
TL;DR: Ce tutoriel vous apprendra comment extraire les données d’un site dans Ruby et pourquoi il s’agit de l’un des langages les plus efficaces pour le web scraping.
Dans ce guide, nous parlerons des points suivants :
- Ruby convient-il pour le web scraping ?
- Les meilleurs gems de Ruby pour le web scraping
- Construction d’un web scraper en Ruby
Ruby convient-il pour le web scraping ?
Ruby est un langage de programmation interprété, open-source et de type dynamique, qui prend en charge le développement fonctionnel, orienté objet et procédural. Il est conçu pour être simple, avec une syntaxe élégante qui est facile à écrire et naturelle à lire. Son accent sur la productivité en a fait un choix privilégié pour diverses applications, notamment le web scraping.
En particulier, Ruby est un excellent choix pour le web scraping, du fait de la panoplie étendue de bibliothèques tierces disponibles. On appelle ces bibliothèques « gems » (gemmes) ; et il y en a une pour presque toutes les tâches. Lorsque vous avez besoin de récupérer des informations sur Internet par programmation, certains gems permettent de télécharger des pages, analyser leur contenu HTML et en extraire les données.
En résumé, le web scraping dans Ruby est non seulement possible mais aussi facile grâce aux nombreuses bibliothèques disponibles. Découvrons celles qui sont les plus populaires.
Les meilleurs gems de Ruby pour le web scraping
Voici les trois meilleures bibliothèques Ruby pour le web scraping :
- Nokogiri(鋸) : une bibliothèque d’analyse HTML et XML robuste et flexible avec une API complète pour parcourir et manipuler des documents HTML/XML, et qui facilite donc l’extraction de données pertinentes.
- Mechanize : une bibliothèque avec une fonctionnalité de navigateur sans tête, qui fournit une API de haut niveau pour automatiser les interactions avec les sites web. Elle peut stocker et envoyer des cookies, gérer des redirections, suivre des liens et envoyer des formulaires. En outre, elle fournit un historique permettant de garder une trace des sites visités.
- Selenium : bibliothèque populaire utilisée avec Ruby pour exécuter des tests automatisés sur des pages web. Selenium peut demander à un navigateur d’interagir avec un site web comme le ferait un utilisateur humain. Cette technologie joue un rôle clé dans le contournement des solutions anti-bot et l’extraction des données de sites qui s’appuient sur JavaScript pour le rendu ou la récupération de données.
Prérequis
Avant d’écrire du code, vous devez installer Ruby sur votre machine. Suivez ci-dessous le guide relatif à votre système d’exploitation.
Installation de Ruby sur MacOS
Par défaut, Ruby est inclus dans MacOS depuis la version 10.11 (El Capitan), publiée en 2015. Étant donné que MacOS s’appuie en natif sur Ruby pour fournir certaines fonctionnalités, vous ne devez pas y toucher. Il n’est pas recommandé de mettre à jour la version native de Ruby en installant Ruby avec Homebrew sur un Mac, car cela peut compromettre certaines fonctionnalités intégrées.
Installation de Ruby sous Windows
Téléchargez le package Rubyinstaller, lancez-le et suivez l’assistant d’installation pour configurer Ruby. Un redémarrage du système peut s’avérer nécessaire. À partir de Windows 10, vous pouvez également utiliser le Sous-système Windows pour Linux afin d’installer Ruby en suivant les instructions ci-dessous.
Installation de Ruby sur Linux
La meilleure façon de configurer un environnement Ruby sous Linux est de l’installer via un gestionnaire de packages.
Dans Debian et Ubuntu, lancez :
sudo apt-get install ruby-fullDans les autres distributions, la commande de terminal à exécuter est différente. Consultez le guide sur le site officiel pour voir tous les systèmes de gestion de packages pris en charge.
Quel que soit votre système d’exploitation, vous pouvez maintenant vérifier que Ruby fonctionne en écrivant :
ruby -vCela devrait renvoyer quelque chose comme :
ruby 3.2.2 (2023-03-30 revision e51014f9c0)Bien ! Vous êtes maintenant prêt à vous lancer dans le web scraping avec Ruby.
