

Dans ce guide, vous apprendrez :
- Ce qu’est CloudScraper et à quoi il sert
- Pourquoi vous devriez intégrer des Proxys dans Cloudscraper
- Comment procéder étape par étape
- Comment mettre en œuvre la rotation des proxys dans Cloudscraper
- Comment gérer les proxies authentifiés
- Comment utiliser un fournisseur de Proxys premium comme Bright Data
C’est parti !
Qu’est-ce que CloudScraper ?
CloudScraper est un module Python conçu pour contourner la page anti-bot de Cloudflare (communément appelée «I’m Under Attack Mode » ou IUAM). En coulisses, il est implémenté à l’aide de Requests, l’un des clients HTTP Python les plus populaires.
Cette bibliothèque est particulièrement utile pour scraper ou crawler des sites web protégés par Cloudflare. La page anti-bot vérifie actuellement si le client prend en charge JavaScript, mais Cloudflare pourrait introduire des techniques supplémentaires à l’avenir.
Comme Cloudflare met régulièrement à jour ses solutions anti-bot, la bibliothèque est également mise à jour régulièrement afin de rester fonctionnelle.
Pourquoi utiliser des Proxys avec CloudScraper ?
Cloudflare peut bloquer votre IP si vous effectuez trop de requêtes. De même, cela peut déclencher des défenses plus sophistiquées qui sont difficiles à contourner, même avec des outils tels que CloudScraper. Pour atténuer ce problème, vous avez besoin d’une méthode fiable pour faire tourner votre adresse IP.
C’est là qu’intervient un Proxy. Les Proxys agissent comme des intermédiaires entre votre Scraper et le site web cible, masquant votre adresse IP réelle avec l’IP du Proxy. Si une IP est bloquée, vous pouvez rapidement passer à un nouveau Proxy, garantissant ainsi un accès ininterrompu.
Les Proxy offrent deux avantages clés pour le Scraping web avec CloudScraper :
- Sécurité et anonymat renforcés: en acheminant les requêtes via un Proxy, votre véritable identité reste cachée, ce qui réduit le risque de détection.
- Éviter les blocages et les interruptions: les Proxy vous permettent de faire tourner les adresses IP de manière dynamique, ce qui vous aide à contourner les blocages et les limiteurs de débit.
En combinant des Proxies avec des outils tels que CloudScraper, vous pouvez créer une configuration de Scraping web robuste qui minimise les risques et maximise l’efficacité. Cette approche à deux niveaux garantit une extraction de données sécurisée et transparente, même à partir de sites dotés de mesures anti-scraping avancées.
Configurer un Proxy avec CloudScraper : guide étape par étape
Apprenez à utiliser les Proxies avec CloudScraper dans cette section guidée !
Étape n° 1 : installer CloudScraper
Vous pouvez installer CloudScraper via le package pip cloudscraper à l’aide de cette commande :
pip install -U cloudscraper
N’oubliez pas que Cloudflare met régulièrement à jour son moteur anti-bot. Veillez donc à inclure l’option -U lors de l’installation du package afin de vous assurer d’obtenir la dernière version.
Étape n° 2 : initialiser Cloudscraper
Pour commencer, importez d’abord CloudScraper :
import cloudscraper
Ensuite, créez une instance CloudScraper à l’aide de la méthode create_scraper():
Scraper = cloudscraper.create_scraper()
L’objet Scraper fonctionne de manière similaire à l’objet Session de la bibliothèque requests. Il vous permet notamment d’effectuer des requêtes HTTP tout en contournant les mesures anti-bot de Cloudflare.
Étape n° 3 : intégrer un Proxy
Comme CloudScraper est basé sur Requests, l’intégration de Proxies fonctionne de la même manière quedans Requests. Si vous n’êtes pas familier avec cette procédure, consultez notre tutoriel pour configurer un Proxy dans Requests.
Pour utiliser un Proxy avec CloudScraper, vous devez définir un dictionnaire de Proxies et le transmettre à la méthode get() comme ci-dessous :
proxies = {
"http": "<VOTRE_URL_PROXY_HTTP>",
"https": "<VOTRE_URL_PROXY_HTTPS>"
}
# Effectuer une requête via le Proxy spécifié
response = scraper.get("<VOTRE_URL_CIBLE>", proxies=proxies)
Le paramètre Proxy de la méthode get() est transmis à Requests. Cela permet au client HTTP d’acheminer votre requête via le serveur Proxy HTTP ou HTTPS spécifié, en fonction du protocole de votre URL cible.
Étape n° 4 : tester la configuration de l’intégration du Proxy CloudScraper
À des fins de démonstration, nous ciblerons le point de terminaison /ip du projet HTTPBin. Ce point de terminaison renvoie l’adresse IP de l’appelant. Si tout fonctionne comme prévu, la réponse devrait afficher l’adresse IP du Proxy.
