- Scraper basé sur une API
Utilisez notre interface pour créer votre requête d’API - Automatisation à l’échelle
Créez votre propre planificateur pour contrôler la fréquence - Livraison
Livrez les données à l’endroit de votre choix ou téléchargez-les



CNN Scraper
Extrayez les données de CNN telles que l’URL, l’auteur, le titre, les sujets, la date de publication, le contenu, etc.
Aucune carte de crédit requise

- Scrape à la demande via API ou scraper sans code
- Responsable de compte dédié
- Gestion de demandes en masse, jusqu'à 5K URLs
- Récupérer les résultats en plusieurs formats
Approuvé par 20,000+ clients dans le monde entier
Scrapez sans effort les données de CNN

CNN API Scraper
Utilisez cette API pour commencer à collecter des données avec les paramètres spécifiés

CNN Scraper sans code
Utilisez ce scraper « Plug and Play » pour commencer à collecter des données
- Scraper basé sur le panneau de commande
Toute l’interaction se fait dans notre panneau de commande - Facile à utiliser
Ajoutez vos données au scraper et vous êtes prêt à commencer - Récupérer les résultats du panneau de commande
Les résultats peuvent être téléchargés directement à partir du panneau de commande
Option entièrement gérée
Profitez de données sans souci grâce à nos services gérés
Web scrapers
Scrapers disponibles pour CNN et scrapers associés
Ne vous souciez plus du développement et de la gestion de l’infrastructure. Extrayez simplement de gros volumes de données web et garantissez l’évolutivité et la fiabilité des processus à l’aide d’API de scrapers web ou de scrapers sans code.
Vous ne voulez que des données ? Oubliez le scraping.
Achetez un ensemble de données CNN
DÉPLOYEZ PLUS RAPIDEMENT
Un API call. Des tonnes de données.
Découverte des données
Détecter les structures et les modèles de données afin de garantir une extraction efficace et ciblée des données.
Gestion des demandes en bulk
Réduisez la charge du serveur et optimisez la collecte de données pour les tâches de scraping à haut volume.
Analyse des données
Convertit efficacement le HTML brut en données structurées, facilitant ainsi l’intégration et l’analyse des données.
Validation des données
Garantissez la fiabilité des données et gagnez du temps lors des contrôles manuels et du prétraitement.
SOUS LE CAPOT
Ne vous souciez plus jamais des proxies et des CAPTCHA
- Rotation automatique des IP
- Résolution de CAPTCHA
- Rotation des agents utilisateur
- En-têtes personnalisés
- Rendu JavaScript
- Proxys résidentiels
CNN Scraper API Pricing
Only pay for what’s successfully delivered. No hidden fees, no charges for failed deliveries.
Obtenez 25% de réduction sur l'API Scraper pendant 3 mois. Utilisez le code APIS25 lors du paiement.
Nous acceptons ces méthodes de paiement:
Chaque plan vous donne un accès complet - payez moins par enregistrement à mesure que vous augmentez
Collecte de données
- Gestion automatisée des proxies
- Rendu complet du navigateur
- Résolution CAPTCHA
Performance à grande échelle
- Concurrence illimitée
- Collecte par lots et planifiée
- APIs de gestion des tâches
Livraison de données
- Validation et découverte de données
- Analyse de données (JSON ou CSV)
- Livraison via webhook ou API
Web Scraper API demo
LE MEILLEUR DX DE SA CATÉGORIE
Facile à démarrer. Plus facile à mettre à l’échelle.
Stabilité inégalée
Garantissez des performances constantes et minimisez les défaillances en vous appuyant sur la première infrastructure de proxy au monde.
Web Scraping simplifié
Mettez votre scraping en pilote automatique en utilisant des API prêtes à la production, ce qui permet d’économiser des ressources et de réduire la maintenance.
Évolutivité illimitée
Adaptez sans effort vos projets de scraping pour répondre aux demandes de données, tout en maintenant des performances optimales.
API pour un accès fluide aux données CNN
Extraction de données web complète, évolutive et conforme
API pour un accès fluide aux données CNN
Extraction de données web complète, évolutive et conforme
Adapté à votre flux de travail
Obtenez des données structurées en fichiers JSON, NDJSON ou CSV via Webhook ou livraison par API.
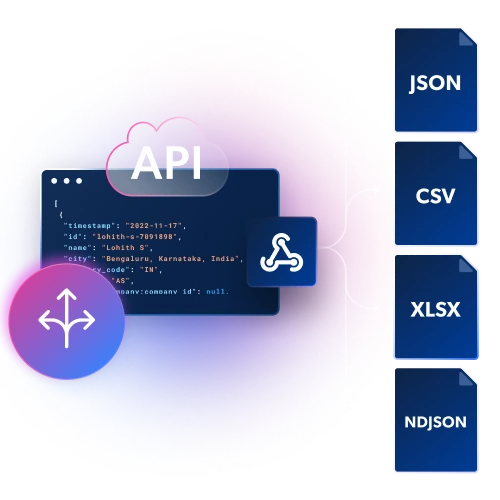
Infrastructure intégrée et déblocage
Bénéficiez d’un contrôle et d’une flexibilité maximaux sans maintenir de Proxy ni d’infrastructure de déblocage. Scrapez facilement des données depuis n’importe quelle géolocalisation en évitant les CAPTCHAs et les blocages.