Construction d’un web scraper en Ruby
Dans cette section, vous découvrirez comment créer un web scraper en Ruby. Ce script automatisé extraira des données de la page d’accueil de Bright Data. Plus précisément, il vous permet d’effectuer les actions suivantes :
- Connexion au site web cible
- Sélection des éléments HTML qui vous intéressent dans le DOM
- Extraction des données de ces éléments
- Conversion des données collectées dans des formats faciles à consulter, par exemple CSV ou JSON
À l’heure où nous écrivons ces lignes, voici ce que les utilisateurs voient lorsqu’ils visitent la page web cible :
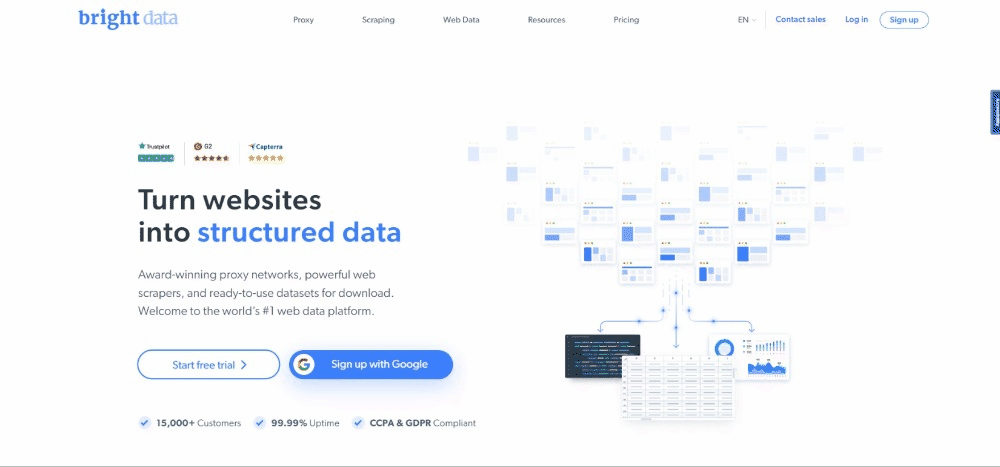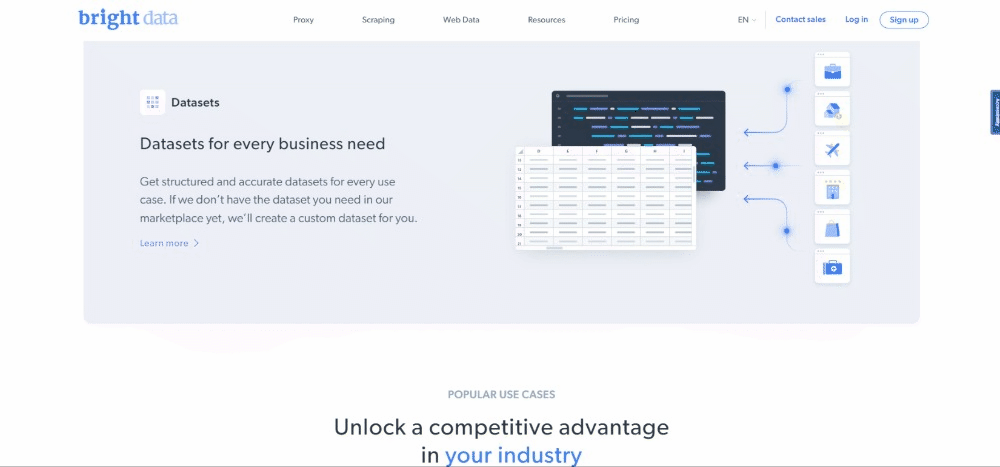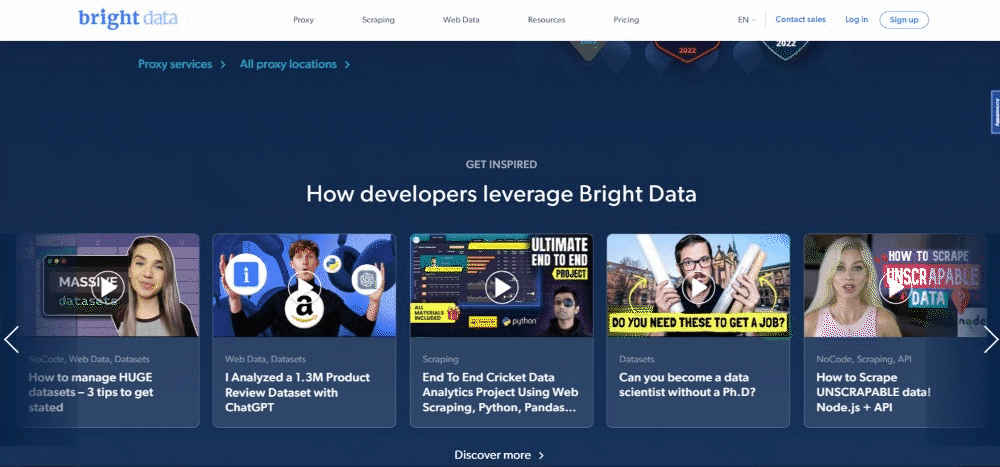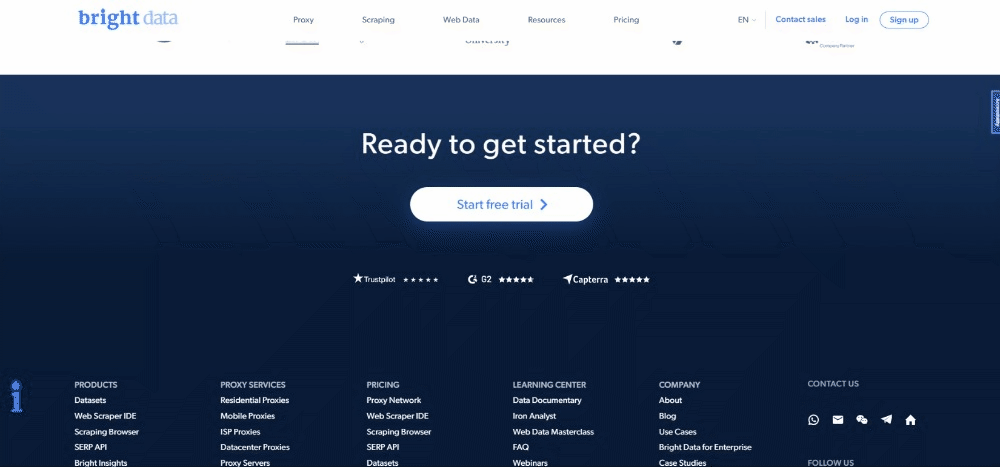
