Dans cet article, nous aborderons :
- Explication du pipeline ETL
- Avantages des pipelines ETL
- Comment mettre en œuvre un pipeline ETL dans une entreprise
- Automatisation de certaines étapes du pipeline ETL
- FAQ sur le pipeline ETL
Explication du pipeline ETL
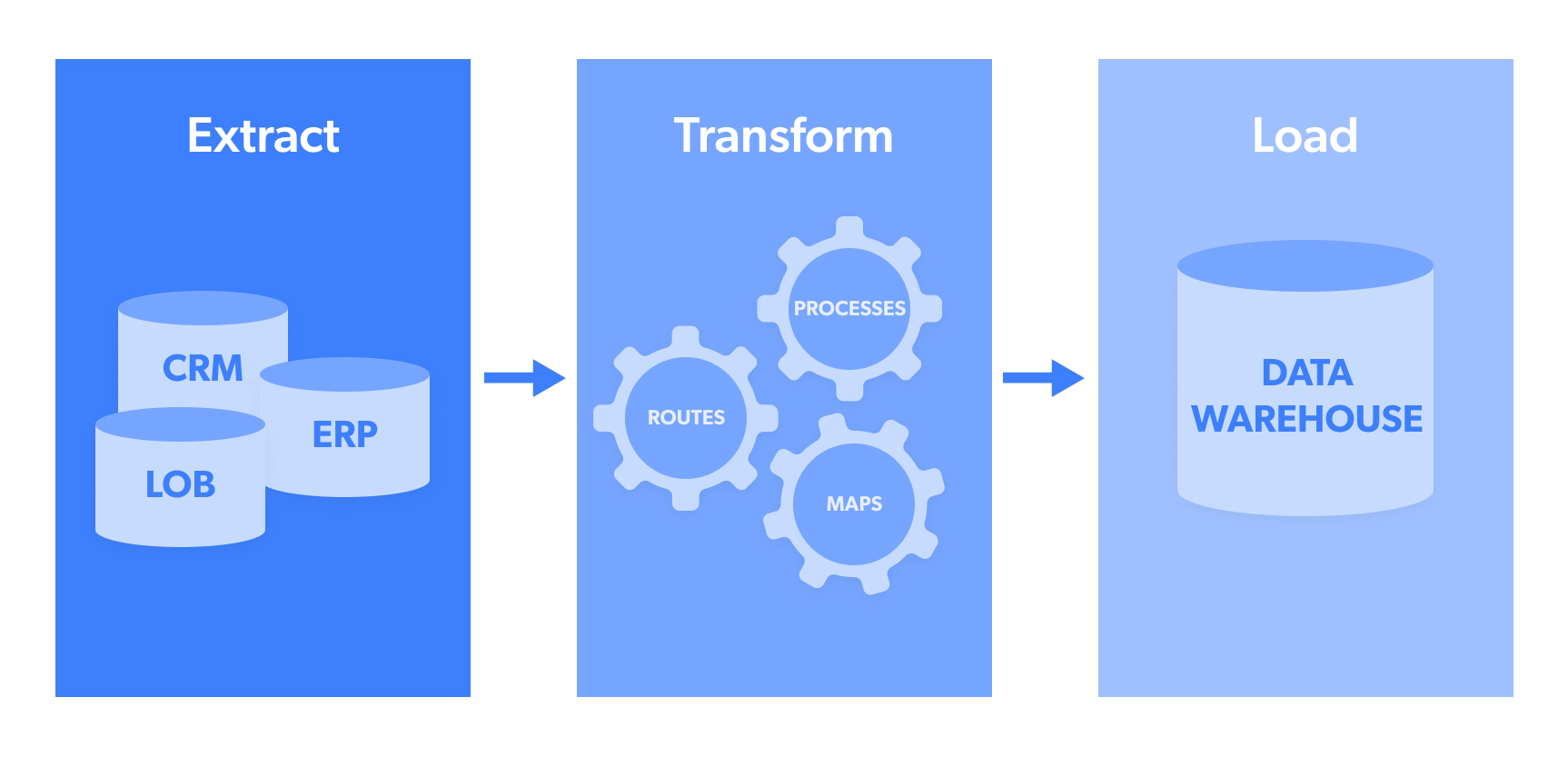
ETL signifie :
- Extraction : il s’agit de l’étape d’extraction des données à partir d’une source ou d’un pool de données tel qu’une base de données NoSQL ou un site web open source cible tel que les publications tendance sur les réseaux sociaux.
