

Dans ce guide sur l’analyse de données avec Python, vous verrez :
- Pourquoi utiliser Python pour l’analyse de données ?
- Bibliothèques communes pour l’analyse de données avec Python
- Un tutoriel pas à pas pour faire de l’analyse de données en Python
- Le processus à suivre lors de l’analyse des données
Plongeons dans l’aventure !
Pourquoi utiliser Python pour l’analyse de données
L’analyse des données est généralement réalisée à l’aide de deux principaux langages de programmation :
- R: plus adapté aux chercheurs et aux statisticiens.
- Python: Le meilleur pour tous les autres professionnels
En particulier, voici les principales raisons d’utiliser Python pour l’analyse des données :
- Courbe d’apprentissage peu prononcée: Python a une syntaxe simple et lisible, ce qui le rend accessible aux débutants comme aux experts.
- Polyvalence: Python peut gérer une grande variété de types et de formats de données, notamment CSV, Excel, JSON, les bases de données SQL, Parquet, etc. Il convient également à des tâches allant du simple nettoyage de données à des applications complexes d’apprentissage automatique et d’apprentissage profond.
- Évolutivité: Python est évolutif et peut gérer aussi bien de petits ensembles de données que des tâches de traitement de données à grande échelle. Par exemple, des bibliothèques telles que Dask et PySpark vous permettent de traiter des données volumineuses sans effort.
- Soutien de la communauté: Python dispose d’une communauté importante et active de développeurs et de scientifiques des données qui contribuent à son écosystème.
- Intégration de l’apprentissage automatique et de l’IA: Python est le langage de prédilection pour l’apprentissage automatique et l’IA, avec des bibliothèques telles que TensorFlow, PyTorch et Keras qui prennent en charge l’analyse avancée et la modélisation prédictive.
- Reproductibilité et collaboration: Les blocs-notes Jupyter vous permettent de partager et de reproduire des bribes d’analyse de données, ce qui est important pour la collaboration dans le domaine de la science des données.
- Un environnement unique pour des objectifs différents: Python offre la possibilité d’utiliser le même environnement à des fins différentes. Par exemple, vous pouvez utiliser le même bloc-notes Jupyter pour récupérer des données sur le web et les analyser. Dans le même environnement, vous pouvez également faire des prédictions avec des modèles d’apprentissage automatique.
Bibliothèques communes pour l’analyse de données avec Python
Python est largement utilisé dans le domaine de l’analyse de données, notamment en raison de son vaste écosystème de bibliothèques. Voici les bibliothèques les plus courantes pour l’analyse de données en Python :
- NumPy: Pour les calculs numériques et la manipulation de tableaux multidimensionnels.
- Pandas: Pour la manipulation et l’analyse des données, en particulier des données tabulaires.
- Matplotlib et Seaborn: Pour la visualisation de données et la création de graphiques intéressants.
- SciPy: Pour le calcul scientifique et l’analyse statistique avancée.
- Plotly: Pour créer des graphiques animés.
Voyez-les en action dans la section guidée qui suit !
Analyse de données avec Python : Un exemple complet
Vous savez maintenant pourquoi utiliser Python pour l’analyse de données et connaissez les bibliothèques courantes qui soutiennent cette tâche. Suivez ce tutoriel pas à pas pour apprendre à effectuer des analyses de données avec Python.
Dans cette section, vous analyserez les informations sur les propriétés Airbnb extraites d’un ensemble de données gratuites de Bright Data.
Exigences
Pour suivre ce guide, vous devez avoir installé Python 3.6 ou plus sur votre machine.
Étape 1 : Configurer l’environnement et installer les dépendances
Supposons que vous appeliez le dossier principal de votre projet data_analysis/. À la fin de cette étape, le dossier aura la structure suivante :
data_analysis/
├── analysis.ipynb
└── venv/Où ?
analysis.ipynbest le carnet Jupyter qui contient tout le code Python d’analyse des données.venv/contient l’environnement virtuel Python.
Vous pouvez créer le répertoire de l ‘environnement virtuel venv/ de la manière suivante :
python -m venv venvPour l’activer sous Windows, exécutez :
venvScriptsactivateDe manière équivalente, sous macOS/Linux, exécutez :
source venv/bin/activateDans l’environnement virtuel activé, installez toutes les bibliothèques requises :
pip install pandas jupyter matplotlib seaborn numpyPour créer le fichier analysis.ipynb, vous devez d’abord entrer dans le dossier data_analysis/ :
cd data_analysisEnsuite, initialisez un nouveau Notebook Jupyter avec cette commande :
jupyter notebookVous pouvez désormais accéder à votre Jupyter Notebook App à l’adresse http://locahost:8888 dans votre navigateur.
