

Le web scraping, une technique de collecte de données, est souvent entravé par divers obstacles, notamment les interdictions d’IP, le géoblocage et les préoccupations en matière de vie privée. Heureusement, l’utilisation de serveurs proxy peut vous aider à surmonter ces difficultés. Un serveur proxy sert d’intermédiaires entre votre ordinateur et internet. Il transfert vos requêtes avec sa propre adresse IP. Cette technologie permet non seulement d’échapper aux restrictions et interdictions liées à l’adresse IP, mais aussi de faciliter l’accès à des contenus géographiquement restreints. En outre, les serveurs proxy permettent de préserver votre anonymat lorsque vous parcourez le web, protégeant ainsi votre vie privée.
L’utilisation de serveurs proxy peut également améliorer les performances et la fiabilité de vos activités de web scraping. En répartissant vos requêtes sur plusieurs serveurs, ceux-ci se répartissent la charge, ce qui optimise le processus.
Dans ce tutoriel, vous allez apprendre à utiliser un serveur proxy dans Node.js pour vos projets de web scraping.
Prérequis
Dans ce tutoriel, il est recommandé de connaître JavaScript et Node.js. Si vous n’avez pas encore installé Node.js sur votre ordinateur, vous devez l’installer maintenant.
Vous avez également besoin d’un éditeur de texte approprié. Plusieurs options sont disponibles, comme Sublime Text. Ce tutoriel utilise Visual Studio Code (VS Code). Il est convivial et doté de nombreuses fonctionnalités qui facilitent le codage.
Pour commencer, créez un nouveau répertoire nommé « web-scraping-proxy », puis démarrez un projet Node.js. Ouvrez votre terminal ou votre shell et naviguez vers votre nouveau répertoire en utilisant les commandes suivantes :
cd web-scraping-proxy
npm init -y
Vous devez ensuite installer plusieurs paquets Node.js pour gérer les requêtes HTTP et analyser le HTML.
Vérifiez que vous vous trouvez bien dans le répertoire de votre projet, puis exécutez les commandes suivantes :
npm install axios playwright puppeteer http-proxy-agent
npx playwright install
On utilise Axios pour créer des requêtes HTTP afin de récupérer du contenu web. Playwright et Puppeteer automatisent les interactions avec le navigateur, ce qui est essentiel pour récupérer des sites web dynamiques. Playwright prend en charge différents navigateurs, tandis que Puppeteer se concentre sur Chrome et Chromium. On utilisera la bibliothèque « http-proxy-agent » pour créer un agent proxy pour les requêtes HTTP.
Le programme « npx playwright install » est requis pour installer les pilotes nécessaires à la bibliothèque playwright.
Une fois ces étapes terminées, vous allez pouvoir plonger dans le monde du web scraping avec Node.js.
Configurer un proxy local pour le web scraping
La première étape du web scraping est la mise en place d’un serveur proxy. Pour ce tutoriel, nous allons utiliser l’outil open source mitmproxy.
Pour commencer, rendez-vous sur la page de téléchargement de mitmproxy et téléchargez la version 10.1.6 adaptée à votre système d’exploitation. Si vous avez besoin de conseils pendant l’installation, n’hésitez pas à consulter le guide d’installation de mitmproxy.
Une fois mitmproxy installé, lancez-le en saisissant la commande suivante dans votre terminal :
mitmproxy
Cette commande ouvre une fenêtre dans votre terminal qui sert d’interface pour mitmproxy :
Pour vous assurer que votre proxy est correctement configuré, faites le test suivant : ouvrez une nouvelle fenêtre de terminal et exécutez cette commande :
curl --proxy http://localhost:8080 "http://wttr.in/Paris?0"
Cette commande récupère le bulletin météorologique pour Paris. Votre résultat devrait ressembler à ceci :
Weather report: Paris
Overcast
.--. -2(-6) °C
.-( ). ↙ 11 km/h
(___.__)__) 10 km
0.0 mm
De retour dans la fenêtre mitmproxy, vous remarquerez que la requête a été capturée, ce qui indique que votre proxy local fonctionne correctement :

Implémenter un proxy dans Node.js pour le web scraping
Nous allons maintenant passer aux aspects pratiques du web scraping avec Node.js. Dans cette section, vous devez écrire un script qui scrape un site web en envoyant des requêtes via le serveur proxy local.
