

Si vous vous intéressez au scraping web, il est essentiel de comprendre le langage HTML, car tous les sites web sont construits à partir de celui-ci. Le scraping web peut être utilisé dans toutes sortes de scénarios et peut aider à collecter des données à partir de sites web sans API, à surveiller les prix des produits, à créer des listes de prospects, à mener des recherches universitaires, etc.
Dans cet article, vous apprendrez les bases du HTML et comment extraire, analyser et traiter des données à l’aide de Python.
Vous souhaitez obtenir un guide détaillé sur le Scraping web avec Python ? Cliquez ici.
Comment extraire des données de sites web et extraire du HTML
Avant de commencer ce tutoriel, prenons un moment pour passer en revue les composants essentiels du HTML.
Introduction au HTML
Le HTML est un ensemble de balises qui indiquent à un navigateur la structure et les éléments d’un site web. Par exemple,<h1> Texte </h1>indique au navigateur que le texte qui suit la balise est un titre, et<a href=""> lien </a>identifie un lien hypertexte.
Un attribut HTML fournit des informations supplémentaires sur une balise. Par exemple, l’attributhrefde la balise<a> </a>vous donne des informations sur l’URL de la page vers laquelle l’attribut pointe.
Les classes et les identifiantssont des attributs essentiels pour identifier avec précision les éléments d’une page. Les classes regroupent des éléments similaires afin de leur appliquer un style cohérent à l’aide de CSS ou de les manipuler de manière uniforme avec JavaScript. Les classes sont ciblées à l’aide de.class-name.
Sur le site Web W3Schools, les groupes de classes se présentent comme suit :
<div class="city">
<h2>Londres</h2>
<p>Londres est la capitale de l'Angleterre.</p>
</div>
<div class="city">
<h2>Paris</h2>
<p>Paris est la capitale de la France.</p>
</div>
<div class="city">
<h2>Tokyo</h2>
<p>Tokyo est la capitale du Japon.</p>
</div>
Vous pouvez voir comment chaque titre et chaque bloc de ville sont encapsulés dans une balise div qui possède la même classe city.
En revanche, les identifiants sont uniques à chaque élément (c’est-à-dire que deux éléments ne peuvent pas avoir le même identifiant). Par exemple, les H1 suivants ont des identifiants uniques et peuvent être stylisés/manipulés de manière unique :
<h1 id="header1">Bonjour tout le monde !</h1>
<h1 id="header2">Lorem Ipsum Dolor</h1>
La syntaxe pour cibler des éléments avec des identifiants est #id-name.
Maintenant que vous connaissez les bases du HTML, passons au Scraping web.
Configurez votre environnement de scraping
Ce tutoriel utilise Python, car il offre de nombreuses bibliothèques de scraping HTML et le langage est facile à apprendre. Pour vérifier si Python est installé sur votre ordinateur, exécutez la commande suivante dans PowerShell (Windows) ou votre terminal (macOS) :
python3
Si Python est installé, vous verrez s’afficher le numéro de votre version ; sinon, vous recevrez un message d’erreur. Procédez àl’installation de Pythonsi vous ne l’avez pas déjà fait.
Ensuite, créez un dossier appeléWebScraperet créez un fichier dans le dossierWebScrapernomméscraper.py. Ouvrez-le ensuite dans l’environnement de développement intégré (IDE) de votre choix.Visual Studio Codeest utilisé ici :
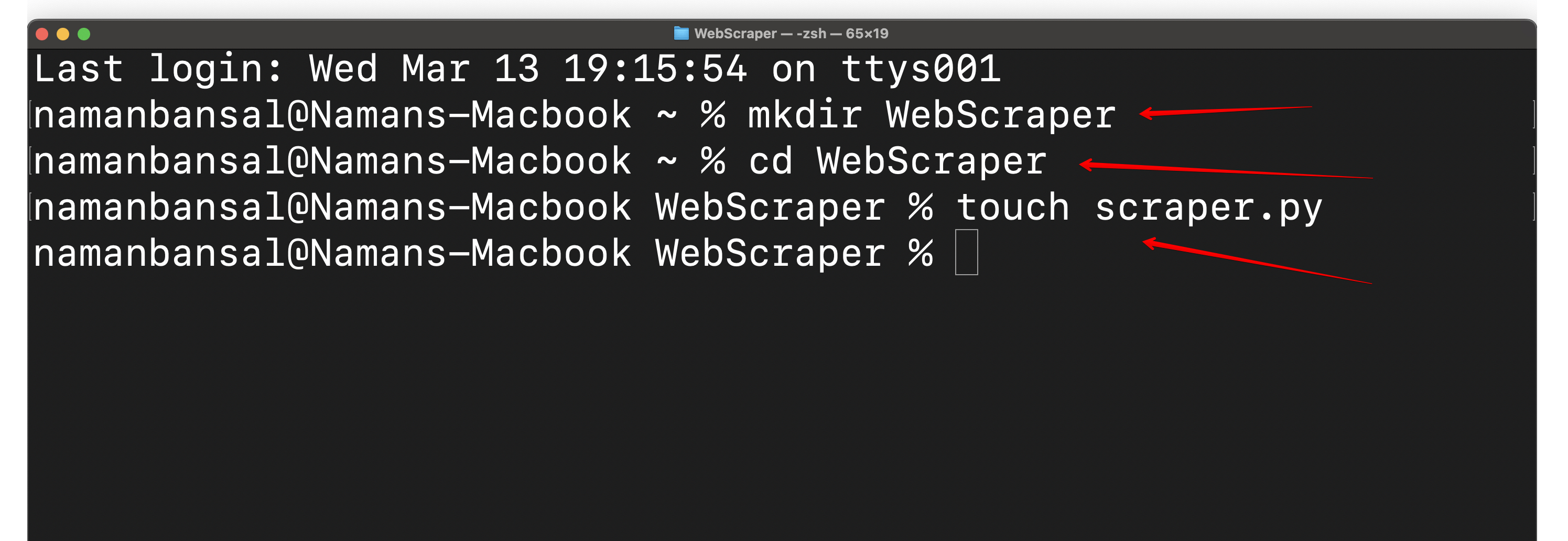
Un IDE est une application polyvalente qui permet aux programmeurs d’écrire du code, de le déboguer, de tester des programmes, de créer des automatisations, etc. Vous l’utiliserez ici pour coder votre Scraper HTML.
