

Si vous pratiquez le Scraping web depuis un certain temps, vous avez peut-être déjà rencontré un site web bloqué derrière une barrière géographique ou une interdiction d’adresse IP. Les Proxy vous aident à contourner ces situations en masquant votre véritable identité et en vous donnant accès à des ressources interdites.
Les serveurs ProxyRust vous permettent d’effectuer facilement les opérations suivantes :
- Éviter les interdictions d’adresse IP : une nouvelle adresse Proxy vous permet de contourner l’interdiction et de reprendre le scraping.
- Contourner les géoblocages : si vous êtes intéressé par le contenu d’un autre pays, un Proxy local vous accorde une citoyenneté en ligne temporaire, vous permettant d’accéder au contenu restreint.
- Profitez de l’anonymat : un Proxy masque votre adresse IP réelle, protégeant ainsi votre vie privée des regards indiscrets.
Et ce n’est que la partie émergée de l’iceberg ! Les puissantes bibliothèques et la syntaxe robuste de Rust facilitent la configuration et la gestion des Proxies. Dans cet article, vous apprendrez tout sur les serveurs Proxy et comment utiliser un serveur Proxy dans Rust pour le Scraping web.
Utilisation d’un Proxy dans Rust
Avant de pouvoir utiliser un Proxy dans Rust, vous devez en configurer un. Dans ce tutoriel, vous allez configurer un Proxy dans un serveur Nginx sur votre machine locale et l’utiliser pour envoyer des requêtes de scraping à un bac à sable de scraping (tel que https://toscrape.com/) à partir d’un binaire Rust.
Commencez par installer Nginx sur votre système local. Sous Linux, vous pouvez l’installer à l’aide de Homebrew avec la commande suivante :
sudo apt install nginxDémarrez ensuite le serveur à l’aide de la commande suivante :
nginx
Ensuite, vous devez configurer le serveur pour qu’il agisse comme un Proxy pour certains emplacements. Par exemple, vous pouvez le configurer pour qu’il fonctionne comme un Proxy pour l’emplacement / et ajouter un en-tête (c’est-à-dire X-Proxy-Server) à chaque requête qu’il traite. Pour ce faire, vous devez modifier le fichier nginx.conf.
L’emplacement du fichier varie en fonction de votre système d’exploitation hôte. Reportez-vous à la documentation Nginx pour obtenir de l’aide. Sous Linux, vous trouverez nginx.conf dans /etc/nginx/nginx.conf. Ouvrez-le et ajoutez le bloc de code suivant à l’objet http.server dans le fichier :
http {
server {
# Ajoutez le bloc suivant
location / {
resolver 8.8.8.8;
Proxy_Pass http://$http_host$request_uri;
Proxy_Set_Header 'X-Proxy-Server' 'Nginx';
}
}
}
Cela configure le Proxy pour qu’il transfère toutes les requêtes entrantes vers l’URL d’origine tout en ajoutant un en-tête à la requête. Si vous aviez accès aux journaux sur le serveur cible, vous pourriez vérifier cet en-tête pour vérifier si la requête est passée par le Proxy ou provient directement du client.
Maintenant, exécutez la commande suivante pour redémarrer le serveur Nginx :
nginx -s reload
Ce serveur est désormais prêt à être utilisé comme Proxy de transfert pour le scraping.
Création d’un projet de Scraping web dans Rust
Pour configurer un nouveau projet de scraping, créez un nouveau binaire Rust à l’aide de Cargo en exécutant la commande suivante :
cargo new rust-scraper
Une fois le projet créé, vous devez ajouter trois crates. Pour commencer, ajoutez reqwest et Scraper. Vous utilisez reqwest pour envoyer des requêtes à la ressource cible et Scraper pour extraire les données requises du HTML reçu par reqwest. Ensuite, vous ajoutez votre troisième crate, tokio, pour gérer les appels réseau asynchrones via reqwest.