Il convient de tenir compte du fait que la page d’accueil de Bright Data est fréquemment modifiée et peut ne pas être la même qu’au moment de la lecture de cet article.
L’objectif spécifique du scraping est d’obtenir des informations relatives aux cas d’utilisation, contenues dans les cartes suivantes :
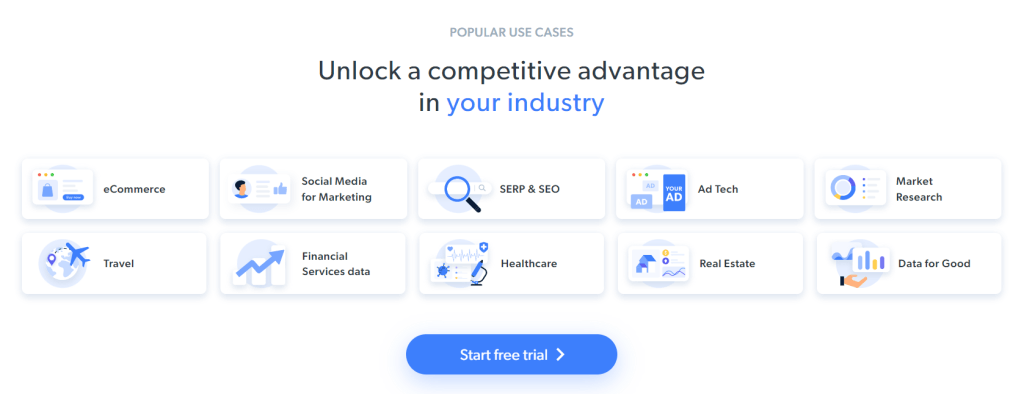
Suivez le tutoriel ci-dessous étape par étape pour apprendre à faire du web scraping avec Ruby.
Étape 1 : initialisation d’un projet Ruby
Avant de commencer, vous devez configurer votre projet Ruby. Lancez le terminal, créez le dossier du projet puis entrez :
mkdir ruby-web-scraper
cd ruby-web-scraperLe répertoire ruby-web-scraper contient votre web scraper.