Pour tester la configuration, vous pouvez obtenir une adresse IP de Proxy à partir d’une liste de Proxys gratuits.
Avertissement: les proxies gratuits sont souvent peu fiables, collectent des données et peuvent être dangereux, surtout s’ils ne proviennent pas de l’un des meilleurs fournisseurs de Proxy du marché. Essayez de les utiliser uniquement à des fins éducatives.
Supposons que voici l’URL de votre serveur Proxy :
http://202.159.35.121:443
Voici comment vous pouvez l’intégrer à CloudScraper :
import cloudscraper
# Créer une instance CloudScraper
scraper = cloudscraper.create_scraper()
# Spécifier votre Proxy
proxies = {
"http": "http://202.159.35.121:443",
"https": "http://202.159.35.121:443"
}
# Effectuer une requête via le Proxy
response = Scraper.get("https://httpbin.io/ip", proxies=proxies)
# Afficher la réponse du point de terminaison "/ip"
print(response.text)
Si la configuration est correcte, vous devriez obtenir une réponse similaire à celle-ci :
{
"origin": "202.159.35.121:1819"
}
Remarquez que l’adresse IP dans la réponse correspond à celle du Proxy, comme prévu.
Remarque : les Proxy gratuits ont souvent une durée de vie limitée. Par conséquent, le Proxy utilisé dans l’exemple ci-dessous pourrait ne plus fonctionner au moment où vous lirez cet article.
Bravo ! Vous avez terminé une intégration simple du Proxy CloudScraper.
Comment mettre en œuvre la rotation des proxys
L’utilisation d’un Proxy avec Cloudscraper permet de masquer votre adresse IP. Cependant, les sites de destination peuvent toujours bloquer les adresses IP. Cela se produit si trop de requêtes proviennent de la même adresse, qu’il s’agisse de votre propre adresse IP ou de celle du Proxy.
Pour éviter les interdictions d’IP, il est essentiel de faire tourner régulièrement vos IP Proxy. En répartissant vos requêtes sur plusieurs adresses IP, vous pouvez faire en sorte que votre trafic semble provenir de différents utilisateurs. Cela réduit le risque de détection.
Pour mettre en place la rotation des proxys, commencez par récupérer une liste de proxys auprès d’un fournisseur fiable. Stockez-les dans un tableau :
proxy_list = [
{"http": "<VOTRE_URL_PROXY_1>", "https": "<VOTRE_URL_PROXY_1>"},
# ...
{"http": "<VOTRE_URL_PROXY_n>", "https": "<VOTRE_URL_PROXY_n>"},
]
Ensuite, utilisez la méthode random.choice() pour sélectionner aléatoirement un Proxy dans la liste :
random_proxy = random.choice(proxy_list)
N’oubliez pas d’importer random depuis la bibliothèque standard Python :
import random
Après cela, il suffit de définir le Proxy sélectionné aléatoirement dans la requête get():
response = Scraper.get("<VOTRE_URL_CIBLE>", proxies=random_Proxy)
Si tout est correctement configuré, la requête utilisera un Proxy différent de la liste à chaque exécution. Voici le code complet :
import cloudscraper
import random
# Créer une instance Scraper
scraper = cloudscraper.create_scraper()
# Liste des URL Proxy (remplacer par les URL Proxy réelles)
proxy_list = [
{"http": "<VOTRE_URL_PROXY_1>", "https": "<VOTRE_URL_PROXY_1>"},
# ...
{"http": "<VOTRE_URL_PROXY_n>", "https": "<VOTRE_URL_PROXY_n>"},
]
# Sélectionnez aléatoirement un Proxy dans la liste
random_proxy = random.choice(proxy_list)
# Effectuez une requête à l'aide du Proxy sélectionné aléatoirement
# (remplacez par l'URL cible réelle)
response = scraper.get("<VOTRE_URL_CIBLE>", proxies=random_proxy)
Félicitations ! Vous avez maintenant intégré la rotation des proxys à Cloudscraper.
Utiliser l’authentification des Proxies dans CloudScraper
La plupart des fournisseurs proposent des serveurs Proxy authentifiés, afin que seuls les utilisateurs payants puissent y accéder. En général, vous devez spécifier un nom d’utilisateur et un mot de passe pour accéder à ces serveurs Proxy.