Ensuite, vous devez séparer votre installation Python globale de votre projet de scraping en créant un environnement virtuel. Cela permet d’éviter les conflits de dépendances et de garder l’ensemble de l’application organisé.
Pour ce faire, installez la bibliothèque virtualenv à l’aide de la commande suivante :
pip3 install virtualenv
Accédez au dossier de votre projet :
cd WebScraper
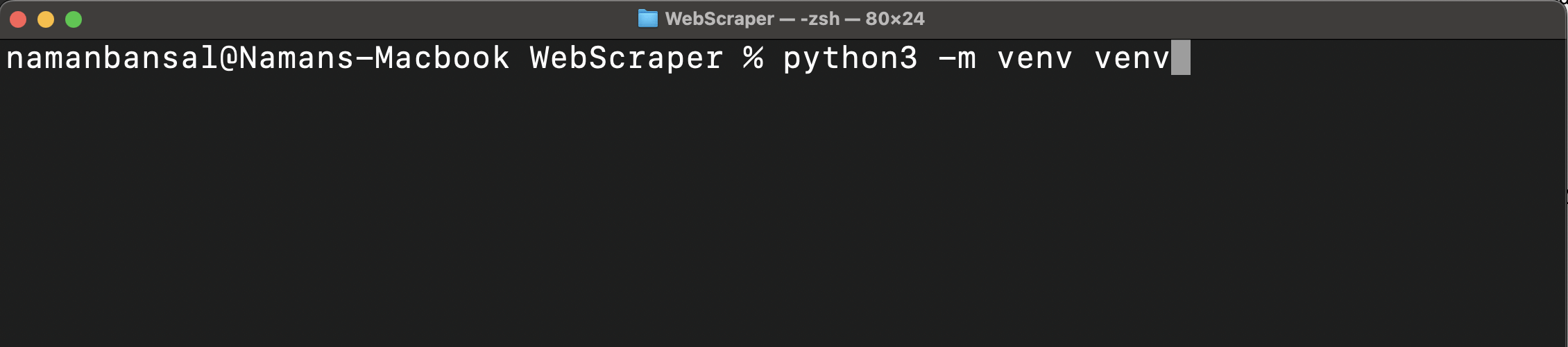
Créez ensuite un environnement virtuel :
python<version> -m venv <nom-de-l'environnement-virtuel>
Cette commande crée un dossier pour tous les paquets et scripts à l’intérieur du dossier de votre projet :
Vous devez maintenant activer l’environnement virtuel à l’aide de l’une des commandes suivantes (en fonction de votre plateforme) :
source <nom-de-l'environnement-virtuel>/bin/activate #Sous MacOS et Linux
<nom-de-l'environnement-virtuel>/Scripts/activate.bat #Sous CMD
<nom-de-l'environnement-virtuel>/Scripts/Activate.ps1 #Sous Powershell
Une fois l’activation réussie, vous verrez le nom de votre environnement virtuel s’afficher à gauche de l’écran :
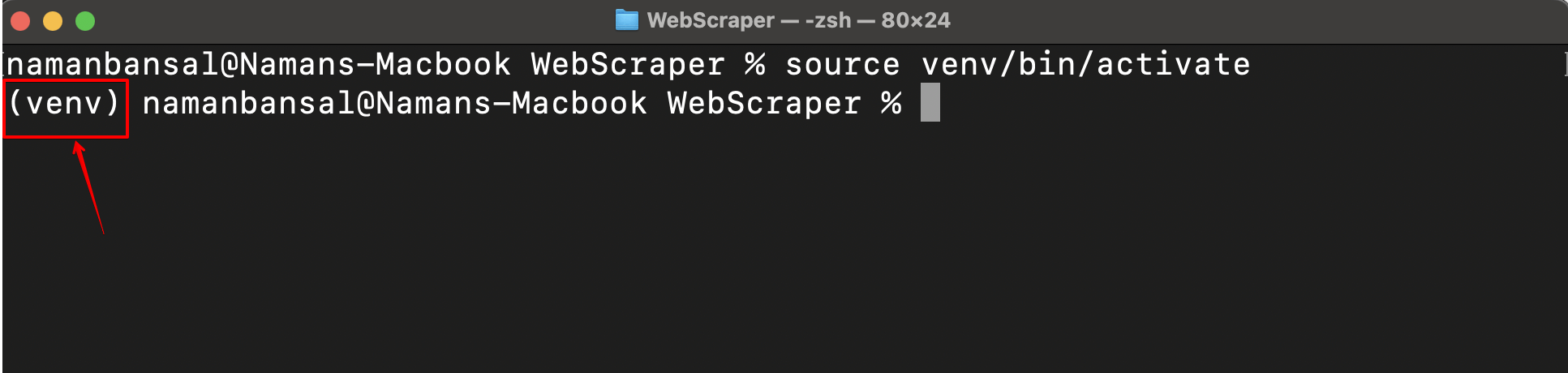
Maintenant que votre environnement virtuel est activé, vous devez installer une bibliothèque de Scraping web. Il existe de nombreuses options, notamment Playwright, Selenium, Beautiful Soup et Scrapy. Ici, vous utilisez Playwright car il est facile à utiliser, prend en charge plusieurs navigateurs, peut gérer du contenu dynamique et offre un mode headless (scraping sans interface utilisateur graphique (GUI)).