Pour les installer, exécutez la commande suivante dans le répertoire du projet :
cargo add Scraper reqwest tokio --features "reqwest/blocking tokio/full"
Ensuite, ouvrez le fichier src/main.rs et ajoutez le code suivant :
use reqwest;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>>{
let url = "http://books.toscrape.com/";
let client = reqwest::Client::new();
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
fn extract_products(html_content: &str) {
let document = scraper::Html::parse_document(&html_content);
let html_product_selector = scraper::Selector::parse("article.product_pod").unwrap();
let html_products = document.select(&html_product_selector);
let mut products: Vec<PRODUCT> = Vec::new();
for html_product in html_products {
let url = html_product
.select(&Scraper::Selector::parse("a").unwrap())
.next()
.and_then(|a| a.value().attr("href"))
.map(str::to_owned);
let image = html_product
.select(&scraper::Selector::parse("img").unwrap())
.next()
.and_then(|img| img.value().attr("src"))
.map(str::to_owned);
let name = html_product
.select(&Scraper::Selector::parse("h3").unwrap())
.next()
.map(|title| title.text().collect::<STRING>());
let price = html_product
.select(&Scraper::Selector::parse(".price_color").unwrap())
.next()
.map(|price| price.text().collect::<STRING>());
let product = Product {
url,
image,
name,
price,
};
products.push(product);
}
println!("{:?}", products);
}
#[derive(Debug)]
struct Product {
url: Option<String>,
image: Option<String>,
name: Option<String>,
price: Option<String>,
}
Ce code utilise le crate reqwest pour créer un client et obtenir la page web à l’URL https://books.toscrape.com. Il traite ensuite le code HTML de la page dans une fonction intitulée extract_products afin d’extraire une liste de produits de la page. La logique d’extraction est implémentée à l’aide du crate Scraper et reste inchangée, que vous utilisiez ou non un Proxy.
Il est maintenant temps d’essayer d’exécuter ce binaire pour voir s’il extrait correctement la liste des produits. Pour ce faire, exécutez la commande suivante :
cargo run
Vous devriez voir un résultat similaire à celui-ci dans votre terminal :
Finished dev [unoptimized + debuginfo] target(s) in 0.80s
Running `target/debug/rust_scraper`
[Produit { url : Some("catalogue/a-light-in-the-attic_1000/index.html"), image : Some("media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg"), nom : Some("A Light in the ..."), prix : Some("£51.77") }, Produit { url: Some("catalogue/tipping-the-velvet_999/index.html"), image: Some("media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg"), name: Some("Tipping the Velvet"), price: Some("53,74 £") }, Product { url: Some("catalogue/soumission_998/index.html"), image: Some("media/cache/3e/ef/3eef99c9d9adef34639f510662022830.jpg"), name: Some("Soumission"), price: Some("£50.10") }, Product { url : Some(« catalogue/sharp-objects_997/index.html »), image : Some(« media/cache/32/51/3251cf3a3412f53f339e42cac2134093.jpg »), nom : Some(« Sharp Objects »), prix : Some("47,82 £") }, Produit { url: Some("catalogue/sapiens-a-brief-history-of-humankind_996/index.html"), image: Some("media/cache/be/a5/bea5697f2534a2f86a3ef27b5a8c12a6.jpg"), name: Some("Sapiens: A Brief History ..."), price: Some("£54.23") }, Product { url : Some("catalogue/the-requiem-red_995/index.html"), image : Some("media/cache/68/33/68339b4c9bc034267e1da611ab3b34f8.jpg"), nom : Some("The Requiem Red"), prix : Some("22,65 £") }, Produit { url: Some("catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"), image: Some("media/cache/92/27/92274a95b7c251fea59a2b8a78275ab4.jpg"), name: Some("The Dirty Little Secrets ..."), price: Some("£33.34") }, Product { url : Some("catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html"), image : Some("media/cache/3d/54/3d54940e57e662c4dd1f3ff00c78cc64.jpg"), name: Some("The Coming Woman: A ..."), price: Some("17,93 £") }, Produit { url : Some (« catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html »), image : Some("media/cache/66/88/66883b91f6804b2323c8369331cb7dd1.jpg"), name: Some("The Boys in the ..."), price: Some("22,60 £") }, Produit { url : Some("catalogue/the-black-maria_991/index.html"), image : Some("media/cache/58/46/5846057e28022268153beff6d352b06c.jpg"), nom : Some("The Black Maria"), prix : Some("52,15 £") }, Produit { url: Some("catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html"), image: Some("media/cache/be/f4/bef44da28c98f905a3ebec0b87be8530.jpg"), name: Some("Starving Hearts (Triangular Trade ..."), price: Some("13,99 £") }, Product { url : Some("catalogue/shakespeares-sonnets_989/index.html"), image : Some("media/cache/10/48/1048f63d3b5061cd2f424d20b3f9b666.jpg"), nom : Some("Shakespeare's Sonnets"), prix : Some("20,66 £") }, Produit { url: Some("catalogue/set-me-free_988/index.html"), image: Some("media/cache/5b/88/5b88c52633f53cacf162c15f4f823153.jpg"), name: Some("Set Me Free"), price: Some("17,46 £") }, Product { url : Some("catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html"), image : Some("media/cache/94/b1/94b1b8b244bce9677c2f29ccc890d4d2.jpg"), name: Some("Scott Pilgrim's Precious Little ..."), price: Some("£52.29") }, Product { url: Some("catalogue/rip-it-up-and-start-again_986/index.html"), image: Some("media/cache/81/c4/81c4a973364e17d01f217e1188253d5e.jpg"), name: Some("Rip it Up and ..."), price: Some("35,02 £") }, Produit { url: Some("catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html"), image: Some("media/cache/54/60/54607fe8945897cdcced0044103b10b6.jpg"), name: Some("Our Band Could Be ..."), price: Some("57,25 £") }, Product { url: Some("catalogue/olio_984/index.html"), image: Some("media/cache/55/33/553310a7162dfbc2c6d19a84da0df9e1.jpg"), name: Some("Olio"), price: Some("23,88 £") }, Product { url : Some (« catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html »), image : Some("media/cache/09/a3/09a3aef48557576e1a85ba7efea8ecb7.jpg"), name: Some("Mesaerion : The Best Science ..."), price: Some("37,59 £") }, Produit { url : Some("catalogue/libertarianism-for-beginners_982/index.html"), image : Some("media/cache/0b/bc/0bbcd0a6f4bcd81ccb1049a52736406e.jpg"), nom : Some("Libertarianism for Beginners"), prix : Some("51,33 £") }, Produit { url: Some("catalogue/its-only-the-himalayas_981/index.html"), image: Some("media/cache/27/a5/27a53d0bb95bdd88288eaf66c9230d7e.jpg"), name: Some("It's Only the Himalayas"), price: Some("45,17 £") }]
Cela signifie que la logique de scraping fonctionne correctement. Vous êtes désormais prêt à ajouter votre Proxy Nginx à ce Scraper.
Utilisation de votre Proxy
Vous remarquerez que la requête de scraping est envoyée via un client reqwest complet dans la fonction main() (au lieu d’utiliser un appel get unique). Cela signifie que vous pouvez facilement configurer un Proxy lors de la création du client.
Pour configurer le client, mettez à jour la ligne de code suivante :
async fn main() -> Result<(), Box<dyn Error>>{
let url = "https://books.toscrape.com/";
# Remplacez cette ligne
let client = reqwest::Client::new();
# Par celle-ci
let client = reqwest::Client::builder()
.Proxy(reqwest::Proxy::https("http://localhost:8080")?)
.build()?;
//...
Ok(())
}
Lors de la configuration du Proxy à l’aide de
reqwest, il est important de comprendre que certains fournisseurs de Proxy (y compris Bright Data) fonctionnent avec les configurationshttpethttps, mais peuvent nécessiter une configuration supplémentaire. Si vous rencontrez des problèmes lors de l’utilisationde https, essayez de passer àhttppour exécuter l’application.