Pour authentifier un Proxy dans CloudScraper, vous devez inclure les informations d’identification requises directement dans l’URL du Proxy. Le format d’authentification par nom d’utilisateur et mot de passe est le suivant :
<PROXY_PROTOCOL>://<YOUR_USERNAME>:<YOUR_PASSWORD>@<PROXY_IP_ADDRESS>:<PROXY_PORT>
Avec ce format, votre configuration de Proxy CloudScraper ressemblerait à ceci :
import cloudscraper
# Créer une instance Cloudscraper
scraper = cloudscraper.create_scraper()
# Définir votre Proxy authentifié
proxies = {
"http": "<PROXY_PROTOCOL>://<VOTRE_NOM_D'UTILISATEUR>:<VOTRE_MOT_DE_PASSE>@<ADRESSE_IP_DU_PROXY>:<PORT_DU_PROXY>",
"https": "<PROXY_PROTOCOL>://<VOTRE_NOM_D'UTILISATEUR>:<VOTRE_MOT_DE_PASSE>@<ADRESSE_IP_DU_PROXY>:<PORT_DU_PROXY>"
}
# Effectuer une requête via le Proxy authentifié spécifié
response = Scraper.get("<VOTRE_URL_CIBLE>", proxies=proxies)
Incroyable ! Vous êtes prêt à découvrir comment utiliser les Proxy premium dans Cloudflare.
Intégrer des proxies premium dans Cloudscraper
Pour obtenir des résultats fiables dans les environnements de scraping de production, vous devez utiliser des Proxies provenant de fournisseurs de premier plan tels que Bright Data. Bright Data dispose d’un réseau de haute qualité comprenant plus de 150 millions d’adresses IP dans 195 pays, et prend en charge les quatre principaux types de Proxies :
- Proxys de centre de données
- Proxys résidentiels
- Proxy mobile
- Proxy ISP
Avec des fonctionnalités telles que la rotation automatique des adresses IP, une disponibilité de 100 % et des sessions IP persistantes, Bright Data se positionne comme le premier fournisseur de proxys sur le marché.
Pour intégrer les proxys Bright Data dans CloudScraper, créez un compte ou connectez-vous. Accédez au tableau de bord et cliquez sur la zone « Résidentiel » dans le tableau :
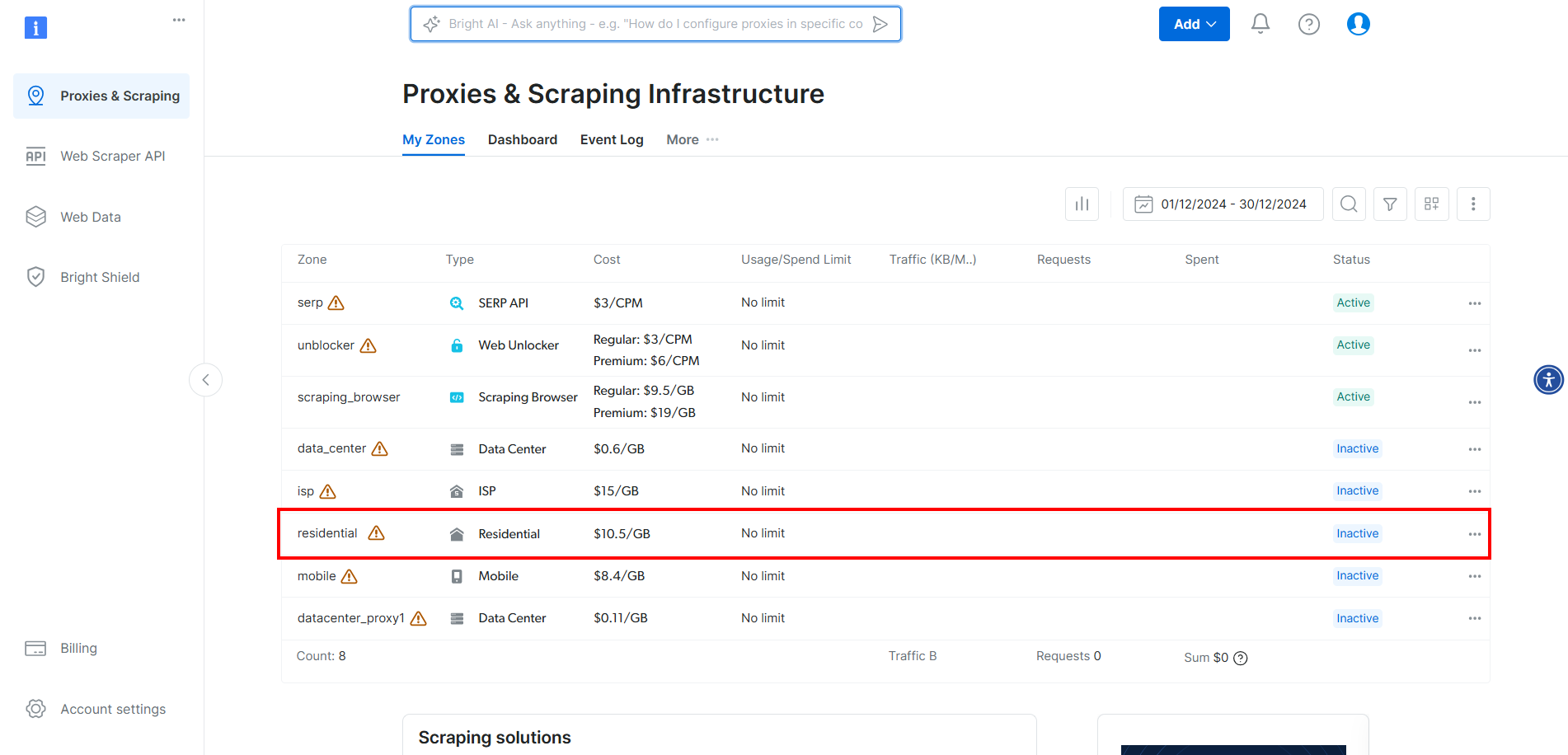
Activez ici les Proxies en cliquant sur le bouton :
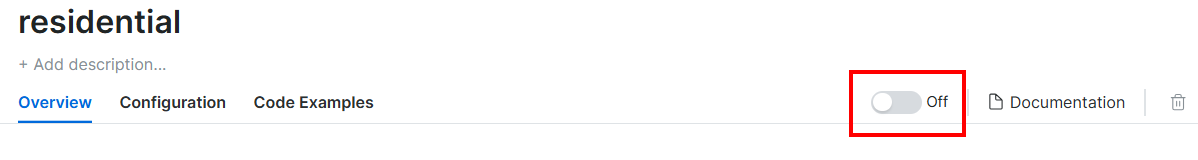
Voici ce que vous devriez voir maintenant :