Infrastructure éprouvée
La plateforme de Bright Data alimente plus de 20 000 entreprises dans le monde, offrant une tranquillité d’esprit avec 99,99 % de disponibilité et l’accès à plus de 150 M d’IPs d’utilisateurs réels couvrant 195 pays.

Conformité de premier plan dans le secteur
Nos pratiques de confidentialité respectent les lois sur la protection des données, notamment le cadre réglementaire européen de protection des données, le RGPD et le CCPA.

API pour un accès fluide aux données CNN
Extraction de données web complète, évolutive et conforme
FLEXIBLE
Adapté à votre flux de travail
Obtenez des données structurées en fichiers JSON, NDJSON ou CSV via Webhook ou livraison par API.SCALABLE
Infrastructure intégrée et déblocage
Bénéficiez d'un contrôle et d'une flexibilité maximaux sans maintenir de Proxy ni d'infrastructure de déblocage. Scrapez facilement des données depuis n'importe quelle géolocalisation en évitant les CAPTCHAs et les blocages.STABLE
Infrastructure éprouvée
La plateforme de Bright Data alimente plus de 20 000 entreprises dans le monde, offrant une tranquillité d'esprit avec 99,99 % de disponibilité et l'accès à plus de 150 M d'IPs d'utilisateurs réels couvrant 195 pays.COMPLIANT
Conformité de premier plan dans le secteur
Nos pratiques de confidentialité respectent les lois sur la protection des données, notamment le cadre réglementaire européen de protection des données, le RGPD et le CCPA.Cas d’utilisation de l’API CNN Scraper
Scrape CNN to optimize your marketing strategy.
Use our CNN scraper to make smarter marketing decisions.
Collect CNN data to enrich your systems with fresh news.
Collect headlines, content, authors, and more from CNN.
Pourquoi 20,000+ clients choisissent Bright Data
100% Conforme
Les données collectées sont obtenues de manière éthique et conformes à toutes les lois sur la vie privée.
Support mondial 24/7
Une équipe dédiée de professionnels des données est là pour vous aider.
Couverture complète des données
Accédez à 400 million+ IPs mondiales pour extraire des données de n'importe quel site web.
Qualité de données inégalée
Technologies avancées et méthodes de validation pour des données de qualité.
Infrastructure puissante
Extrayez des données en grand volume sans être bloqué.
Solutions personnalisées
Obtenez des solutions adaptées à vos besoins et objectifs spécifiques.
Bright Data est utilisé par les meilleures marques mondiales
Nous aidons les entreprises à se développer grâce à une gestion des données sécurisée, évolutive et flexible.
Vous voulez en savoir plus ?
Contactez un de nos experts pour discuter de vos besoins en matière de web scraping
FAQ sur l’API CNN Scraper
Qu’est-ce que l’API CNN Scraper ?
L’API CNN Scraper est un outil puissant conçu pour automatiser l’extraction de données depuis le site Web de CNN et qui permet aux utilisateurs de collecter et de traiter efficacement de grands volumes de données pour divers cas d’utilisation.
Comment fonctionne l’API CNN Scraper ?
L’API CNN Scraper fonctionne en envoyant des requêtes automatisées au site web de CNN, en extrayant les points de données nécessaires et en les livrant dans un format structuré. Ce processus garantit une collecte de données précise et rapide.
Quels points de données peuvent être collectés avec l’API CNN Scraper ?
Les points de données qui peuvent être collectés avec l’API CNN Scraper comprennent les titres, l’auteur, les sujets, la date de publication, le contenu, les images, les articles connexes, les mots-clés, et bien plus encore.
L’API CNN Scraper est-elle conforme aux réglementations en matière de protection des données ?
Oui, l’API CNN Scraper est conçue pour respecter les réglementations en matière de protection des données, notamment le RGPD et le CCPA. Cela garantit que toutes les activités de collecte de données sont effectuées de manière éthique et légale.
Puis-je utiliser l’API CNN Scraper pour effectuer des analyses concurrentielles ?
Absolument ! L’API CNN Scraper est idéale pour l’analyse concurrentielle, car elle vous permet de recueillir des informations sur les activités, les tendances et les stratégies de vos concurrents.
Comment puis-je intégrer l’API CNN Scraper à mes systèmes existants ?
L’API CNN Scraper offre une intégration parfaite avec diverses plateformes et outils. Vous pouvez l’utiliser avec vos pipelines de données, vos systèmes CRM ou vos outils d’analyse existants pour améliorer votre capacité de traitement des données.
Quelles sont les limites d’utilisation de l’API CNN Scraper ?
Il n’existe aucune limite d’utilisation spécifique pour l’API CNN Scraper, ce qui vous permet d’adapter vos opérations de scraping en fonction de vos besoins. Les tarifs commencent à partir de 0,001 $ par enregistrement, ce qui garantit une évolutivité rentable pour vos projets de web scraping.
Offrez-vous une assistance pour l’API CNN Scraper ?
Oui, nous offrons un service d’assistance dédié pour l’API CNN Scraper. Notre équipe d’assistance joignable 24 heures sur 24 et 7 jours sur 7 se tient prête à répondre à toutes vos questions et à vous aider à résoudre tous les problèmes que vous pourriez rencontrer en utilisant l’API.
Quels sont les modes de livraison disponibles ?
S3, Google Cloud Storage, Google PubSub, Microsoft Azure Storage, Snowflake et SFTP.
Quels sont les formats de fichiers disponibles ?
JSON, NDJSON, JSON Lines, CSV et fichiers .gz (compressés).