Ensuite, initialisez un fichier scraper.rb dans le dossier du projet, avec le contenu suivant :
puts "Hello, World!"L’extrait de code ci-dessus est le script Ruby le plus facile qui soit.
Vérifiez qu’il fonctionne en lançant sur votre terminal :
ruby scraper.rbCela devrait renvoyer le message suivant :
Hello, World!Il est temps d’importer votre projet dans votre EDI et de commencer à définir une logique de web scraping avancée sous Ruby. Dans ce guide, vous apprendrez à configurer Visual Studio Code (VS Code) pour le développement en Ruby. Cela étant, n’importe quel autre EDI Ruby fera l’affaire.
Comme VS Code ne prend pas en charge Ruby nativement, vous devez d’abord ajouter l’extension Ruby. Démarrez Visual Studio Code, cliquez sur l’icône « Extensions » sur la barre de gauche, puis tapez « Ruby » dans le champ de recherche en haut.
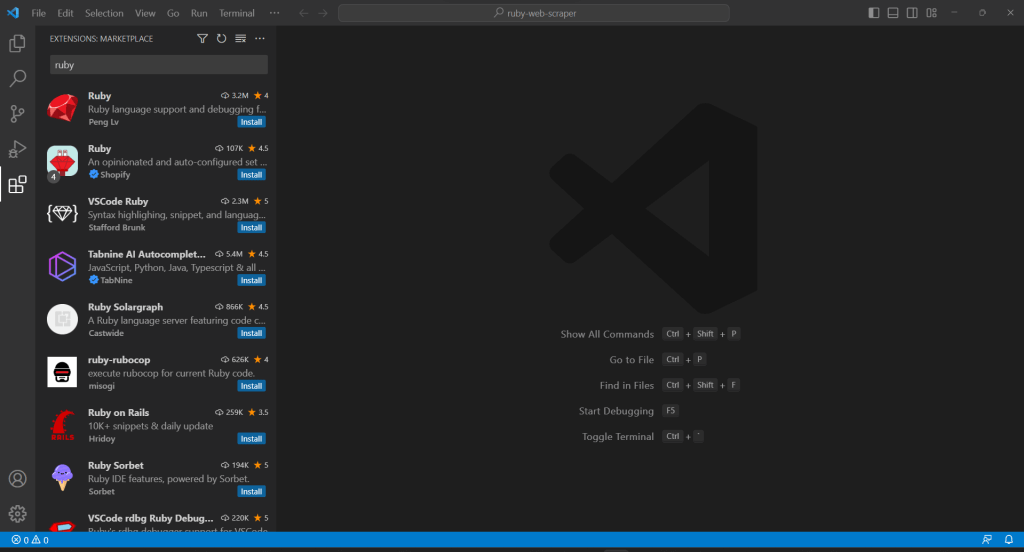
Cliquez sur le bouton « Installer » du premier élément pour ajouter des fonctionnalités de mise en évidence Ruby dans le code VS. Attendez que le plug-in soit ajouté à l’EDI. Ouvrez ensuite le dossier ruby-web-scraper avec « Fichier », « Ouvrir le dossier… ».
Cliquez sur le fichier scraper.rb sous la barre « EXPLORER » pour commencer à modifier le fichier :
Étape 2 : choix d’une bibliothèque de web scraping
La création d’un web scraper en Ruby devient plus facile avec la bibliothèque appropriée. Pour cette raison, vous avez intérêt à adopter l’un des gems présentés ci-dessus. Pour trouver la bibliothèque Ruby de web scraping qui correspond le mieux à vos objectifs, vous devez prendre un moment pour analyser votre site cible.
Rendez-vous donc sur la page cible dans votre navigateur, cliquez avec le bouton droit de la souris sur un emplacement vide en arrière-plan, puis cliquez sur l’option « Inspecter ». Cela lance les DevTools de votre navigateur. Dans Chrome, accédez à l’onglet « Network » et explorez la section « Fetch/XHR ».