Exécutez pip install pytest-playwright pour installer Playwright, puis installez les navigateurs requis avec playwright install.
Une fois Playwright installé, vous êtes prêt à commencer le Scraping web.
Extraire le code HTML d’un site web
La première étape de tout projet de Scraping web consiste à identifier le site web que vous souhaitez scraper. Ici, vous utilisez ce site de test.
Ensuite, vous devez identifier les informations que vous souhaitez extraire de la page. Dans ce cas, il s’agit du contenu HTML complet de la page.
Une fois que vous avez identifié les informations que vous souhaitez extraire, vous pouvez commencer à coder le Scraper. En Python, la première étape consiste àimporter les bibliothèques requises pour Playwright. Playwright vous permet d’importer deux types d’API :sync et async. La bibliothèque async est utilisée uniquement lors de l’écriture de code asynchrone, vous importez donc la bibliothèque sync avec la commande suivante :
from playwright.sync_api import sync_playwright
Après avoir importé la bibliothèque sync, vous devez déclarer une fonction Python à l’aide de l’extrait de code suivant :
def main():
#Le reste du code se trouvera à l'intérieur de cette fonction
Comme vous pouvez le voir dans la note précédente, vous écrivez votre code de Scraping web à l’intérieur de cette fonction.
En général, pour obtenir des informations à partir d’un site web, vous ouvrez un navigateur web, créez un nouvel onglet et visitez ce site web. Pour extraire le contenu du site, vous devez traduire ces actions en code, ce pour quoi vous utiliserez Playwright. Leurdocumentationmontre que vous pouvez appeler lasync_apiimportée précédemment et ouvrir un navigateur avec cet extrait :
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
En ajoutant headless=False entre parenthèses, vous pouvez voir le contenu du site web.
Après avoir ouvert votre navigateur, ouvrez un nouvel onglet et rendez-vous à l’URL cible :
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static")
except:
print("Error")
Remarque : les lignes précédentes doivent être ajoutées sous les lignes précédentes, qui ont lancé le navigateur. Tout ce code se trouve dans la fonction principale et dans un seul fichier.
Cet extrait de code encapsule la fonctiongoto()dans unbloc try-exceptpour une meilleure gestion des erreurs.
Lorsque vous saisissez l’URL d’un site dans la barre de recherche, vous devez attendre qu’il se charge. Pour imiter cela dans le code, vous pouvez utiliser ce qui suit :
page.wait_for_timeout(7000) #valeur en millisecondes entre parenthèses
Remarque : les lignes précédentes doivent être ajoutées sous les lignes précédentes.