Créez un nouveau fichier en cliquant sur l’option “New > Python 3 (ipykernel)” :
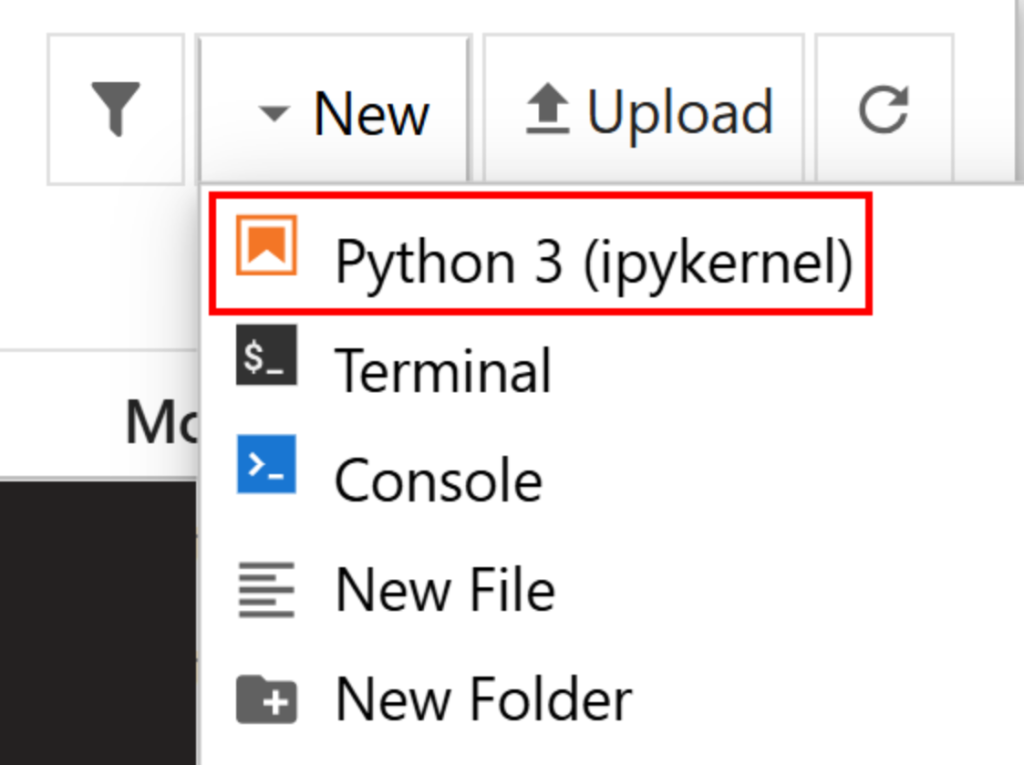
Par défaut, le nouveau fichier s’appelle untitled.ipynb. Vous pouvez le renommer dans le tableau de bord comme suit :
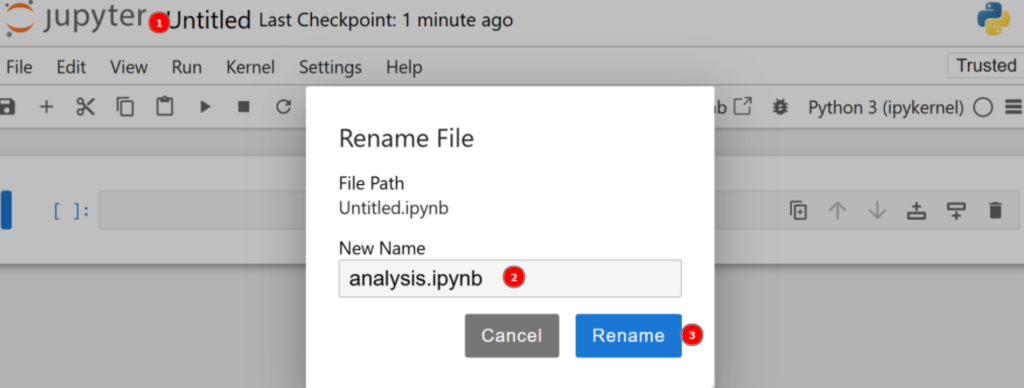
C’est génial ! Vous êtes maintenant prêt pour l’analyse de données avec Python.