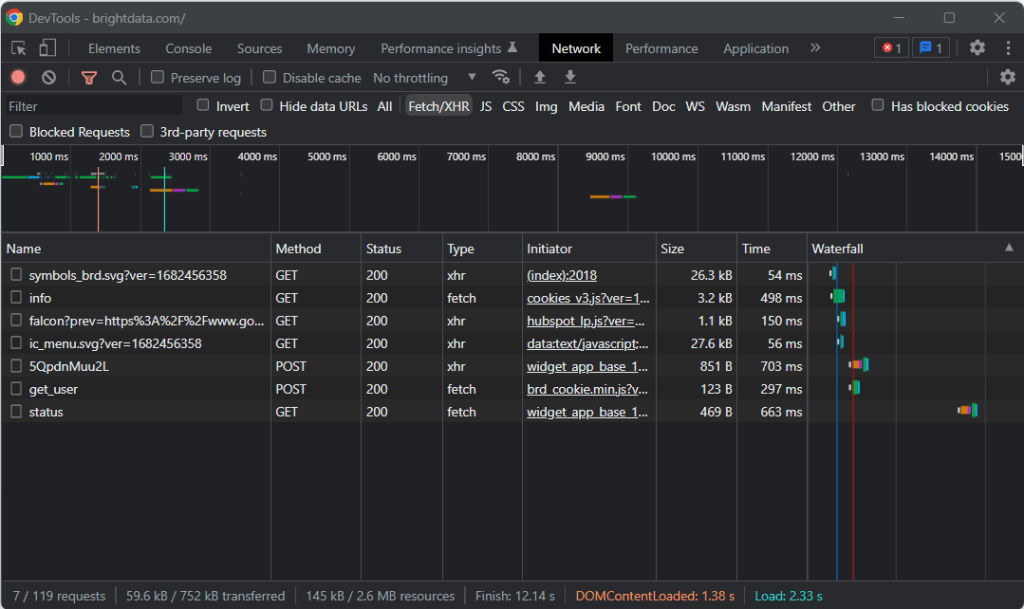
Comme vous pouvez le constater dans la capture d’écran ci-dessus, il n’y a que sept requêtes AJAX. Dans chaque appel XHR, vous remarquerez qu’il n’y a pas de données significatives. Cela signifie que la page cible ne récupère pas de contenu au moment du rendu. De ce fait, le document HTML renvoyé par le serveur contient déjà toutes les données à afficher aux utilisateurs.
Cela prouve que la page cible n’utilise pas JavaScript à des fins de récupération ou de rendu des données. En d’autres termes, vous n’avez pas besoin d’un gem qui a des capacités de navigateur sans tête pour faire du web scraping. Vous pouvez quand même utiliser Mechanize ou Selenium, mais cela n’introduirait qu’une surcharge au niveau des performances. En effet, ils exécutent une instance de navigateur en arrière-plan, ce qui consomme des ressources.
En bref, vous avez plutôt intérêt à opter pour un analyseur HTML/XML simple comme Nokogiri. Installez-le via le gem Nokogiri avec :
gem install nokogiriVous pouvez ensuite importer la bibliothèque en ajoutant la ligne suivante en haut de votre fichier scraper.rb :
require "nokogiri"Assurez-vous que votre EDI Ruby ne signale pas d’erreurs ; vous êtes maintenant prêts à collecter des données avec Ruby.
Étape 3 : utilisation de HTTParty pour obtenir la page cible
Pour analyser le document HTML de la page cible, vous devez d’abord le télécharger via une requête HTTP GET. Ruby est fourni avec un client HTTP intégré appelé Net::HTTP, mais sa syntaxe est un peu lourde et peu intuitive. Vous avez plutôt intérêt à utiliser HTTParty, qui est la bibliothèque Ruby la plus populaire pour exécuter des requêtes HTTP.
Installez-le via le gem httparty avec :
gem install httparty
Then, import it in the scraper.rb file:
require "httparty"
Use HTTParty to connect to the target page with:
response = HTTParty.get("https://brightdata.com/")La méthode get() vous permet d’exécuter une requête GET sur l’URL passée par paramètre. Le champ response.body contient le document HTML renvoyé par le serveur.
Notez que la requête HTTP effectuée via get() peut échouer. Lorsque cela se produit, HTTParty génère une exception et arrête l’exécution de votre script avec une erreur. Un échec peut avoir un certain nombre de raisons, mais le cas le plus fréquent est l’interception et le blocage de vos requêtes automatisées par une technologie anti-bot utilisée par le site cible. Les systèmes anti-scraping les plus basiques ont tendance à rejeter les requêtes sans en-tête HTTP d’agent utilisateur valide. Jetez un coup d’œil à notre article pour mieux comprendre le problème des agents utilisateur pour le web scraping.