Enfin, il est temps d’extraire tout le contenu HTML de la page à l’aide de cette ligne de code :
print(page.content())
Le code complet pour extraire le HTML d’une page ressemble à ceci :
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static")
except:
print("Error")
page.wait_for_timeout(7000)
print(page.content())
main()
Dans Visual Studio Code, le code HTML extrait se présente comme suit :
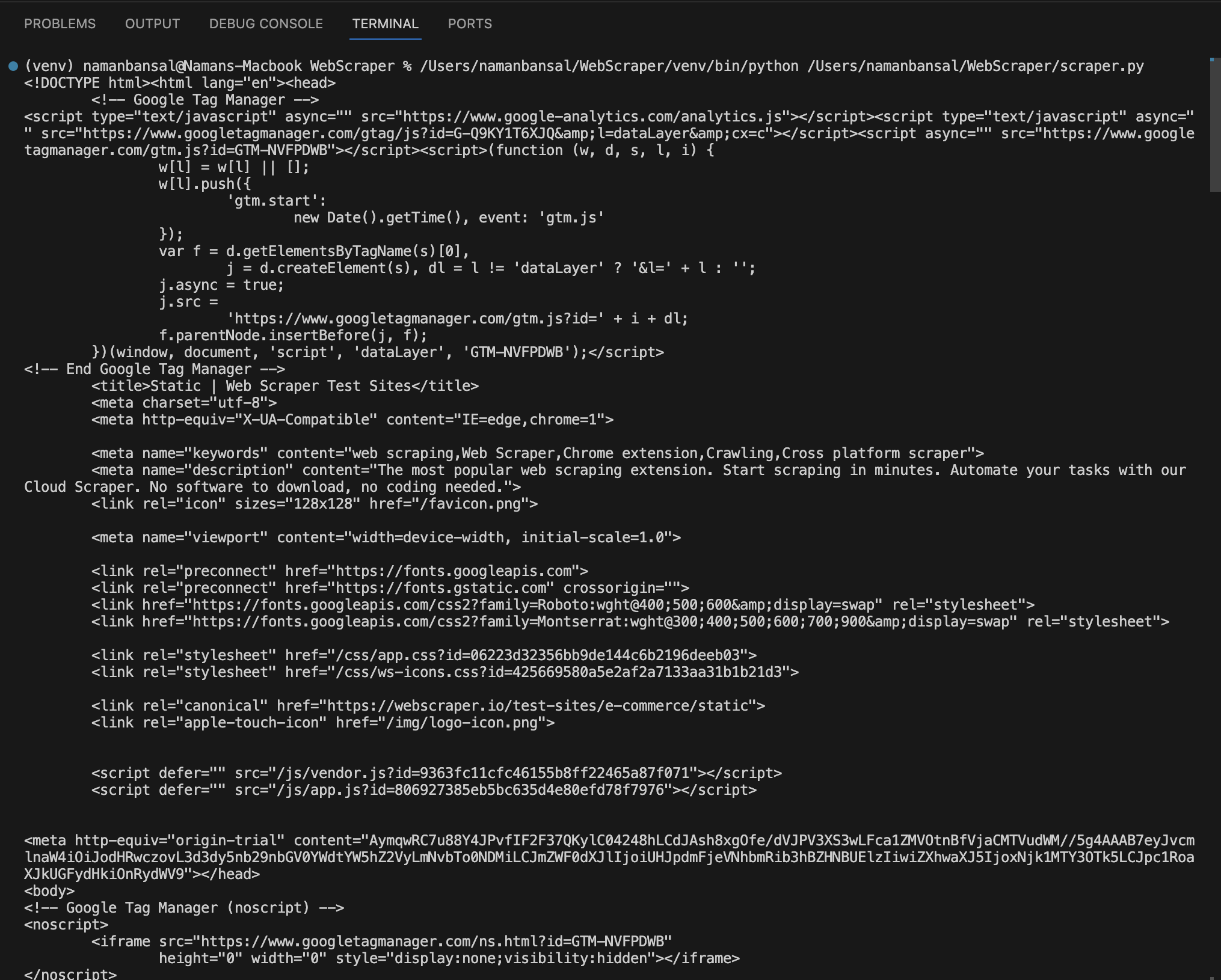
Extraire le code HTML à l’aide d’attributs spécifiques
Précédemment, vous avez extrait tous les éléments de la page Web Web Scraper ; cependant, le Scraping web n’est utile que si vous vous limitez à extraire uniquement les informations dont vous avez besoin. Dans cette section, vous extrayez uniquement les titres de tous les ordinateurs portables figurant sur la première page du site Web :
Pour extraire des éléments spécifiques, vous devez comprendre la structure du site Web cible. Pour ce faire, cliquez avec le bouton droit de la souris et sélectionnez l’optionInspectercomme suit :
Vous pouvez également utiliser les raccourcis clavier suivants :
- Pour macOS, utilisezCmd + Option + I
- Pour Windows, utilisezCtrl + Maj + C
Voici la structure de la page cible :
Vous pouvez afficher le code d’un élément spécifique d’une page à l’aide de l’outil de sélection situé en haut à gauche de la fenêtreInspecter:

Sélectionnez l’un des titres d’ordinateur portable dans votre fenêtreInspecter:
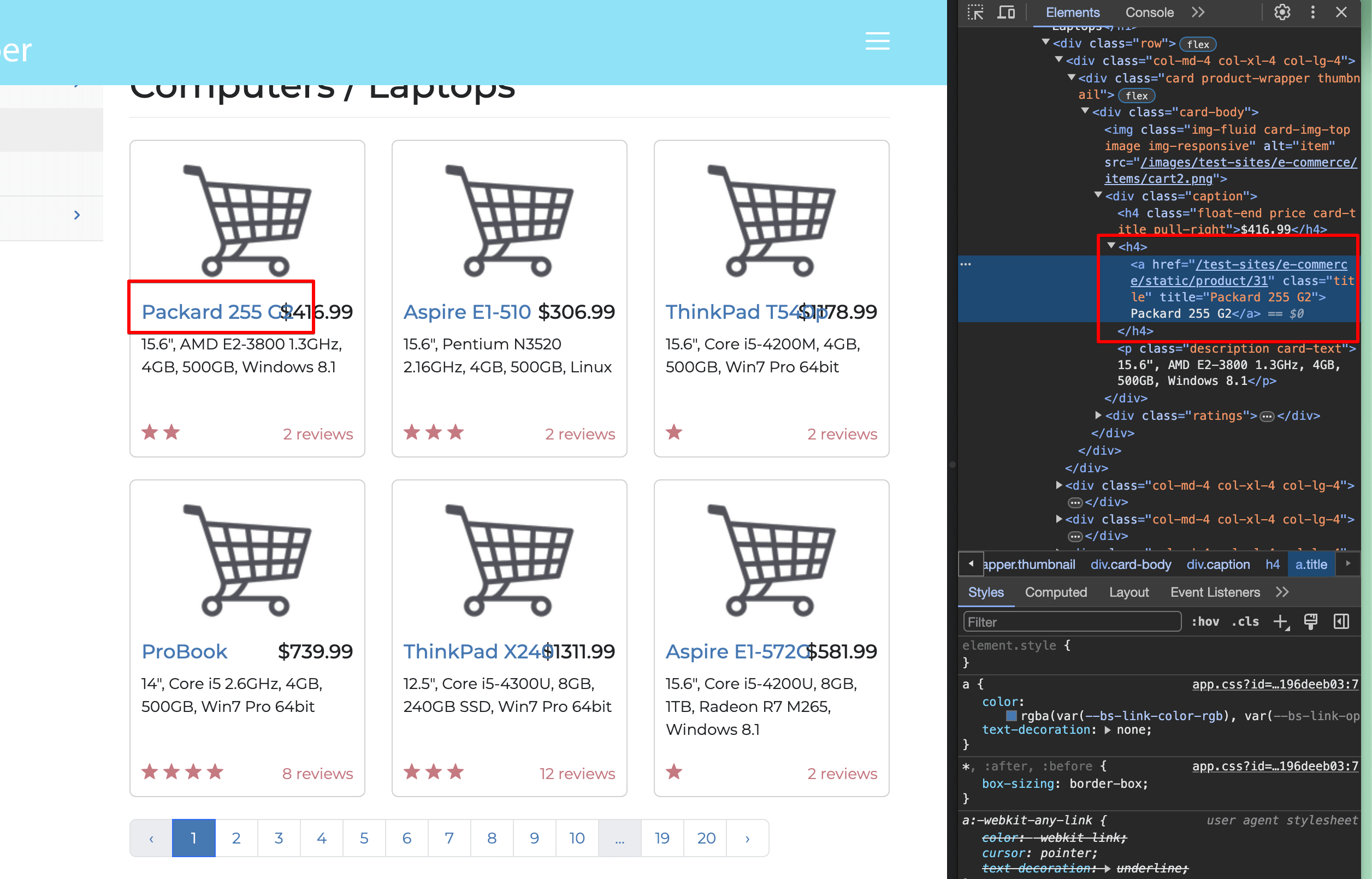