Étape 2 : Télécharger les données et les ouvrir
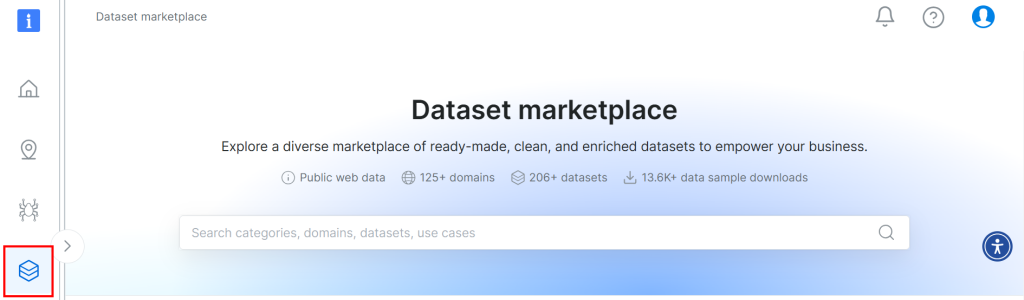
Le jeu de données utilisé pour ce tutoriel provient de la place de marché de jeux de données de Bright Data. Pour le télécharger, inscrivez-vous gratuitement sur la plateforme et accédez à votre tableau de bord. Ensuite, suivez le chemin “Web Datasets > Dataset” pour accéder à la place de marché des jeux de données :
Faites défiler vers le bas et recherchez la carte “Airbnb Properties Information” :
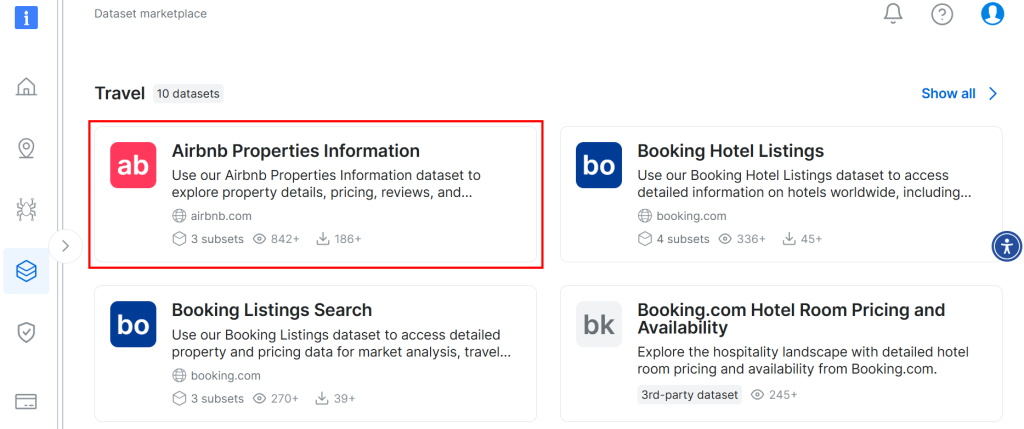
Pour télécharger l’ensemble des données, cliquez sur l’option “Télécharger l’échantillon > Télécharger en CSV” :
Vous pouvez maintenant renommer le fichier téléchargé, par exemple en airbnb.csv. Pour ouvrir le fichier CSV dans le carnet Jupyter, écrivez ce qui suit dans une nouvelle cellule :
import pandas as pd
# Open CSV
data = pd.read_csv("airbnb.csv")
# Show head
data.head()Dans cet extrait :
- La méthode
read_csv()ouvre le fichier CSV en tant qu’ensemble de données pandas. - La méthode
head()affiche les 5 premières lignes de l’ensemble de données.
Vous trouverez ci-dessous le résultat escompté :
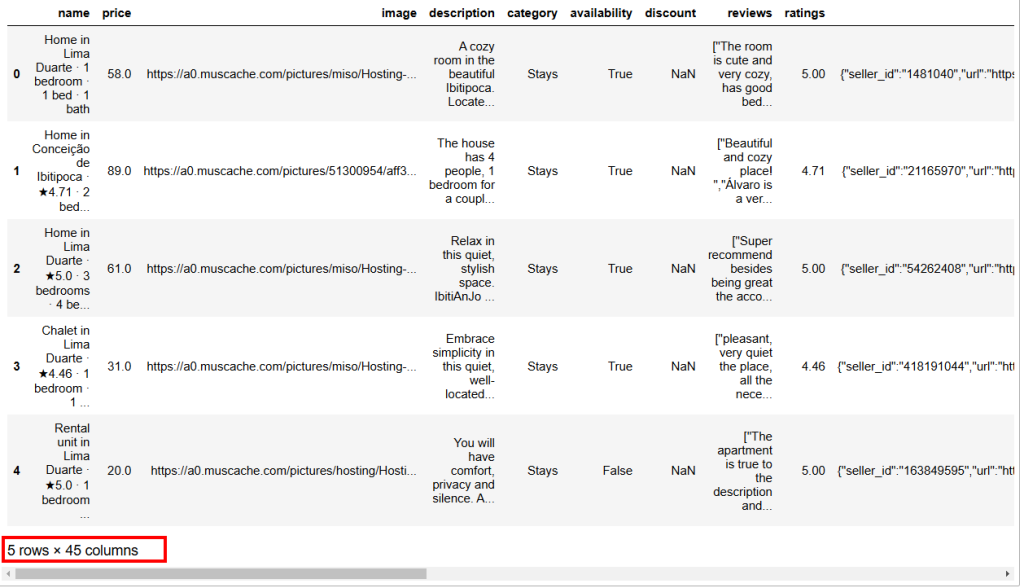
Comme vous pouvez le voir, cet ensemble de données comporte 45 colonnes. Pour les voir toutes, vous devez déplacer la barre vers la droite. Cependant, dans ce cas, le nombre de colonnes est élevé et le seul fait de faire défiler la barre vers la droite ne vous permettra pas de voir toutes les colonnes, car certaines ont été cachées.