Maintenant, essayez à nouveau d’exécuter le binaire à l’aide de la commande cargo run. Vous devriez obtenir une réponse similaire à celle obtenue précédemment. Cependant, assurez-vous de consulter les journaux de votre serveur Nginx pour voir si une requête a été Proxyée via celui-ci.
Localisez les journaux de votre serveur Nginx en suivant les instructions correspondant à votre système d’exploitation. Pour une installation basée sur Homebrew sur Mac, les fichiers journaux d’accès et d’erreurs se trouvent dans le dossier /opt/homebrew/var/log/nginx. Ouvrez le fichier access.log et vous devriez voir une ligne comme celle-ci au bas du fichier :
127.0.0.1 - - [07/Jan/2024:05:19:54 +0530] « GET https://books.toscrape.com/ HTTP/1.1 » 200 18 « - » « - »
Cela indique que la requête a été transmise via le serveur Nginx en tant que Proxy. Vous pouvez désormais configurer le serveur sur un hôte distant afin de l’utiliser pour contourner les restrictions géographiques ou les blocages d’IP.
Proxy rotatif
Lorsque vous travaillez sur des projets de scraping web, vous pouvez être amené à alterner entre plusieurs proxys. Cela vous permet de répartir votre charge de travail entre plusieurs adresses IP et d’éviter d’être détecté en raison d’un trafic élevé provenant d’une seule source ou d’un seul emplacement.
Pour mettre en œuvre des Proxys rotatifs, vous devez ajouter les fonctions suivantes à votre fichier main.rs:
#[derive(Debug)]
struct Proxy {
ip: String,
port: String,
}
fn get_proxies() -> Vec<PROXY> {
let mut proxies = Vec::new();
proxies.push(Proxy {
ip: "http://localhost".to_string(),
port: "8082".to_string(),
});
// Ajoutez ici d'autres instructions proxies.push pour créer un ensemble plus important de proxys.
proxies
}
Cela vous aide à définir facilement l’ensemble de Proxys. Vous devez ensuite mettre à jour la fonction principale comme suit pour utiliser un Proxy aléatoire :
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "https://books.toscrape.com/";
// Ajoutez ces deux lignes
let proxies = get_proxies();
let random_proxy = proxies.choose(&mut rand::thread_rng()).unwrap();
let client = reqwest::Client::builder()
// Mettre à jour la ligne suivante pour qu'elle corresponde à ceci
.proxy(reqwest::Proxy::http(format!("{0}:{1}", random_proxy.ip, random_proxy.port))?)
.build()?;
// Le reste reste inchangé
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
Vous devez maintenant installer la crate rand pour pouvoir sélectionner aléatoirement un Proxy dans le tableau de Proxys. Pour ce faire, exécutez la commande suivante :
cargo add rand
Ajoutez ensuite la ligne suivante en haut de votre fichier main.rs pour importer le crate rand:
use rand::seq::SliceRandom;
Essayez maintenant d’exécuter à nouveau le binaire pour voir s’il fonctionne à l’aide de la commande cargo run. Il devrait afficher le même résultat qu’auparavant, indiquant que la liste aléatoire de Proxys est correctement configurée.
Serveur Proxy Bright Data
Comme vous l’avez vu, la configuration manuelle d’un Proxy peut demander beaucoup de travail. De plus, vous devez héberger le serveur Proxy sur un serveur distant pour pouvoir profiter de tous les avantages d’une nouvelle adresse IP et d’un nouvel emplacement. Si vous voulez éviter tous ces tracas, envisagez d’utiliser l’un desserveurs Proxy Bright Data.
Bien qu’il existe d’innombrables fournisseurs de proxy, Bright Data est réputé pour son ampleur et sa flexibilité. Avec Bright Data, vous bénéficiez d’un vaste réseau de 400M+ monthly Proxys résidentiels, mobiles, de centres de données et de Proxys ISP répartis dans 195 pays. Grâce à son grand nombre de Proxys résidentiels, vous pouvez cibler des pays, des villes ou même des opérateurs mobiles spécifiques pour un scraping ultra-précis.