Vous pouvez voir que le titre se trouve à l’intérieur d’une balise <a> </a>, qui est entourée d’une balise h4, et que le lien a une classe de titre. Cela signifie que vous recherchez des balises <a href> (URL) à l’intérieur de balises <h4> qui ont une classe de titre.
Pour créer un programme de scraping qui cible précisément ces éléments, vous devez importer les bibliothèques afin de créer une fonction Python, lancer le navigateur et accéder au site web cible :
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
Notez que l’URL cible dans la fonction page.goto() a été mise à jour pour pointer vers la première page contenant la liste des ordinateurs portables.
Une fois que vous avez créé le programme de scraping, vous devez localiser l’élément cible en fonction de l’analyse de la structure de votre site web. Playwright dispose d’un outil appelé« locators »qui vous permet de localiser des éléments sur une page en fonction de divers attributs, tels que les suivants :
get_by_label()localise l’élément cible à l’aide du libellé associé à un élément.get_by_text()localise l’élément cible à l’aide du texte qu’il contient.get_by_alt_text()localise l’élément cible et effectue des actions sur les images à l’aide de leur texte alternatif.get_by_test_id()localise l’élément cible à l’aide de l’ID de test d’un élément.
Vous pouvez consulterla documentation officiellepour découvrir d’autres méthodes permettant de localiser des éléments.