Pour bien visualiser toutes les colonnes, tapez ce qui suit dans une cellule séparée :
# Show all columns
pd.set_option("display.max_columns", None)
# Display the data frame
print(data)Étape 3 : Gérer les NaN
En informatique, NaN signifie “Not a Number” (pas un nombre). Lorsque vous effectuez des analyses de données avec Python, vous pouvez rencontrer des ensembles de données contenant des valeurs vides, des chaînes de caractères là où vous devriez trouver des nombres, ou des cellules déjà étiquetées comme NaN (voir, par exemple, la colonne des remises dans l’image ci-dessus).
Votre objectif étant d’analyser des données, vous devez traiter les NaN demanière appropriée. Vous avez principalement trois façons de le faire :
- Supprimer toutes les lignes contenant des
NaN. - Remplacer les
NaNd’une colonne par la moyenne calculée sur les autres nombres de la même colonne. - Recherche de nouvelles données pour enrichir l’ensemble de données source.
Par souci de simplicité, suivons la première approche.
Tout d’abord, vous devez vérifier si toutes les valeurs de la colonne des remises sont des NaN. Si c’est le cas, vous pouvez supprimer toute la colonne. Pour vérifier cela, écrivez ce qui suit dans une nouvelle cellule :
import numpy as np
is_discount_all_nan = data["discount"].isna().all()
print(f"Is the 'discount' column all NaNs? {is_discount_all_nan}")Dans cet extrait, la méthode isna().all() analyse les NaNsde la colonne discount, qui a été filtrée de l’ensemble de données avec data["discount"].
Le résultat que vous obtiendrez est True, ce qui signifie que la colonne discount **** peut être supprimée car toutes ses valeurs sont des NaN. Pour ce faire, écrivez :
data = data.drop(columns=["discount"])L’ensemble de données original a été remplacé par un nouvel ensemble de données sans la colonne des remises.
Vous pouvez maintenant analyser l’ensemble des données et voir s’il y a d’autres NaN dans les lignes comme suit :
total_nans = data.isna().sum().sum()
print(f"Total number of NaN values in the data frame: {total_nans}")Le résultat que vous obtiendrez est le suivant :
Total number of NaN values in the data frame: 1248Cela signifie qu’il y a 1248 autres NaNdans la base de données. Pour supprimer les lignes contenant au moins un NaN, tapez :
data = data.dropna()Désormais, le cadre de données ne contient plus de NaNet est prêt pour l’analyse de données Python, sans risque de résultats faussés.
Pour vérifier que le processus s’est bien déroulé, vous pouvez écrire :
print(data.isna().sum().sum())Le résultat attendu est 0.
Étape 4 : Exploration des données
Avant de visualiser les données Airbnb, vous devez vous familiariser avec elles. Une bonne pratique consiste à commencer par visualiser les statistiques de votre ensemble de données de la manière suivante :
# Show statistics of the entire dataset
statistics = data.describe()
# Print statistics
print(statistics)C’est le résultat attendu :
price ratings lat long guests
count 182.000000 182.000000 182.000000 182.000000 182.000000
mean 147.523352 4.804505 6.754955 -68.300942 6.554945
std 156.574795 0.209834 27.795750 24.498326 3.012818
min 16.000000 4.000000 -21.837300 -106.817450 2.000000
25% 50.000000 4.710000 -21.717270 -86.628968 4.000000
50% 89.500000 4.865000 30.382710 -83.479890 6.000000
75% 180.750000 4.950000 30.398860 -43.925480 8.000000
max 1003.000000 5.000000 40.481580 -43.801300 16.000000
property_id host_number_of_reviews host_rating hosts_year
count 1.820000e+02 182.000000 182.000000 182.000000
mean 1.323460e+17 3216.879121 4.776099 7.324176
std 3.307809e+17 4812.876819 0.138849 2.583280
min 3.089381e+06 2.000000 4.290000 1.000000
25% 3.107102e+07 73.000000 4.710000 6.000000
50% 4.375321e+07 3512.000000 4.710000 9.000000
75% 4.538668e+07 3512.000000 4.890000 9.000000
max 1.242049e+18 20189.000000 5.000000 11.000000
host_response_rate total_price
count 182.000000 182.000000
mean 98.538462 859.317363
std 8.012156 1498.684990
min 25.000000 19.000000
25% 100.000000 111.500000
50% 100.000000 350.000000
75% 100.000000 934.750000
max 100.000000 13165.000000 La méthode describe() rapporte les statistiques relatives aux colonnes qui ont des valeurs numériques. C’est la première façon de commencer à comprendre vos données. Par exemple, la colonne host_rating présente les statistiques intéressantes suivantes :
- L’ensemble de données compte un total de 182 avis (valeur de
comptage). - La note maximale est de 5, la note minimale de 4,29 et la moyenne de 4,77.