Récupérer un site web à l’aide de la méthode Fetch
Créez un fichier nommé fetchScraping.js dans le répertoire racine de votre projet. Ce fichier contiendra le code permettant de récupérer le contenu d’un site web, qui dans ce cas est https://toscrape.com/.
Dans votre fichier fetchScraping.js, saisissez le code JavaScript suivant. Ce script utilise la méthode fetch pour envoyer des requêtes via votre serveur proxy :
const fetch = require("node-fetch");
const HttpProxyAgent = require("http-proxy-agent");
async function fetchData(url) {
try {
const proxyAgent = new HttpProxyAgent.HttpProxyAgent(
"http://localhost:8080"
);
const response = await fetch(url, { agent: proxyAgent });
const data = await response.text();
console.log(data); // Outputs the fetched data
} catch (error) {
console.error("Error fetching data:", error);
}
}
fetchData("http://toscrape.com/");
Cet extrait de code définit une fonction asynchrone fetchData qui prend une URL et envoie une requête à cette URL en utilisant fetch tout en la faisant passer par le proxy local. Il imprime ensuite les données de la réponse.
Pour exécuter votre script de web scraping, ouvrez votre terminal ou votre shell et naviguez jusqu’au répertoire racine de votre projet, là où se trouve votre fichier fetchScraping.js. Exécutez le script à l’aide de cette commande :
node fetchScraping.js
Vous devriez voir ceci sur votre terminal :
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
Il s’agit du contenu HTML de la page web http://toscrape.com. L’affichage réussi de ces données indique que votre script de web scraping, acheminé via le proxy local, fonctionne correctement.
Retournez maintenant sur votre fenêtre mitmproxy. Vous devriez voir que la requête a été enregistrée, ce qui signifie que votre requête est passée par votre proxy local :
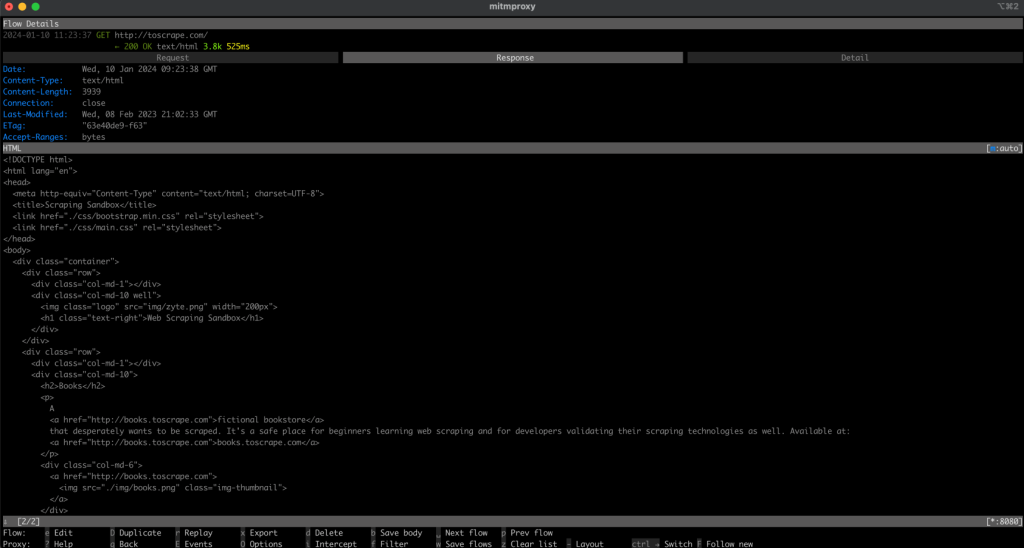
Scraper un site web à l’aide de Playwright
Comparé à Fetch, Playwright est un outil avancé qui crée des interactions plus dynamiques avec les pages web. Pour l’utiliser, vous devez créer un nouveau fichier appelé playwrightScraping.js dans votre projet. Dans ce fichier, saisissez le code JavaScript suivant :
const { chromium } = require("playwright");
(async () => {
const browser = await chromium.launch({
proxy: {
server: "http://localhost:8080",
},
});
const page = await browser.newPage();
await page.goto("http://toscrape.com/");
// Extract and log the entire HTML content
const content = await page.content();
console.log(content);
await browser.close();
})();
Ce code utilise Playwright pour lancer une instance du navigateur Chromium configurée pour utiliser votre serveur proxy local. Il ouvre ensuite une nouvelle page dans le navigateur, se rend sur le site http://toscrape.com et attend le chargement de la page. Après avoir récupéré les données nécessaires, le navigateur est fermé.