De plus, les Proxys résidentiels Bright Data s’intègrent parfaitement au trafic réel des utilisateurs, tandis que les options de centre de données et mobiles offrent une vitesse fulgurante et des connexions fiables. La rotation automatique de Bright Data permet un scraping agile, minimisant le risque de détection et de bannissement.
Pour l’essayer par vous-même, rendez-vous sur https://brightdata.com/ et cliquez sur « Essai gratuit » dans le coin supérieur droit. Une fois inscrit, vous serez redirigé vers la page « Control Panel » (Panneau de contrôle) :
Sur cette page, cliquez sur « View proxy products » (Afficher les produits proxy) pour accéder à la page « Proxies & Infrastructure de scraping » (Proxys et Infrastructure de scraping) :
Cette page répertorie tous les proxys que vous avez précédemment provisionnés. Pour ajouter un proxy, cliquez sur le bouton bleu « Ajouter » en haut à droite et choisissez « Proxys résidentiels » :
Un formulaire s’affiche alors, dans lequel vous pouvez configurer votre nouveau Proxy résidentiel. Laissez les options par défaut, faites défiler vers le bas de la page et cliquez sur Ajouter.
Une fois le Proxy résidentiel créé, vous serez redirigé vers une page qui affiche les détails du Proxy nouvellement créé. Cliquez sur l’onglet Paramètres d’accès pour afficher l’hôte, le nom d’utilisateur et le mot de passe du Proxy :
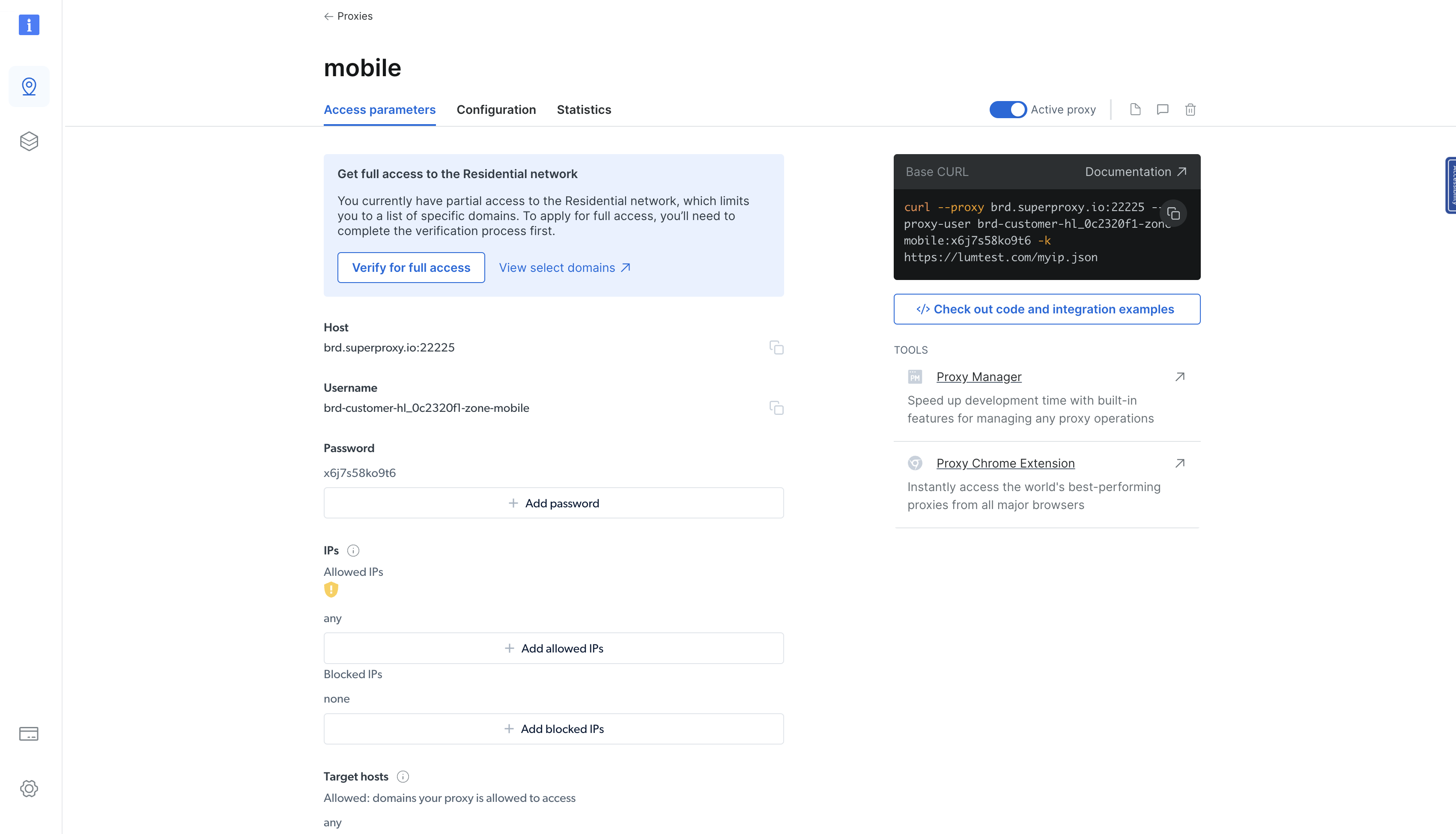
Vous pouvez utiliser ces paramètres pour intégrer le Proxy dans votre binaire Rust. Pour ce faire, mettez à jour la fonction main() dans le fichier src/main.rs comme suit :
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "https://books.toscrape.com/";
// Mettez à jour le bloc suivant avec les informations de la page de détails du Proxy Bright Data.
let client = reqwest::Client::builder()
.proxy(reqwest::Proxy::http("<NOM d'hôte et port du Proxy BD>")?
.basic_auth("<VOTRE nom d'utilisateur BD>", "<VOTRE mot de passe BD>"))
.build()?;
// Le reste reste inchangé.
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