Dans la section « Access Details » (Détails d’accès), copiez l’hôte Proxy, le nom d’utilisateur et le mot de passe :
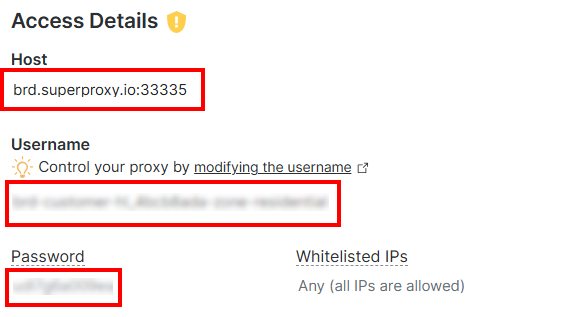
Votre URL de Proxy Bright Data ressemblera à ceci :
http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335
Intégrez maintenant le Proxy dans Cloudscraper comme suit :
import cloudscraper
# Créer une instance CloudScraper
scraper = cloudscraper.create_scraper()
# Définir le Proxy Bright Data
proxies = {
"http": "http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335",
"https": "http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335"
}
# Effectuer une requête à l'aide du Proxy
response = Scraper.get("https://httpbin.io/ip", proxies=proxies)
# Afficher la réponse
print(response.text)
N’oubliez pas que les Proxys résidentiels de Bright Data tournent automatiquement. Vous recevrez donc une adresse IP différente à chaque fois que vous exécuterez le script.
Et voilà ! L’intégration du Proxy CloudScraper est terminée.
Conclusion
Dans ce tutoriel, vous avez vu comment utiliser Cloudscraper avec des proxys pour une efficacité maximale. Vous avez couvert les bases de l’intégration des proxys avec l’outil Python Cloudflare-bypass et vous avez également exploré des techniques plus avancées telles que la rotation des proxys.
Il est beaucoup plus facile d’obtenir de meilleurs résultats en utilisant des serveurs Proxy IP de haute qualité provenant d’un fournisseur de premier ordre tel que Bright Data.
Bright Data contrôle les meilleurs Proxy au monde, au service des entreprises du Fortune 500 et de plus de 20 000 clients. Son réseau mondial de Proxy comprend :
- Proxy de centre de données – Plus de 770 000 adresses IP de centres de données.
- Proxys résidentiels– Plus de 150 millions d’IPs résidentielles dans plus de 195 pays.
- Proxy ISP – Plus de 700 000 adresses IP ISP.
- Proxy mobile – Plus de 7 millions d’adresses IP mobiles.
Dans l’ensemble, il s’agit de l’un des réseaux de Proxys les plus vastes et les plus fiables qui soient.
Créez dès aujourd’hui un compte Bright Data gratuit pour essayer nos serveurs Proxy.