Pour exécuter ce script, vérifiez que vous êtes bien dans le répertoire contenant playwrightScraping.js. Ouvrez votre terminal ou votre shell et exécutez le script à l’aide de la commande suivante :
node playwrightScraping.js
Lorsque vous exécutez le script, Playwright lance une instance du navigateur Chromium, navigue vers l’URL spécifiée et exécute toutes les commandes de scraping supplémentaires que vous avez ajoutées. Ce processus utilise le serveur proxy local. Ainsi, votre adresse IP n’est pas visible et vous pouvez contourner d’éventuelles restrictions.
La sortie attendue devrait être similaire à la précédente :
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
Comme précédemment, vous devriez voir votre requête enregistrée dans la fenêtre mitmproxy.
Scraper un site web à l’aide de Puppeteer
Vous pouvez scraper un site web à l’aide de Puppeteer. Puppeteer est un outil puissant qui offre un haut niveau de contrôle sur un navigateur Chrome ou Chromium sans tête. Cette méthode est particulièrement utile pour récupérer des sites web dynamiques qui nécessitent un rendu JavaScript.
Pour commencer, créez un nouveau fichier dans votre projet nommé puppeteerScraping.js. Ce fichier contiendra le code Puppeteer permettant de récupérer un site web en utilisant le serveur proxy pour les requêtes.
Ouvrez le fichier puppeteerScraping.js nouvellement créé et insérez le code JavaScript suivant :
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
args: ['--proxy-server=http://localhost:8080']
});
const page = await browser.newPage();
await page.goto('http://toscrape.com/');
const content = await page.content();
console.log(content); // Outputs the page HTML
await browser.close();
})();
Dans ce code, vous initialisez Puppeteer pour qu’il lance un navigateur sans tête, en précisant qu’il doit utiliser votre serveur proxy local. Le navigateur ouvre une nouvelle page, navigue jusqu’à http://toscrape.com, puis récupère le contenu HTML de la page. Une fois le contenu enregistré dans la console, la session du navigateur est fermée.
Pour exécuter votre script, accédez au dossier contenant puppeteerScraping.js dans votre terminal ou votre shell. Exécutez le script à l’aide de la commande suivante :
node puppeteerScraping.js
Après avoir exécuté le script, Puppeteer ouvre l’URL http://toscrape.com/ à l’aide du serveur proxy. Le contenu HTML de la page doit s’afficher dans votre terminal. Cela indique que votre script Puppeteer récupère correctement la page web à travers le proxy local.
La sortie attendue devrait être similaire aux précédentes, et vous devriez voir votre requête enregistrée dans la fenêtre mitmproxy :
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
Une meilleure alternative : le serveur proxy Bright Data
Pour améliorer vos capacités de scraping web, envisagez d’utiliser Bright Data. Le serveur proxy Bright Data offre une solution avancée pour la gestion de vos requêtes web.