Comme tout autre client HTTP, HTTParty utilise un paramètre substituable User-Agent. Celui-ci est généralement très différent des agents utilisés par les navigateurs couramment employés, ce qui rend ses requêtes facilement détectables par les solutions anti-bot. Pour éviter de vous faire bloquer à cause de cela, vous pouvez spécifier un agent utilisateur valide dans HTTParty de la manière suivante :
response = HTTParty.get("https://brightdata.com/", {
headers: { "User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"},
})La requête effectuée via get() apparaîtra maintenant sur le serveur comme provenant de Google Chrome 112.
Voici ce que contient actuellement le fichier scraper.rb :
require "nokogiri"
require "httparty"
# get the target page
response = HTTParty.get("https://brightdata.com/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
},
})
# scraping logic...Étape 4 : analyse du document HTML avec Nokogiri
Pour analyser le document HTML associé à la page web cible, passez son contenu à la fonction Nokogiri HTML() :
doc = Nokogiri::HTML(response.body)Vous pouvez désormais utiliser l’API d’exploration et de manipulation du DOM proposée via la variable doc. Plus précisément, les deux méthodes les plus importantes pour sélectionner des éléments HTML sont :
- xpath() : renvoie la liste des nœuds HTML correspondant à la requête XPath
- css() : renvoie la liste des nœuds HTML correspondant au sélecteur CSS passé par paramètre
Les deux approches fonctionnent, mais les requêtes CSS permettent généralement d’exprimer plus facilement ce que vous recherchez.
Étape 5 : définition des sélecteurs CSS pour les éléments HTML qui vous intéressent
Pour comprendre comment sélectionner les éléments HTML souhaités sur la page cible, vous devez analyser le DOM. Accédez à la page d’accueil de Bright Data dans votre navigateur, cliquez avec le bouton droit de la souris sur l’une des cartes d’intérêt et sélectionnez « Inspecter » :
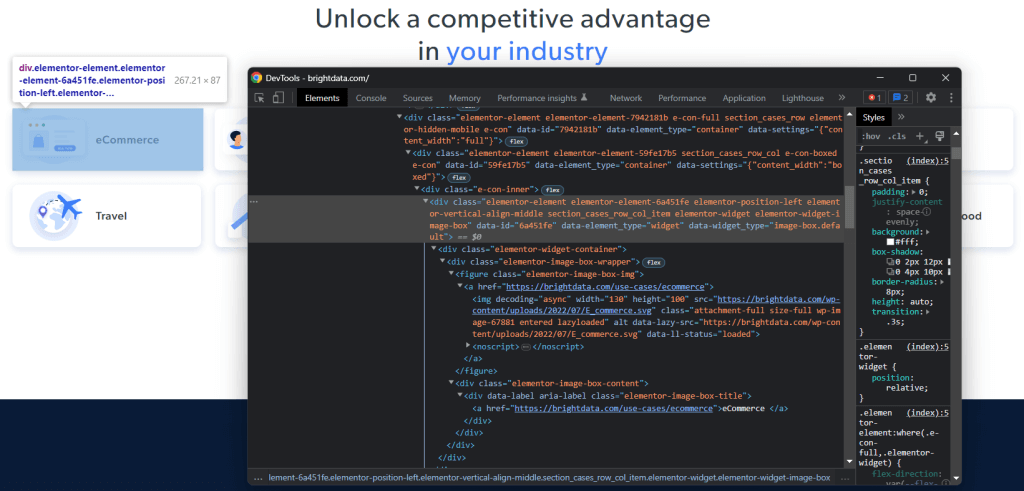
Prenez le temps d’explorer le code HTML dans la section DevTools. Chaque carte de cas d’utilisation est un
- Une <figure> contenant un élément HTML <img> qui présente l’image associée au secteur d’activité considéré et un élément <a> contenant l’URL de la page de ce secteur d’activité.
- Un élément <div> HTML contenant le nom du secteur d’activité dans une balise <a>.
L’objectif de l’extraction de données du web scraper Ruby est d’obtenir l’URL de l’image, l’URL de la page et le nom du secteur d’activité correspondant à chaque carte.