Pour extraire tous les titres des ordinateurs portables, vous devez localiser les balises <h4> car elles englobent tous les titres des ordinateurs portables. Vous pouvez utiliser le localisateur get_by_role() pour trouver des éléments en fonction de leur fonction, tels que les boutons, les cases à cocher et les en-têtes. Cela signifie que pour trouver tous les en-têtes de la page, vous devez écrire ce qui suit :
titles = page.get_by_role("heading").all()
Ensuite, vous pouvez l’imprimer dans votre console à l’aide du code suivant :
print(titles)
Après l’impression, vous remarquerez qu’il donne un tableau d’éléments :
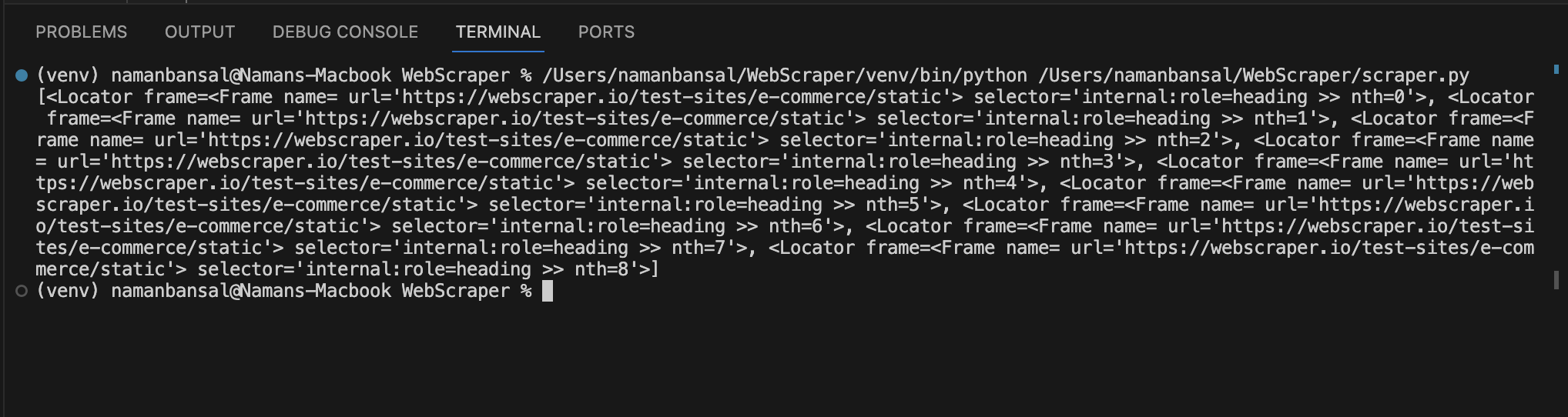
Cette sortie n’inclut pas les titres, mais elle fait référence aux éléments correspondant aux conditions du sélecteur. Vous devez parcourir ces éléments pour trouver une balise <a> avec une classe title et le texte qu’elle contient.
Il est recommandé d’utiliser le localisateur CSS pour trouver un élément en fonction de son chemin et de sa classe. Vous pouvez utiliser la fonction all_inner_texts() pour extraire le texte interne d’un élément comme ceci :
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
Après avoir exécuté ce code, votre résultat devrait ressembler à ceci :
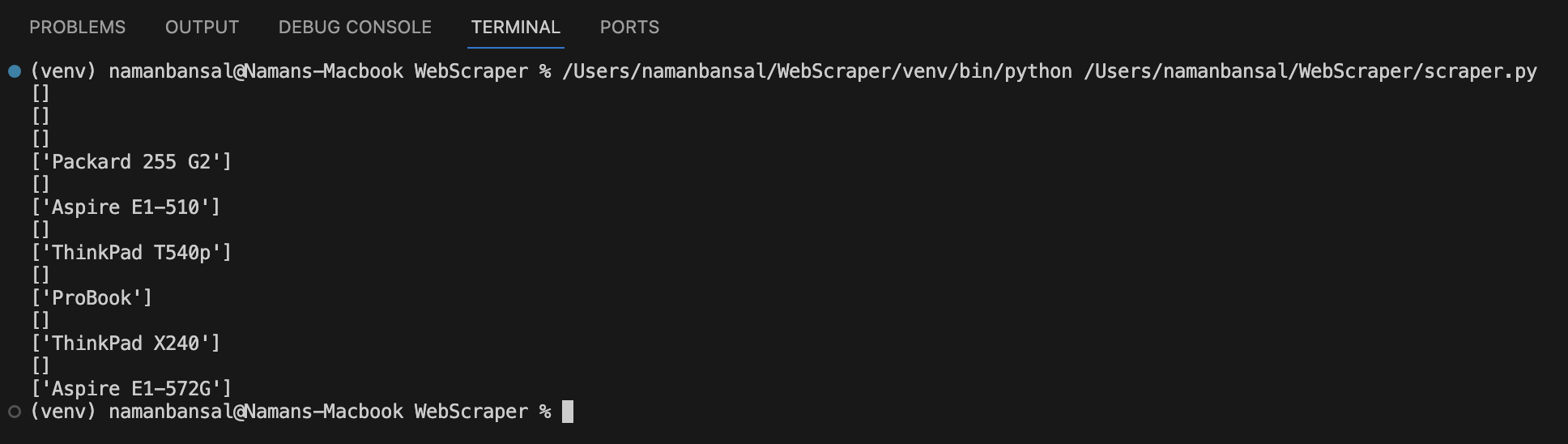
Pour rejeter les tableaux sans valeurs, écrivez ce qui suit :
if len(laptop) == 1:
print(laptop[0])
Une fois que vous avez rejeté les tableaux sans valeurs, vous avez réussi à créer un programme de scraping qui extrait uniquement des éléments spécifiques.
Voici le code complet de ce Scraper :
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
main()
Interagir avec les éléments
Passons maintenant à la vitesse supérieure et créons un programme qui extrait les titres de la première page contenant des ordinateurs portables, navigue vers la deuxième page et extrait également ces titres.
Comme vous savez déjà comment extraire les titres d’une page, il vous suffit de trouver comment passer à la page suivante consacrée aux ordinateurs portables.