- Transformer : les donnéesextraites sont généralement collectées dans plusieurs formats. La « transformation » désigne le processus de structuration de ces données afin qu’elles soient dans un format uniforme pouvant ensuite être envoyé au système cible. Cela peut inclure des formats tels que JSON, CSV, HTML ou Microsoft Excel.
- Chargement : il s’agit du transfert/téléchargement effectif des données vers un pool/entrepôt de données, un CRM ou une base de données afin qu’elles puissent ensuite être analysées et générer des résultats exploitables. Parmi les destinations de données les plus couramment utilisées, on trouve les webhooks, les e-mails, Amazon S3, Google Cloud, Microsoft Azure, SFTP ou les API.
Points à garder à l’esprit :
- Les pipelines ETL sont particulièrement adaptés aux petits jeux de données présentant un niveau de complexité élevé.
- Les « pipelines ETL » sont souvent confondus avecles « pipelines de données »; ce dernier terme est plus large et désigne les architectures de collecte de données à cycle complet, tandis que le premier désigne une procédure plus ciblée.
Avantages des pipelines ETL
Voici quelques-uns des principaux avantages des pipelines ETL :
Premièrement : données brutes provenant de plusieurs sources
Les entreprises qui cherchent à se développer rapidement peuvent tirer parti de solides architectures de pipelines ETL dans la mesure où celles-ci leur permettent d’élargir leur champ de vision. En effet, un bon flux d’ingestion de données ETL permet aux entreprises de collecter des données brutes dans différents formats, provenant de sources multiples, et de les intégrer efficacement dans leurs systèmes à des fins d’analyse. Cela signifie que la prise de décision sera beaucoup plus en phase avec les tendances actuelles des consommateurs/concurrents.
Deuxièmement : réduction du « délai d’analyse »
Comme pour tout flux opérationnel, une fois qu’il est mis en place, le temps entre la collecte initiale et l’obtention d’informations exploitables peut être considérablement réduit. Au lieu de demander à des experts en données d’examiner manuellement chaque jeu de données, de le convertir au format souhaité, puis de l’envoyer à la destination cible, ce processus est rationalisé, ce qui permet d’obtenir des informations plus rapidement.
Troisièmement : libération des ressources de l’entreprise
Dans le prolongement de ce dernier point, de bons pipelines ETL permettent de libérer les ressources de l’entreprise à plusieurs niveaux, notamment en libérant du personnel. En effet, les entreprises :
«consacrent plus de 80 % de leur temps au nettoyage des données en vue de leur utilisation par l’IA».
Dans ce cas, le nettoyage des données fait notamment référence au « formatage des données », une tâche dont se chargent les pipelines ETL solides.
Comment mettre en œuvre un pipeline ETL dans une entreprise
Voici un cas d’utilisation dans le domaine du commerce électronique qui peut aider à illustrer comment un pipeline ETL peut être mis en œuvre dans une entreprise :
Une entreprise de vente au détail numérique doit agréger de nombreux points de données provenant de diverses sources afin de rester compétitive et attrayante pour ses clients cibles. Voici quelques exemples de sources de données :
- Avis laissés sur les marchands concurrents sur les places de marché
- Tendances de recherche Google pour des articles/services
- Publicités (texte + images) des entreprises concurrentes
Tous ces points de données peuvent être collectés dans différents formats tels que (.txt), (.csv), (.tab), SQL, (.jpg) et autres. Disposer d’informations cibles dans plusieurs formats n’est pas propice aux objectifs commerciaux de l’entreprise (c’est-à-dire obtenir des informations sur les concurrents/consommateurs en temps réel et apporter des modifications pour augmenter les ventes).