Pour définir de bons sélecteurs CSS, vous devez examiner les classes CSS affectées aux nœuds DOM d’intérêt. Vous remarquerez que vous pouvez obtenir toutes les cartes des cas d’utilisation avec le sélecteur CSS suivant :
.section_cases_row_col_itemÀ partir d’une carte donnée, vous pouvez sélectionner les nœuds dans lesquels sont stockés les données pertinentes à partir de ses enfants <figure> et <div>, avec :
- figure img
- figure a
- .elementor-image-box-content a
Étape 6 : extraction des données d’une page web avec Nokogiri
Vous devez maintenant utiliser Nokogiri pour récupérer les données souhaitées sur la page HTML cible.
Avant de vous plonger dans la logique de web scraping, n’oubliez pas que vous avez besoin de structures de données dans lesquelles stocker les données collectées. A cet effet, vous pouvez définir une classe UseCase sur une seule ligne avec une Struct :
UseCase = Struct.new(:image, :url, :name)Dans Ruby, une Struct vous permet de regrouper un ou plusieurs attributs dans la même classe de données. La Struct ci-dessus possède les trois attributs correspondant aux informations à extraire de chaque carte de cas d’utilisation.
Initialisez un tableau vide d’UseCase et implémentez la logique de web scraping pour le remplir :
# initialize the list of objects
# that will store all retrieved data
use_cases = []
# select all use case HTML elements
use_case_cards = doc.css(".section_cases_row_col_item")
# iterate over the HTML cards
use_case_cards.each do |use_case_card|
# extract the data of interest
image = use_case_card.at_css("figure img").attribute("data-lazy-src").value
url = use_case_card.at_css("figure a").attribute("href").value
name = use_case_card.at_css(".elementor-image-box-content a").text
# instantiate an UseCase object with the
# collected data
use_case = UseCase.new(url, image, name)
# add the UseCase instance to the array
# of scraped objects
use_cases.push(use_case)
endL’extrait de code ci-dessus sélectionne toutes les cartes de cas d’utilisation et effectue une itération sur elles. Il extrait ensuite de chaque carte l’URL de l’image, l’URL et le nom de la page de secteur d’activité avec at_CSS(). Il s’agit d’une fonction Nokogiri qui renvoie le premier élément correspondant à la requête CSS et représente un raccourci pour :
image = use_case_card.css("figure img").first.attribute("data-lazy-src").valueEnfin, il utilise les données récupérées pour instancier un nouvel objet UseCase, qu’il ajoute à la liste.
Le web scraping en Ruby est assez simple avec Nokogiri. Avec attribute(), vous pouvez sélectionner un attribut dans l’élément HTML courant. Par la suite, le champ value vous permet d’obtenir sa valeur. De même, la zone de texte renvoie directement tout le texte contenu dans le nœud HTML courant sous la forme d’une chaîne de caractères.
Maintenant, vous pourriez aller plus loin et collecter aussi des données sur les pages consacrés aux secteurs d’activité. Vous pouvez suivre les liens découverts ici et mettre en œuvre une nouvelle logique de web scraping adaptée à eux. Bienvenue dans l’univers du web crawling et du web scraping !
Parfait ! Vous venez d’apprendre à effectuer vos tâches de web scraping avec Ruby. Il vous reste cependant quelques leçons à apprendre.
Étape 7 : exportation des données extraites
Après la boucle each(), use_cases contiendra les données extraites dans des objets Ruby. Ce n’est pas le meilleur format pour fournir des données à d’autres équipes. Heureusement, Ruby est fourni avec des fonctionnalités intégrées de conversion en CSV et en JSON. Découvrez comment exporter les données récupérées au format CSV et JSON.
Pour l’exportation au format CSV, importez le gem suivant :
import "csv"Il fait partie de l’API standard de Ruby et fournit une interface complète pour traiter les fichiers et les données CSV.
Vous pouvez vous en servir de la manière suivante pour exporter le tableau use_cases dans un fichier output.csv :
# populate the CSV output file
CSV.open("output.csv", "wb") do |csv|
# write the CSV header
csv << ["url", "image", "name"]
# transfrom each use case scraped info to a
# CSV record
use_cases.each do |use_case|
csv << use_case
end
endL’extrait de code ci-dessus crée le fichier output.csv. Puis il l’ouvre et l’initialise avec l’enregistrement d’en-tête. Ensuite, il effectue une itération sur le tableau use_cases et ajoute les données au fichier CSV. Lorsque vous utilisez l’opérateur <<, Ruby convertit automatiquement chaque instance use_case en un tableau de chaînes, comme l’exige la classe CSV intégrée.
