’élément <h3> :
question_source_element = child.find_element(By.XPATH, ".//h3/ancestor::a")
question_source = question_source_element.get_attribute("href")
Utilisez les données scrapées pour remplir un nouvel objet et l’ajouter au tableau people_also_ask_questions :
people_also_ask_question = {
"title": question_title,
"description": question_description,
"image": question_image,
"source": question_source
}
people_also_ask_questions.append(people_also_ask_question)
Parfait ! Vous venez de scraper la section « Les gens recherchent aussi » d’une page Google.
Étape 8 : exportez les données scrapées au format CSV
Si vous imprimez people_also_ask_questions, vous verrez le résultat suivant :
[{'title': 'Is Bright Data legitimate?', 'description': 'Fast Residential Proxies from Bright Data is the industry standard for residential proxy networks. This network allows users to circumvent restrictions and bans by targeting any city, country, carrier, or ASN. It is reliable because it has 400M+ monthly IP addresses obtained legally and an uptime of 99.99%.', 'image': 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSU5S3mnWcZeQPc2KOCp55dz1zrSX4I2WvV_vJxmvf9&s', 'source': 'https://www.linkedin.com/pulse/bright-data-review-legit-scam-everything-you-need-know-bloggrand-tiakc#:~:text=Fast%20Residential%20Proxies%20from%20Bright,and%20an%20uptime%20of%2099.99%25.'}, {'title': 'What is Bright Data used for?', 'description': "Bright Data is the world's #1 web data platform, supporting the public data needs of over 22,000 organizations in nearly every industry. Using our solutions, organizations research, monitor, and analyze web data to make better decisions.", 'image': None, 'source': "https://brightdata.com/about#:~:text=Bright%20Data%20is%20the%20world's,data%20to%20make%20better%20decisions."}, {'title': 'Is Bright Data legal?', 'description': "Bright Data's platform, technology, and network (collectively, “Services”) are meant for legitimate and legal purposes only and are subject to the Bright Data Master Service Agreement.", 'image': None, 'source': "https://brightdata.com/acceptable-use-policy#:~:text=Bright%20Data's%20platform%2C%20technology%2C%20and,Bright%20Data%20Master%20Service%20Agreement."}, {'title': 'Is Bright Data free?', 'description': 'Bright Data offers four free proxy solutions to meet various needs: Anonymous Proxies: These top-performing anonymous proxies let you access websites anonymously, routing traffic through a vast Residential IP Network of 400M+ monthly IPs, concealing your true location.', 'image': None, 'source': 'https://brightdata.com/solutions/free-proxies#:~:text=Bright%20Data%20offers%20four%20free,IPs%2C%20concealing%20your%20true%20location.'}]
Bien sûr, c’est formidable, mais ce serait beaucoup mieux si c’était dans un format que vous pouvez facilement partager avec les autres membres de l’équipe. La solution est d’exporter people_also_ask_questions vers un fichier CSV !
Importez le package csv depuis la bibliothèque standard Python :
import csv
Ensuite, utilisez-le pour remplir un fichier CSV de sortie avec vos données de pages de résultats de recherche :
csv_file = "people_also_ask.csv"
header = ["title", "description", "image", "source"]
with open(csv_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(people_also_ask_questions)
Enfin ! Votre script de scraping « Les gens recherchent aussi » est terminé.
Étape 9 : pour terminer
Votre script final scraper.py devrait contenir le code suivant :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google home page
driver.get("https://google.com/")
# deal with the optional Google cookie GDPR dialog
try:
# select the dialog and accept the cookie policy
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
if accept_button is not None:
accept_button.click()
except NoSuchElementException:
print("Cookie dialog not present")
# select the search form
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# select the textarea and fill it out
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
search_query = "Bright Data"
search_textarea.send_keys(search_query)
# submit the form to perform a Google search
search_form.submit()
# wait up to 5 seconds for the "People also ask" section
# to be on the page after page change
people_also_ask_div = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((
By.XPATH, "//div[@jscontroller and @jsname and @jsaction][.//div[@role='heading' and contains(., 'People also ask')]]"
))
)
# where to store the scraped data
people_also_ask_questions = []
# select the question dropdowns and iterate over them
people_also_ask_inner_div = people_also_ask_div.find_element(By.CSS_SELECTOR, "[data-sgrd='true']")
people_also_ask_inner_div_children = people_also_ask_inner_div.find_elements(By.XPATH, "./*")
for child in people_also_ask_inner_div_children:
# if the current element is a question dropdown
if child.get_attribute("jsname") is not None and child.get_attribute("class") == '':
# expand the element
child.click()
# scraping logic
question_title_element = child.find_element(By.CSS_SELECTOR, "[aria-expanded='true'] span")
question_title = question_title_element.text
question_description_element = child.find_element(By.CSS_SELECTOR, "[data-attrid='wa:/description'] span[lang]")
question_description = question_description_element.text
try:
question_image_element = child.find_element(By.CSS_SELECTOR, "img[data-ilt]")
question_image = question_image_element.get_attribute("src")
except NoSuchElementException:
question_image = None
question_source_element = child.find_element(By.XPATH, ".//h3/ancestor::a")
question_source = question_source_element.get_attribute("href")
# populate the array with the scraped data
people_also_ask_question = {
"title": question_title,
"description": question_description,
"image": question_image,
"source": question_source
}
people_also_ask_questions.append(people_also_ask_question)
# export the scraped data to a CSV file
csv_file = "people_also_ask.csv"
header = ["title", "description", "image", "source"]
with open(csv_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(people_also_ask_questions)
# close the browser and free up the resources
driver.quit()
En 100 lignes de code, vous venez de créer un scraper « Les gens recherchent aussi » !