Cependant, les statistiques ci-dessus peuvent ne pas être satisfaisantes. Essayez donc de visualiser un diagramme de dispersion de la colonne host_rating pour voir s’il y a un modèle intéressant que vous pourriez vouloir étudier plus tard. Voici comment créer un diagramme de dispersion avec seaborn:
import seaborn as sns
import matplotlib.pyplot as plt
# Define figure size
plt.figure(figsize=(15, 10))
# Plot the data
sns.scatterplot(data=data, x="host_rating", y="listing_name")
# Labeling
plt.title("HOST RATINGS SCATTERPLOT", fontsize=20)
plt.xlabel("Host ratings", fontsize=16)
plt.ylabel("Houses", fontsize=16)
# Show plot
plt.show()L’extrait ci-dessus permet d’effectuer les opérations suivantes :
- Définit la taille de l’image (en pouces) avec la méthode
figure(). - Crée un nuage de points en utilisant seaborn via la méthode
scatterplot()configurée avec:Polylang placeholder do not modify
C’est le résultat attendu :
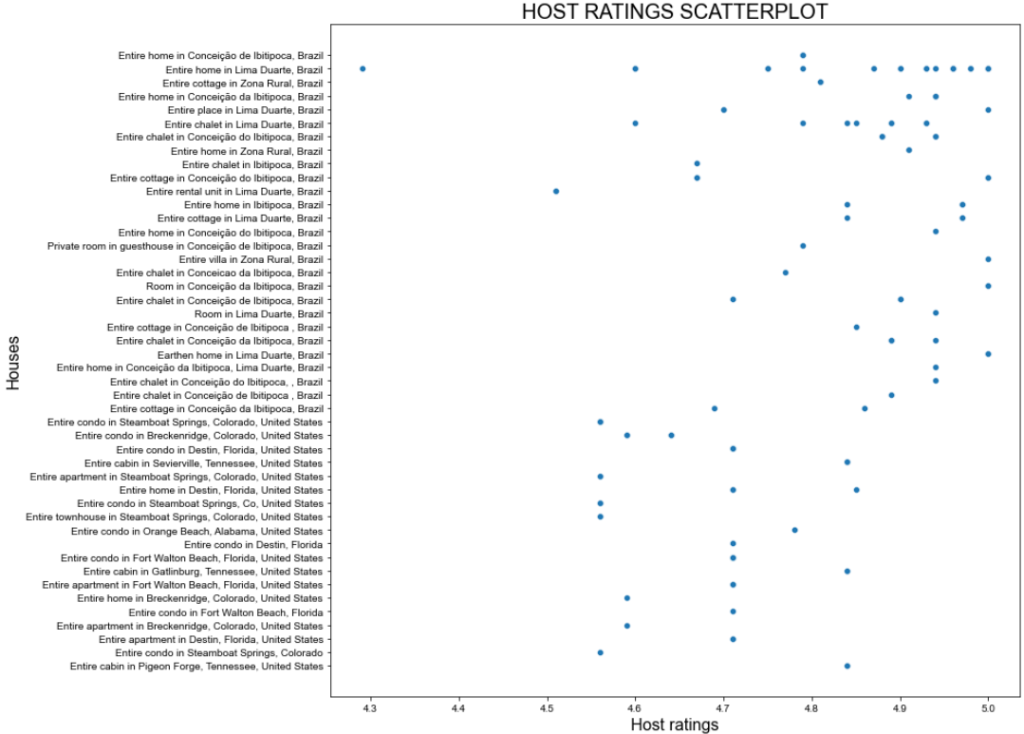
Une belle intrigue, mais on peut faire mieux !
Étape 5 : Transformation et visualisation des données
Le diagramme de dispersion précédent montre qu’il n’y a pas de tendance particulière dans les évaluations des hôtes. Cependant, la majorité des classements sont supérieurs à 4,7 points.