Bright Data propose différents serveurs proxy, tels que des proxies résidentiels, de FAI, de centre de données et mobiles… Ces serveurs vous permettent d’accéder à n’importe quel site web à partir de différents emplacements géographiques. Cela vous permet d’émuler différents agents utilisateurs et d’assurer votre anonymat.
Bright Data propose également la rotation de proxies qui améliore l’efficacité et l’anonymat de vos activités de web scraping en passant automatiquement d’un proxy à un autre pour éviter que votre adresse IP ne soit bannie.
En outre, vous pouvez utiliser le navigateur de scraping de Bright Data, qui est un navigateur automatisé doté de capacités de déblocage intégrées pour des éléments tels que les CAPTCHA, les cookies et les empreintes digitales du navigateur. Vous pouvez également tirer parti du Web Unlocker de Bright Data, qui est doté d’algorithmes d’apprentissage automatique pour contourner tout blocage des sites web ciblés et vous permettre de collecter des données sans être bloqué.
Mise en place d’un proxy Bright Data dans un projet Node.js
Pour intégrer un proxy Bright Data dans votre projet Node.js, vous devez vous inscrire pour un essai gratuit. Une fois votre compte actif, identifiez-vous, naviguez vers Infrastructure de scraping et proxies, et ajoutez un nouveau proxy en sélectionnant Proxies résidentiels :
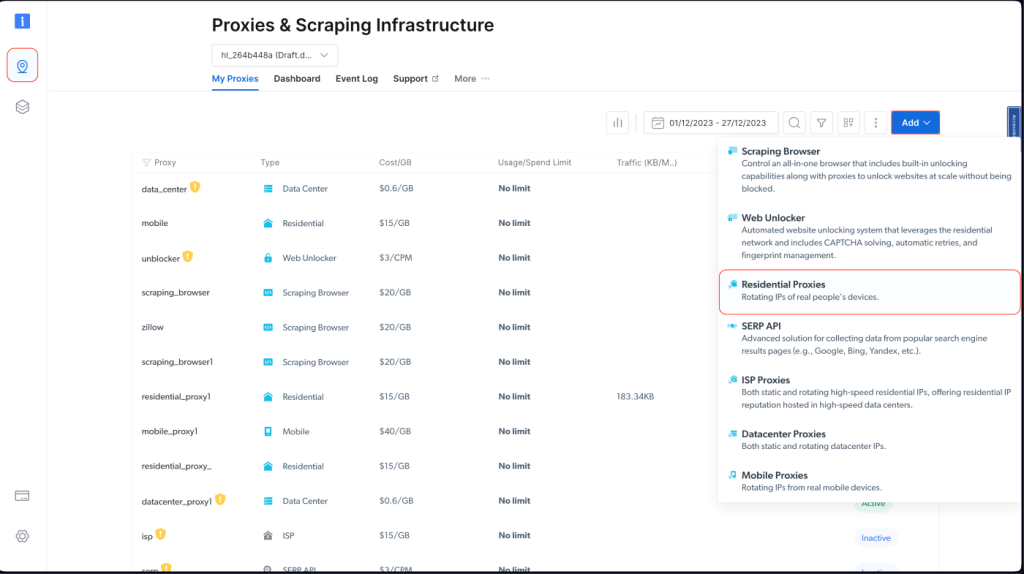