Vous avez peut-être déjà remarqué les boutonsde paginationsur la page où vous vous trouvez actuellement.
Vous devez localiserle 2et cliquer dessus à l’aide de votre programme de scraping. En inspectant la page, vous verrez que l’élément requis est un élément de liste (balise<li>) et qu’il contient le texte2:
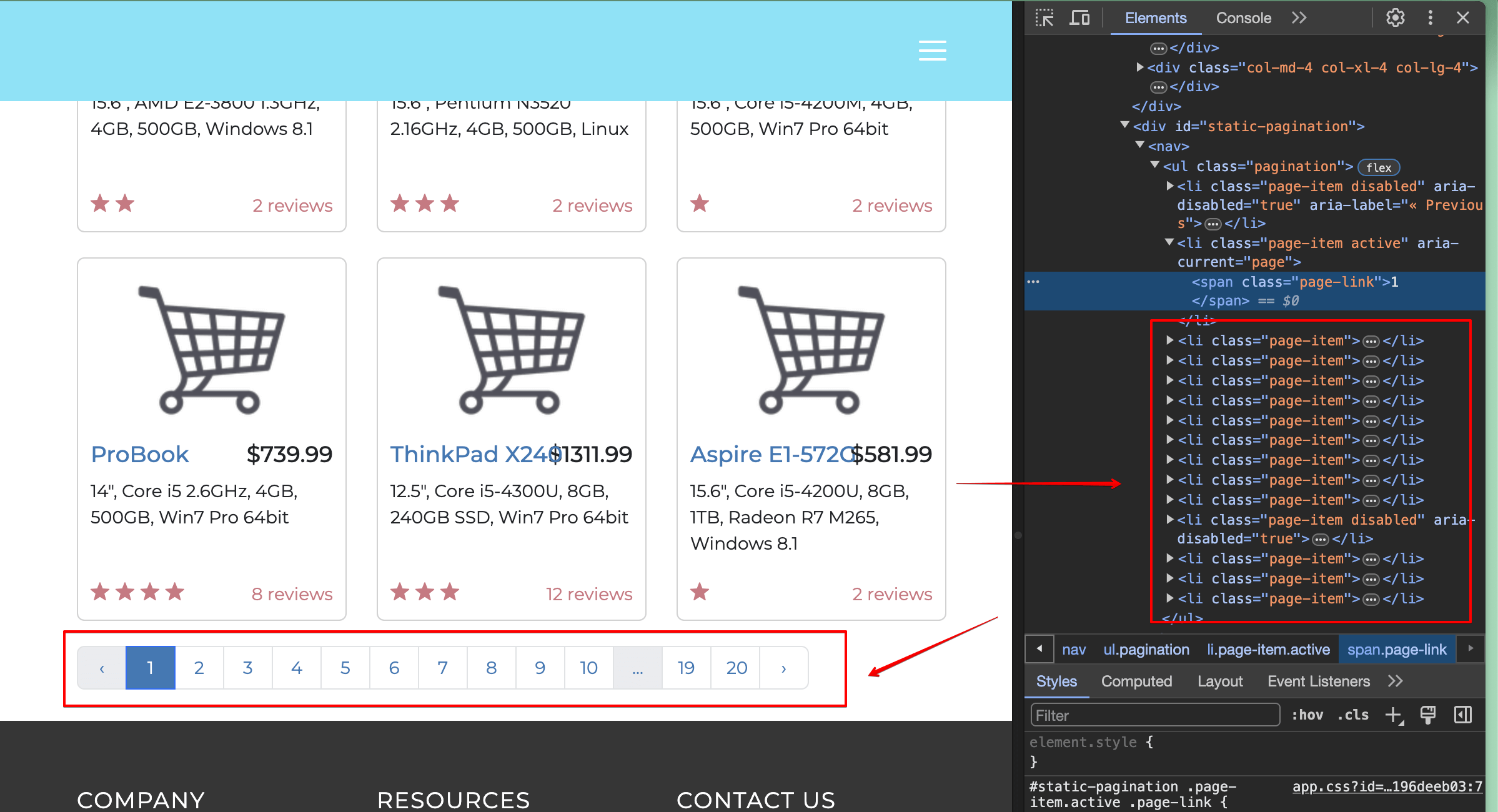
Cela signifie que vous pouvez utiliser le sélecteur get_by_role() pour trouver un élément de liste et le sélecteur get_by_text() pour trouver un élément dont le texte est 2.
Voici comment le coder dans votre fichier :
page.get_by_role("listitem").get_by_text("2", exact=True)
Cela permet de trouver un élément qui répond à deux conditions : premièrement, il doit s’agir d’un élément de liste et, deuxièmement, il doit avoir 2 comme texte.
exact=True est un argument de fonction permettant de trouver l’élément avec le texte donné.
Pour cliquer sur le bouton, modifiez le code précédent afin qu’il ressemble à ceci :
page.get_by_role("listitem").get_by_text("2", exact=True).click()
Dans ce code, la fonction click() clique sur l’élément donné.