Essayez d’exécuter le script avec :
ruby scraper.rbUn fichier output.csv contenant les données ci-dessous sera généré dans le répertoire racine de votre projet :
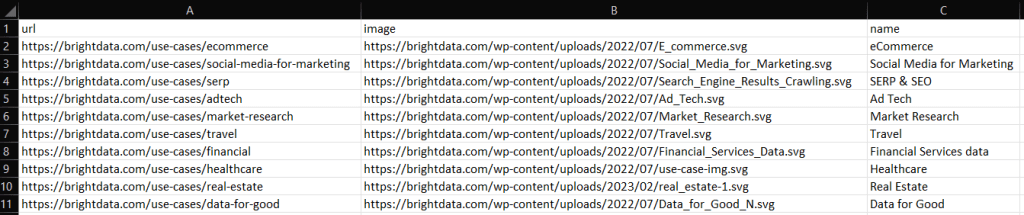
De même, vous pouvez exporter use_cases vers un fichier output.json :
# propulate the JSON output file
File.open("output.json", "wb") do |json|
json << JSON.pretty_generate(use_cases.map { |u| Hash[u.each_pair.to_a] })
endCela générera le fichier JSON suivant :
[
{
"image": "https://brightdata.com/use-cases/ecommerce",
"url": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"name": "eCommerce "
},
// ...
{
"image": "https://brightdata.com/use-cases/data-for-good",
"url": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"name": "Data for Good"
}
]Et voilà ! Vous savez maintenant convertir un tableau de Structs en CSV et en JSON avec Ruby.
Étape 8 : au final
Voici le code complet du web scrapper Ruby :
# scraper.rb
require "nokogiri"
require "httparty"
require "csv"
# get the target page
response = HTTParty.get("https://brightdata.com/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
},
})
# parse the HTML document retrieved with the GET request
doc = Nokogiri::HTML(response.body)
# define a class where to keep the scraped data
UseCase = Struct.new(:image, :url, :name)
# initialize the list of objects
# that will store all retrieved data
use_cases = []
# select all use case HTML elements
use_case_cards = doc.css(".section_cases_row_col_item")
# iterate over the HTML cards
use_case_cards.each do |use_case_card|
# extract the data of interest
image = use_case_card.at_css("figure img").attribute("data-lazy-src").value
url = use_case_card.at_css("figure a").attribute("href").value
name = use_case_card.at_css(".elementor-image-box-content a").text
# instantiate an UseCase object with the
# collected data
use_case = UseCase.new(url, image, name)
# add the UseCase instance to the array
# of scraped objects
use_cases.push(use_case)
end
# populate the CSV output file
CSV.open("output.csv", "wb") do |csv|
# write the CSV header
csv << ["url", "image", "name"]
# transfrom each use case scraped info to a
# CSV record
use_cases.each do |use_case|
csv << use_case
end
end
# propulate the JSON output file
File.open("output.json", "wb") do |json|
json << JSON.pretty_generate(use_cases.map { |u| Hash[u.each_pair.to_a] })
endEn environ 50 lignes de code, vous pouvez créer un script de web scraping en Ruby.
Conclusion
Dans ce tutoriel, vous avez appris pourquoi Ruby est un excellent langage pour le web scraping. Vous avez également eu l’occasion de découvrir les meilleures bibliothèques de Ruby pour le web scraping et les fonctionnalités qu’elles proposent. Ensuite, vous avez appris plus en détail à utiliser Nokogiri et l’API standard de Ruby pour construire en Ruby un web scraper capable de collecter des données sur une cible réelle. Comme vous venez de le voir, le web scraping sous Ruby ne nécessite que quelques lignes de code.
Cependant, ne sous-estimez pas les défis que vous pouvez rencontrer si vous tentez d’extraire des données sur des pages web. En effet, un nombre croissant de sites mettent en œuvre des systèmes anti-bot et anti-scraping pour protéger leurs données. Ces technologies sont capables de détecter les requêtes effectuées par votre script de web scraping Ruby et d’empêcher l’accès au site. Heureusement, vous pouvez construire un web scraper capable de contourner ces blocs avec le Web Scraper IDE, qui est l’environnement de développement intégré nouvelle génération de Bright Data.
Vous ne voulez pas du tout vous occuper de web scraping, mais vous êtes intéressés par les données web ? Découvrez nos jeux de données prêts à l’emploi.