Conservez les paramètres par défaut et finalisez la création de votre proxy résidentiel :
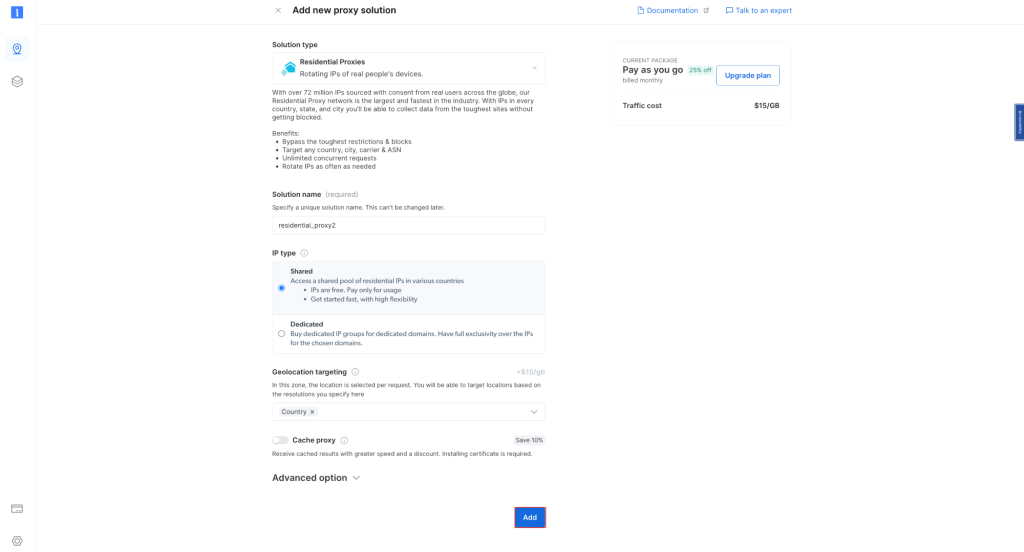
Une fois créé, notez les informations d’identification du proxy, notamment l’hôte, le port, l’identifiant et le mot de passe. Vous en aurez besoin à l’étape suivante :
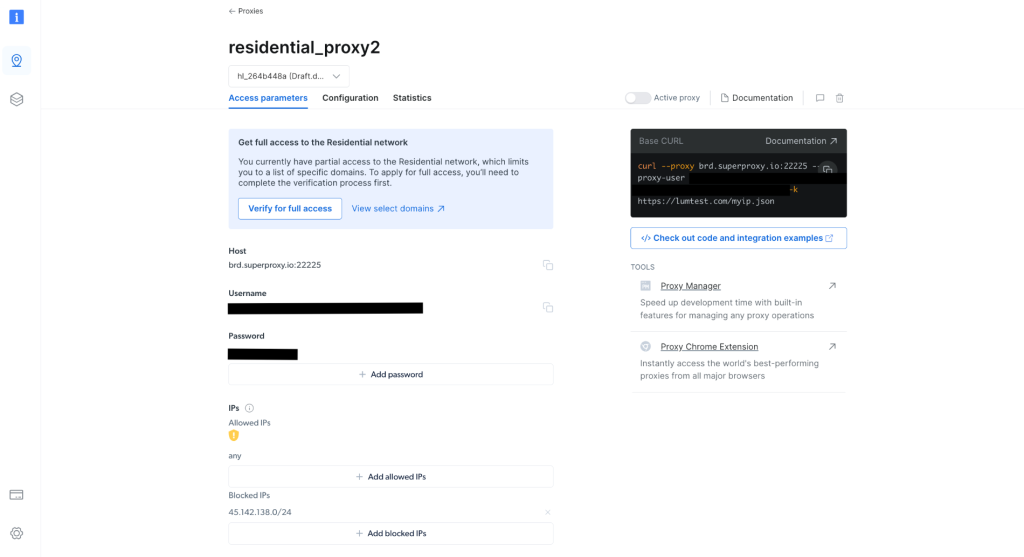
Dans votre projet, créez un fichier nommé scrapingWithBrightData.js et ajoutez l’extrait suivant, en veillant à remplacer les données d’identification par les informations propres à votre proxy Bright Data :
const axios = require('axios');
async function fetchDataWithBrightData(url) {
const proxyOptions = {
proxy: {
host: 'YOUR_BRIGHTDATA_PROXY_HOST',
port: YOUR_BRIGHTDATA_PROXY_PORT,
auth: {
username: 'YOUR_BRIGHTDATA_USERNAME',
password: 'YOUR_BRIGHTDATA_PASSWORD'
}
}
};
try {
const response = await axios.get(url, proxyOptions);
console.log(response.data); // Outputs the fetched data
} catch (error) {
console.error('Error:', error);
}
}
fetchDataWithBrightData('http://lumtest.com/myip.json');
Ce script configure axios pour qu’il achemine les requêtes HTTP via votre proxy Bright Data. Il récupère les données d’une URL spécifiée en utilisant cette configuration de proxy. Dans cet exemple, vous ciblerez http://lumtest.com/myip.json afin de voir les différentes sources de serveurs proxy en fonction de votre configuration Bright Data.