C’est pour cette raison que ce fournisseur e-commerce peut choisir de mettre en place un pipeline ETL qui convertit tous les formats ci-dessus en l’un des formats suivants (en fonction de son algorithme/de ses préférences de système d’entrée) :
- JSON
- CSV
- HTML
- Microsoft Excel
Supposons qu’il choisisse Microsoft Excel comme format de sortie préféré pour afficher les catalogues de produits concurrents. Un responsable du cycle de vente et de la production peut alors rapidement examiner ces informations et identifier les nouveaux produits vendus par les concurrents qu’il pourrait souhaiter inclure dans son propre catalogue numérique.
Automatisation de certaines étapes du pipeline ETL
De nombreuses entreprises n’ont tout simplement pas le temps, les ressources et la main-d’œuvre nécessaires pour mettre en place manuellement des opérations de collecte de données, ainsi qu’un pipeline ETL. Dans ces cas de figure, elles optent pour un outil d’extraction de données web entièrement automatisé.
Ce type de technologie permet aux entreprises de se concentrer sur leurs propres activités commerciales tout en tirant parti d’architectures de pipeline ETL autonomes développées et exploitées par un tiers. Les principaux avantages de cette option sont les suivants :
- Extraction de données web sans infrastructure/code
- Aucune main-d’œuvre technique supplémentaire nécessaire
- Les données sont nettoyées, analysées et synthétisées automatiquement, puis livrées dans le format uniforme de votre choix (JSON, CSV, HTML ou Microsoft Excel). Cette étape remplace le pipeline ETL et est effectuée automatiquement.
- Les données sont ensuite transmises au consommateur côté entreprise (par exemple, une équipe, un algorithme ou un système). Cela inclut les webhooks, les e-mails, Amazon S3, Google Cloud, Microsoft Azure, SFTP ou API.
Outre les outils d’extraction de données automatisés, il existe également un raccourci efficace et utile que peu de gens connaissent. De nombreuses entreprises accélèrent le « temps d’accès aux informations » en supprimant complètement le besoin de collecte de données et les pipelines ETL. Pour ce faire, elles exploitent la puissance des Jeux de données prêts à l’emploi, déjà formatés de manière uniforme et fournis directement aux consommateurs de données internes.
Conclusion
Les pipelines ETL constituent un moyen efficace de rationaliser la collecte de données provenant de plusieurs sources, de réduire le temps nécessaire pour tirer des informations exploitables des données et de libérer des ressources humaines et matérielles essentielles à la mission. Mais malgré l’efficacité qu’ils offrent, les pipelines ETL nécessitent encore beaucoup de temps et d’efforts pour être développés et exploités. C’est pourquoi de nombreuses entreprises choisissent d’externaliser et d’automatiser leur collecte de données et leur flux de pipelines ETL à l’aide d’outils tels que l’outil de Scraping web de Bright Data. Contactez-nous pour trouver la solution ultime pour votre projet de données.
FAQ sur les pipelines ETL
ETL signifie « Extract, Transform, Load » (extraire, transformer, charger). Il s’agit du processus qui permet de récupérer des données provenant de plusieurs sources et de les formater de manière uniforme pour qu’elles puissent être ingérées par un système ou une application cible.
Le chargement est la dernière étape du processus ETL. Il consiste à télécharger les données dans un format uniforme vers un pool ou un entrepôt de données afin qu’elles puissent être traitées/analysées/exploitées. Les trois principaux types de chargement sont les suivants : 1. Chargements initiaux 2. Chargements incrémentiels 3. Actualisations complètes
Oui, il est tout à fait possible de créer un pipeline ETL avec Python. Pour ce faire, divers outils sont nécessaires, notamment « Luigi » pour gérer le flux de travail, « Pandas » pour le traitement des données et le déplacement.