Imaginez que vous planifiez des vacances et que vous souhaitiez séjourner dans l’un des meilleurs endroits. Une question que vous pourriez vous poser est la suivante : “Combien coûte un séjour dans une maison ayant une note d’au moins 4,8 ?”
Pour répondre à cette question, vous devez d’abord transformer vos données !
La transformation que vous pouvez effectuer consiste à créer un nouveau cadre de données dans lequel l’évaluation est supérieure à 4,8. Celui-ci contiendra la colonne listing_n`ame avec les noms des appartements et la colonne total_price avec leurs prix.
Obtenez ce sous-ensemble et affichez ses statistiques avec :
# Filter the DataFrame
high_ratings = data[data["host_rating"] > 4.8][["listing_name", "total_price"]]
# Caltulate and print statistics
high_ratings_statistics = high_ratings.describe()
print(high_ratings_statistics)L’extrait ci-dessus crée un nouveau cadre de données appelé high_ratings de la manière suivante :
data["host_rating"] > 4.8filtre les valeurs supérieures à 4.8 dans la colonnehost_ratings del’ensemble dedonnées.[["listing_name", "total_price"]]sélectionne uniquement les colonneslisting_nameettotal_pricedu cadre de donnéeshigh_ratings.
Voici le résultat attendu :
total_price
count 78.000000
mean 321.061026
std 711.340269
min 19.000000
25% 78.250000
50% 116.000000
75% 206.000000
max 4230.000000Les statistiques montrent que le prix total moyen des appartements sélectionnés est de 321 $, avec un minimum de 19 $ et un maximum de 4230 $. Cela nécessite une analyse plus approfondie !
Visualisez un diagramme de dispersion des prix des maisons bien notées en utilisant le même extrait que celui que vous avez utilisé précédemment. Tout ce que vous avez à faire est de changer les variables utilisées dans le graphique comme suit :
# Define figure size
plt.figure(figsize=(12, 8))
# Plot the data
sns.scatterplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show grid for better visualization
sns.set_style("ticks", {'axes.grid': True})
# Show plot
plt.show()Et voici le graphique qui en résulte :
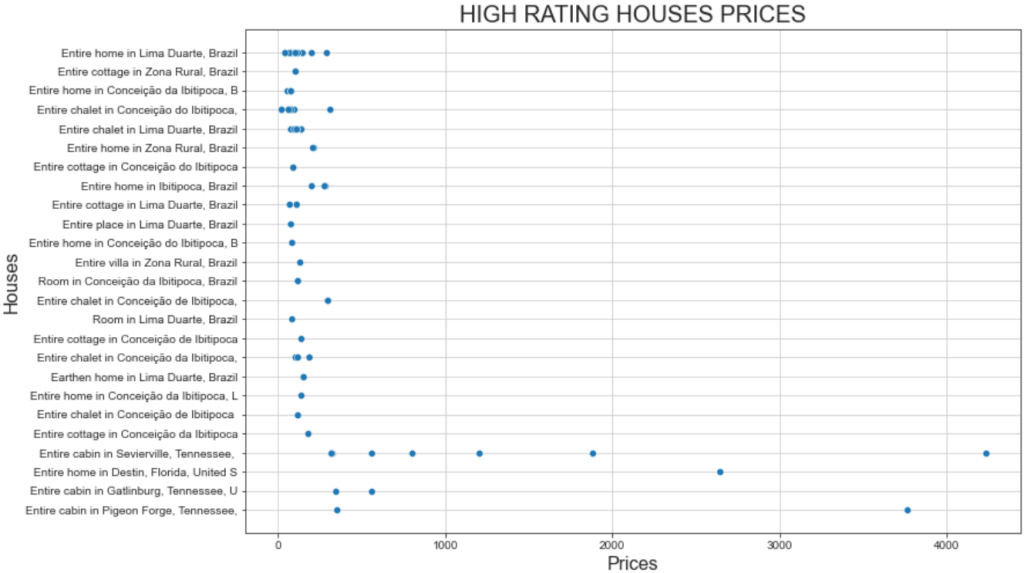
Ce graphique met en évidence deux faits intéressants :
- Les prix sont généralement inférieurs à 500 dollars.
- La “Cabane entière à Sevierville” et la “Cabane entière à Pigeon” présentent des prix bien supérieurs à 1000 $.