Pour exécuter votre script, accédez au dossier contenant scrapingWithBrightData.js dans votre terminal ou votre shell. Exécutez ensuite le script à l’aide de la commande suivante :
node scrapingWithBrightData.js
Une fois la commande exécutée, vous devriez obtenir l’emplacement de votre adresse IP dans votre console, qui est principalement liée au serveur proxy de Bright Data.
La sortie attendue est similaire à ce qui suit :
{
ip: '108.53.191.230',
country: 'US',
asn: { asnum: 701, org_name: 'UUNET' },
geo: {
city: 'Jersey City',
region: 'NJ',
region_name: 'New Jersey',
postal_code: '07302',
latitude: 40.7182,
longitude: -74.0476,
tz: 'America/New_York',
lum_city: 'jerseycity',
lum_region: 'nj'
}
}
À présent, si vous exécutez à nouveau le script avec node scrapingWithBrightData.js, vous remarquerez qu’une adresse IP différente est utilisée par le serveur proxy de Bright Data. Cela confirme que Bright Data utilise des emplacements et des adresses IP différentes à chaque fois que vous exécutez votre script de scraping, ce qui vous permet de contourner tout blocage ou interdiction d’adresses IP des sites web ciblés.
Le résultat devrait ressembler à ceci :
{
ip: '93.85.111.202',
country: 'BY',
asn: {
asnum: 6697,
org_name: 'Republican Unitary Telecommunication Enterprise Beltelecom'
},
geo: {
city: 'Orsha',
region: 'VI',
region_name: 'Vitebsk',
postal_code: '211030',
latitude: 54.5081,
longitude: 30.4172,
tz: 'Europe/Minsk',
lum_city: 'orsha',
lum_region: 'vi'
}
}
L’interface conviviale et la simplicité de configuration de Bright Data permettent à tout le monde, même aux débutants, d’utiliser efficacement ses puissantes fonctionnalités de gestion de proxy.
Conclusion
Vous avez appris à utiliser les proxies avec Node.js. Sans solution de gestion de proxy appropriée telle que celle proposée par Bright Data, vous risquez de rencontrer des difficultés telles que des interdictions d’adresse IP et un accès restreint aux sites web que vous ciblez, ce qui peut entraver vos activités de scraping. Vous avez également appris à quel point il est facile d’utiliser les proxies Bright Data pour améliorer vos efforts de web scraping. Ces serveurs contribuent non seulement à la robustesse et à l’efficacité de votre processus de collecte de données, mais ils offrent également la polyvalence requise pour divers scénarios de scraping.
Lorsque vous mettez ces compétences en pratique, n’oubliez pas qu’il est important de respecter les conditions d’utilisation des sites web et les lois sur la protection de la confidentialité. Il est essentiel de scraper de manière responsable, en respectant les règles établies par les sites web. Avec les connaissances que vous avez acquises, en particulier les capacités offertes par les proxies de Bright Data, vous êtes bien préparé pour réussir vos activités de web scraping de manière éthique. Bon scraping !
Tout le code de ce tutoriel est disponible dans ce dépôt GitHub.