Vérifiez qu’il fonctionne en l’exécutant. Vérifiez qu’il fonctionne en l’exécutant. Sous Windows, lancez le scraper avec :
python scraper.py
Sinon, sous Linux ou macOS, exécutez :
python3 scraper.py
Attendez la fin de l’exécution du scraper et un fichier people_also_ask.csv apparaîtra dans le répertoire racine de votre projet. Ouvrez-le et vous verrez :
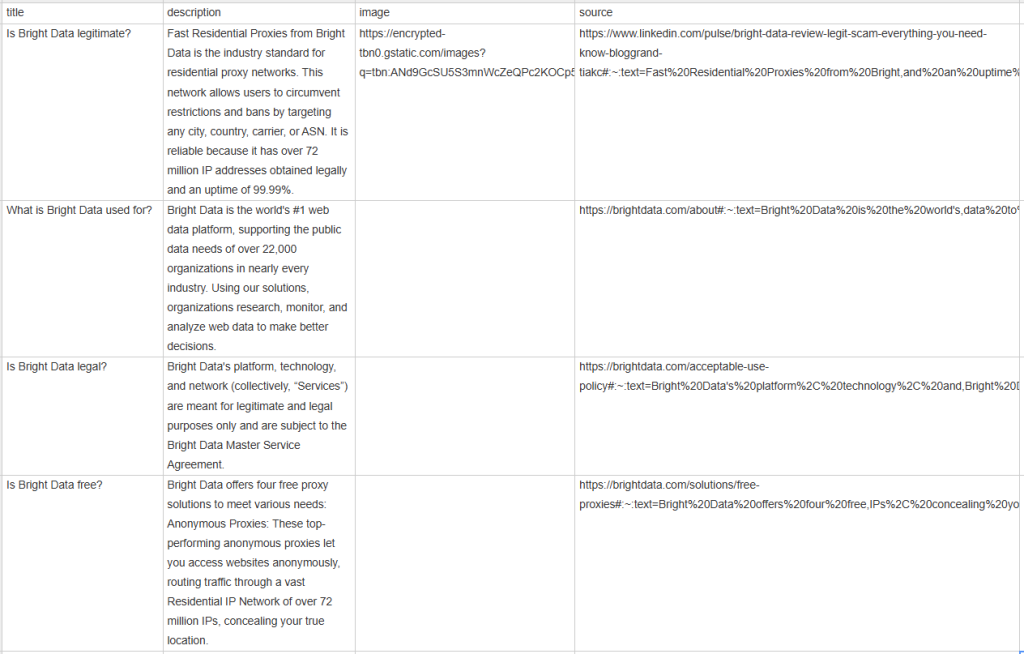
Félicitations, votre mission est terminée !
Conclusion
Dans ce tutoriel, vous avez appris ce qu’est la section « Les gens recherchent aussi » sur les pages Google, les données qu’elle contient et comment les scraper en utilisant Python. Comme vous l’avez appris ici, la création d’un script simple pour récupérer automatiquement des données ne prend que quelques lignes de code Python.
Bien que la solution présentée fonctionne bien pour les petits projets, elle n’est pas pratique pour le scraping à grande échelle. Le problème est que Google dispose de la technologie anti-bot la plus avancée du secteur. Elle pourrait donc vous bloquer avec des CAPTCHA ou des interdictions d’adresses IP. En outre, la mise à l’échelle de ce processus sur plusieurs pages augmenterait les coûts d’infrastructure.
Cela signifie-t-il que le scraping de Google de manière efficace et fiable est impossible ? Pas du tout ! Vous avez simplement besoin d’une solution avancée qui répond à ces défis, telle que l’API Google Search de Bright Data.
L’API Google Search fournit un endpoint pour récupérer les données des pages de résultats de recherche de Google, y compris la section « Les gens recherchent aussi ». Avec un simple appel d’API, vous pouvez obtenir les données que vous voulez au format JSON ou HTML. Découvrez comment commencer avec la documentation officielle.
Inscrivez-vous maintenant et commencez votre essai gratuit !