Une meilleure façon de visualiser la fourchette de prix est d’afficher un diagramme en boîte. Voici comment procéder :
# Define figure size
plt.figure(figsize=(15, 10))
# Plotting the boxplot
sns.boxplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES - BOXPLOT', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show plot
plt.show()Cette fois-ci, le graphique obtenu sera le suivant :
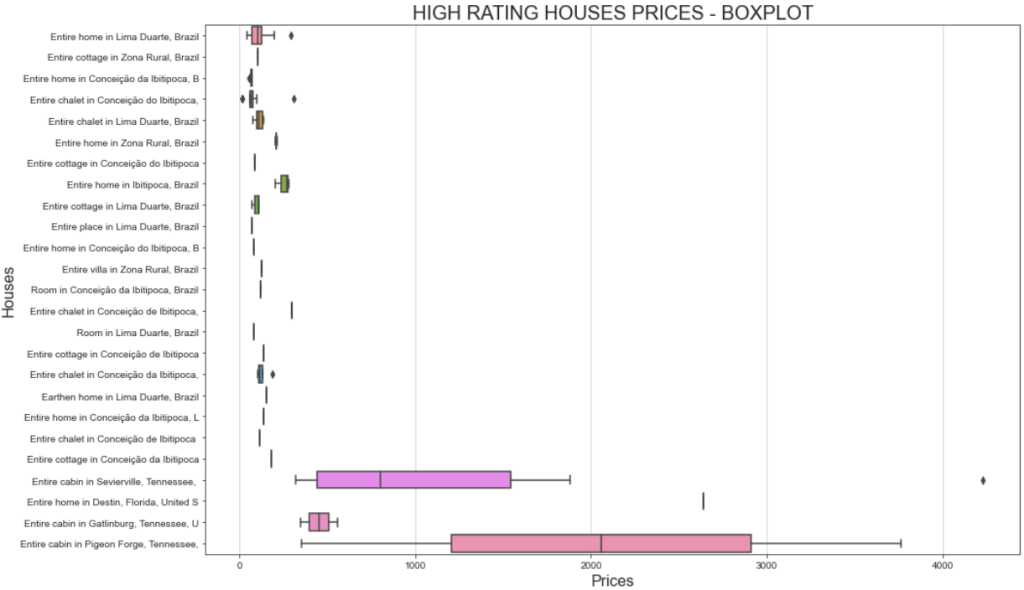
Si vous vous demandez pourquoi une même maison peut avoir des coûts différents, vous devez vous rappeler que vous avez filtré les évaluations des utilisateurs. Cela signifie que les utilisateurs ont payé différemment et ont laissé des évaluations différentes.
En outre, l’importante variation de prix pour le “chalet entier à Sevierville”, allant de moins de 1 000 $ à plus de 4 000 $, peut être due à la durée du séjour. En effet, l’ensemble de données original comprend une colonne appelée travel_details, qui contient des informations sur la durée du séjour. La large fourchette de prix pourrait indiquer que certains utilisateurs ont loué la maison pour une période prolongée. Une analyse plus approfondie à l’aide de Python pourrait permettre d’en savoir plus à ce sujet !
Étape 6 : Investigations complémentaires via la matrice de corrélation
L’analyse de données Python consiste à poser des questions et à chercher des réponses dans les données dont on dispose. La visualisation de la matrice de corrélation est un moyen efficace de susciter ces questions.
La matrice de corrélation est un tableau qui montre les coefficients de corrélation pour différentes variables. Le coefficient de corrélation le plus utilisé est le coefficient de corrélation de Pearson (CCP), qui mesure la corrélation linéaire entre deux variables. Ses valeurs sont comprises entre -1 et +1, ce qui signifie :
- +1 : Si la valeur d’une variable augmente, l’autre augmente linéairement.
- -1 : Si la valeur d’une variable augmente, l’autre diminue linéairement.
- 0 : Vous ne pouvez rien dire sur la relation linéaire des deux variables (cela nécessite une analyse non linéaire).
En statistique, les valeurs de la corrélation linéaire se définissent comme suit :
- 0,1-0,5 : faible corrélation.
- 0,6-1 : corrélation élevée.
- 0 : pas de corrélation.
Pour afficher la matrice de corrélation pour le cadre de données, vous pouvez taper ce qui suit :
# Set the images dimensions
plt.figure(figsize=(12, 10))
# Labeling
plt.title('CORRELATION MATRIX', fontsize=20)
plt.xticks(fontsize=16) # x-axis font size
plt.yticks(fontsize=16) # y-axis font size
# Applying mask
mask = np.triu(np.ones_like(numeric_data.corr()))
dataplot = sns.heatmap(numeric_data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})
#Add this code before creating the correlation matrix
numeric_data = data.select_dtypes(include=['float64', 'int64'])
# Correlation matrix
dataplot = sns.heatmap(data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})L’extrait ci-dessus permet d’effectuer les opérations suivantes :
- La méthode
np.triu()est utilisée pour diagonaliser une matrice. Cela permet de mieux visualiser la matrice, qui apparaît alors sous la forme d’un triangle et non d’un carré. - La méthode
sns.heatmap()crée une carte thermique. Elle est également utilisée pour une meilleure visualisation. La méthodedata.corr()calcule les coefficients de Pearson pour chaque colonne de la base dedonnées.