Essayez ensuite d’exécuter à nouveau le fichier binaire. Il devrait renvoyer la réponse correctement, comme auparavant. La seule différence notable ici est que la requête est Proxyée via Bright Data, ce qui masque votre identité et votre emplacement réel.
Vous pouvez le vérifier en envoyant une requête à une API qui affiche l’adresse IP du client à l’aide de l’extrait de code suivant :
use reqwest;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "http://lumtest.com/myip.json";
// Mettez à jour le bloc suivant avec les informations de la page de détails du Proxy Bright Data.
let client = reqwest::Client::builder()
.proxy(reqwest::Proxy::http("<NOM d'hôte et port du Proxy BD>")?
.basic_auth("<VOTRE nom d'utilisateur BD>", "<VOTRE mot de passe BD>"))
.build()?;
// Le reste reste inchangé.
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
println!("{:?}", html_content);
Ok(())
}Lorsque vous exécutez le code à l’aide de la commande cargo run, vous devriez obtenir un résultat similaire à celui-ci :
"{"ip":"209.169.64.172","country":"US","asn":{"asnum":6300,"org_name":"CCI-TEXAS"},"geo":{"city":"Conroe","region":"TX","region_name":"Texas","postal_code":"77304","latitude":30.3228,"longitude":-95.5298,"tz":"America/Chicago","lum_city":"conroe","lum_region":"tx"}}"
Cela reflétera l’adresse IP et les détails de localisation du Proxy que vous utilisez pour interroger la page.
Conclusion
Dans cet article, vous avez appris à utiliser des Proxies avec Rust. N’oubliez pas que les Proxies sont comme des masques numériques qui vous permettent de contourner les restrictions en ligne et de jeter un œil derrière les restrictions des sites web. Ils vous permettent également de préserver votre anonymat lorsque vous naviguez sur le web.
Cependant, la configuration d’un Proxy par vous-même est un processus complexe. Il est généralement recommandé de faire appel à un fournisseur de Proxy établi tel queBright Data, qui propose un Pool de 400M+ monthly proxies faciles à utiliser.