Voici le résultat que vous obtiendrez :

L’idée principale lors de l’interprétation d’une matrice de corrélation est de trouver les variables qui ont une forte corrélation, car elles seront le point de départ d’une nouvelle analyse plus approfondie. Ces variables seront le point de départ d’une nouvelle analyse plus approfondie :
- Les variables
latetlongont une corrélation de -0,98. Ce résultat est attendu, car la latitude et la longitude sont fortement corrélées lorsqu’il s’agit de définir un lieu spécifique sur la Terre. - Les variables
host_ratingetlongitudeont une corrélation de -0,69. Il s’agit d’un résultat intéressant, qui signifie que l’évaluation de l’hôte est fortement corrélée à la variable longitude. Il semble donc que les maisons situées dans une certaine région du monde aient des notes d’accueil élevées. - Les variables
latetlongont respectivement une corrélation de 0,63 et -0,69 avec leprix. Cela suffit pour dire que le prix par jour est fortement influencé par la localisation.
Dans votre analyse, vous devez également rechercher des variables non corrélées. Par exemple, le coefficient des variables is_supperhost et price est de -0,18, ce qui signifie que les superhosts n’ont pas les prix les plus élevés.
Maintenant que les principaux concepts sont clairs, c’est à vous d’explorer et d’analyser vos données !
Étape 7 : Assembler le tout
Voici à quoi ressemblera le carnet Jupyter final pour l’analyse de données avec Python :









Notez la présence de différentes cellules, chacune avec sa sortie.
Le processus d’analyse de données avec Python
La section ci-dessus vous a guidé à travers le processus d’analyse de données avec Python. Bien qu’elle ait pu ressembler à une approche pas à pas guidée par l’opportunité, elle s’est en fait appuyée sur les meilleures pratiques suivantes :
- Recherche de données: Si vous avez la chance d’avoir les données dont vous avez besoin dans une base de données, vous avez de la chance ! Si ce n’est pas le cas, vous devez les récupérer à l’aide de méthodes d’extraction de données courantes telles que le“web scraping”.
- Nettoyage des données: Traiter les
NaN, agréger les données et appliquer les premiers filtres de l’ensemble de données initial. - Exploration des données: L’exploration des données – parfois également appelée découverte des données – estla partie la plus importante de l’analyse des données avec Python. Elle nécessite la production de graphiques de base pour vous aider à comprendre comment vos données sont structurées ou si elles suivent des modèles particuliers.
- Lamanipulation des données: Après avoir saisi les idées principales des données que vous analysez, vous devez les manipuler. Cette partie nécessite de filtrer les ensembles de données et souvent de combiner plus de deux ensembles de données en un seul (comme si vous faisiez des jointures de tables en SQL).
- Visualisation des données: Il s’agit de la dernière partie, dans laquelle vous présentez visuellement vos données en réalisant plusieurs tracés sur les ensembles de données manipulés.
Conclusion
Dans ce guide sur l’analyse de données avec Python, vous avez appris pourquoi vous devriez utiliser Python pour analyser des données et quelles bibliothèques courantes vous pouvez utiliser à cette fin. Vous avez également suivi un tutoriel étape par étape et appris la procédure à suivre si vous souhaitez effectuer une analyse de données en Python.
Vous avez vu que Jupyter Notebook vous aide à créer des sous-ensembles de vos données, à les visualiser et à découvrir de puissantes informations. Tout cela en conservant l’ensemble structuré dans le même environnement. Maintenant, où trouver des ensembles de données prêts à l’emploi ? Bright Data s’occupe de tout !
Bright Data exploite un réseau de serveurs mandataires vaste, rapide et fiable, utilisé par de nombreuses entreprises du Fortune 500 et plus de 20 000 clients. Ce réseau est utilisé pour récupérer de manière éthique des données sur le web et les proposer sur un vaste marché d’ensembles de données, qui comprend :
- Ensembles de données commerciales: Données provenant de sources clés telles que LinkedIn, CrunchBase, Owler et Indeed.
- Ensembles de données sur le commerce électronique: Données d’Amazon, Walmart, Target, Zara, Zalando, Asos et bien d’autres.
- Ensembles de données immobilières: Données provenant de sites web tels que Zillow, MLS, etc.
- Jeux de données sur les médias sociaux: Données provenant de Facebook, Instagram, YouTube et Reddit.
- Ensembles de données financières: Données de Yahoo Finance, Market Watch, Investopedia, etc.
Créez un compte Bright Data gratuit dès aujourd’hui et explorez nos ensembles de données.