Attendez que la page se charge et extrayez à nouveau tous les titres :
page.wait_for_timeout(5000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
Votre bloc de code complet devrait ressembler à ceci :
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
page.get_by_role("listitem").get_by_text("2", exact=True).click()
page.wait_for_timeout(5000)
titres = page.get_by_role("heading").all()
pour titre dans titres :
ordinateur portable = titre.locator("a.title").all_inner_texts()
si len(ordinateur portable) == 1 :
print(ordinateur portable[0])
main()
Extraire le code HTML et l’écrire dans un fichier CSV
Si vous ne stockez pas et n’analysez pas les données que vous récupérez, elles sont inutiles. Dans cette section, vous allez créer un programme avancé qui prend en compte les données saisies par l’utilisateur concernant le nombre de pages d’ordinateurs portables à récupérer, extrait les titres et les stocke dans un fichier CSV dans votre dossier de projet.
Pour ce programme, vous avez besoin d’une bibliothèque CSV préinstallée, qui peut être importée à l’aide de la commande suivante :
import csv
Une fois la bibliothèque CSV installée, vous devez déterminer comment vous allez visiter un nombre variable de pages en fonction des données saisies par l’utilisateur.
Si vous examinez la structure des URL du site web, vous remarquerez que chaque page d’ordinateurs portables est indiquée à l’aide d’un paramètre URL. Par exemple, l’URL de la deuxième page du répertoire des ordinateurs portables est https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page=2.
Vous pouvez visiter différentes pages en modifiant le paramètre URL ?page=2 avec différentes valeurs numériques. Cela signifie que vous devez demander à l’utilisateur de saisir le nombre de pages à extraire à l’aide de la commande suivante :
pages = int(input("entrez le nombre de pages à extraire : "))
Pour visiter chaque page de 1 au nombre de pages saisi par l’utilisateur, vous utilisez une boucle for comme ceci :
for i in range(1, pages+1):
Dans cette fonction range, vous utilisez 1 et pages+1 comme arguments de fonction pour représenter les valeurs auxquelles la boucle commence et se termine. Le deuxième argument de fonction est exclu de la boucle. Par exemple, si la fonction range est range(1,5), le programme ne bouclera que de 1 à 4.
Ensuite, vous devez visiter chaque page en entrant la valeuricomme paramètre URL dans l’itération. Vous pouvez ajouter des variables à une chaîne à l’aidedes chaînes f Python.
Lorsque vous affichez une chaîne, vous préfixez les guillemets avec un f pour indiquer qu’il s’agit d’une chaîne f. À l’intérieur des guillemets, vous pouvez utiliser des accolades pour indiquer les variables.
Voici un exemple d’utilisation des chaînes f pour afficher des variables avec des chaînes :
print(f"La valeur de la variable est {variable_name_goes_here}")
Pour en revenir au Scraper, vous pouvez utiliser les chaînes f en écrivant ce bloc de code dans le fichier :
try:
page.goto(f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={i}")
except:
print("Error")
Attendez que la page se charge avec une fonction de délai d’expiration et extrayez les titres à l’aide de la commande suivante :
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
Une fois que vous avez tous les éléments de titre, vous devez ouvrir votre fichier CSV, parcourir chaque titre, extraire le texte requis et l’écrire dans votre fichier.
Pour ouvrir un fichier CSV, utilisez la syntaxe suivante :
with open("laptops.csv", "a") as csvfile:
Ici, vous ouvrez le fichierlaptops.csven mode append (a). Vous utilisez le mode append ici parce que vous ne voulez pas perdre les anciennes données à chaque fois que le fichier est ouvert. Si le fichier n’existe pas, la bibliothèque en crée un dans le dossier du projet.CSV propose plusieurs modespour ouvrir un fichier, notamment les suivants :
- rest l’option par défaut utilisée si rien n’est spécifié. Elle ouvre le fichier en lecture seule.
- wouvre un fichier en écriture seule. Chaque fois qu’un fichier est ouvert, les données précédentes sont écrasées.
- aouvre un fichier pour ajouter des données. Les données précédentes ne sont pas écrasées.
- r+ouvre un fichier en lecture et en écriture.
- xcrée un nouveau fichier.
Sous le code précédent, vous devezdéclarer un objetwriterqui vous permet de manipuler le fichier CSV :
writer = csv.writer(csvfile)
Ensuite, parcourez chaque élément title et extrayez le texte à l’aide de la commande suivante :
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
Vous obtenez ainsi plusieurs tableaux, chacun contenant le titre d’un ordinateur portable. Pour rejeter les tableaux vides, écrivez le code conditionnel suivant dans le fichier CSV :
if len(laptop) == 1:
writer.writerow([laptop[0]])
La fonction writerow vous permet d’écrire de nouvelles lignes dans un fichier CSV.
Voici le code complet du programme :
from playwright.sync_api import sync_playwright
import csv
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
pages = int(input("enter the number of pages to scrape: "))
for i in range(1, pages+1):
try:
page.goto(f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={i}")
except:
print("Error")
page.wait_for_timeout(7000)
titres = page.get_by_role("heading").all()
avec open("laptops.csv", "a") comme csvfile :
writer = csv.writer(csvfile)
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
writer.writerow([laptop[0]])
browser.close()
main()
Après avoir exécuté ce code, votre fichier CSV devrait ressembler à ceci :
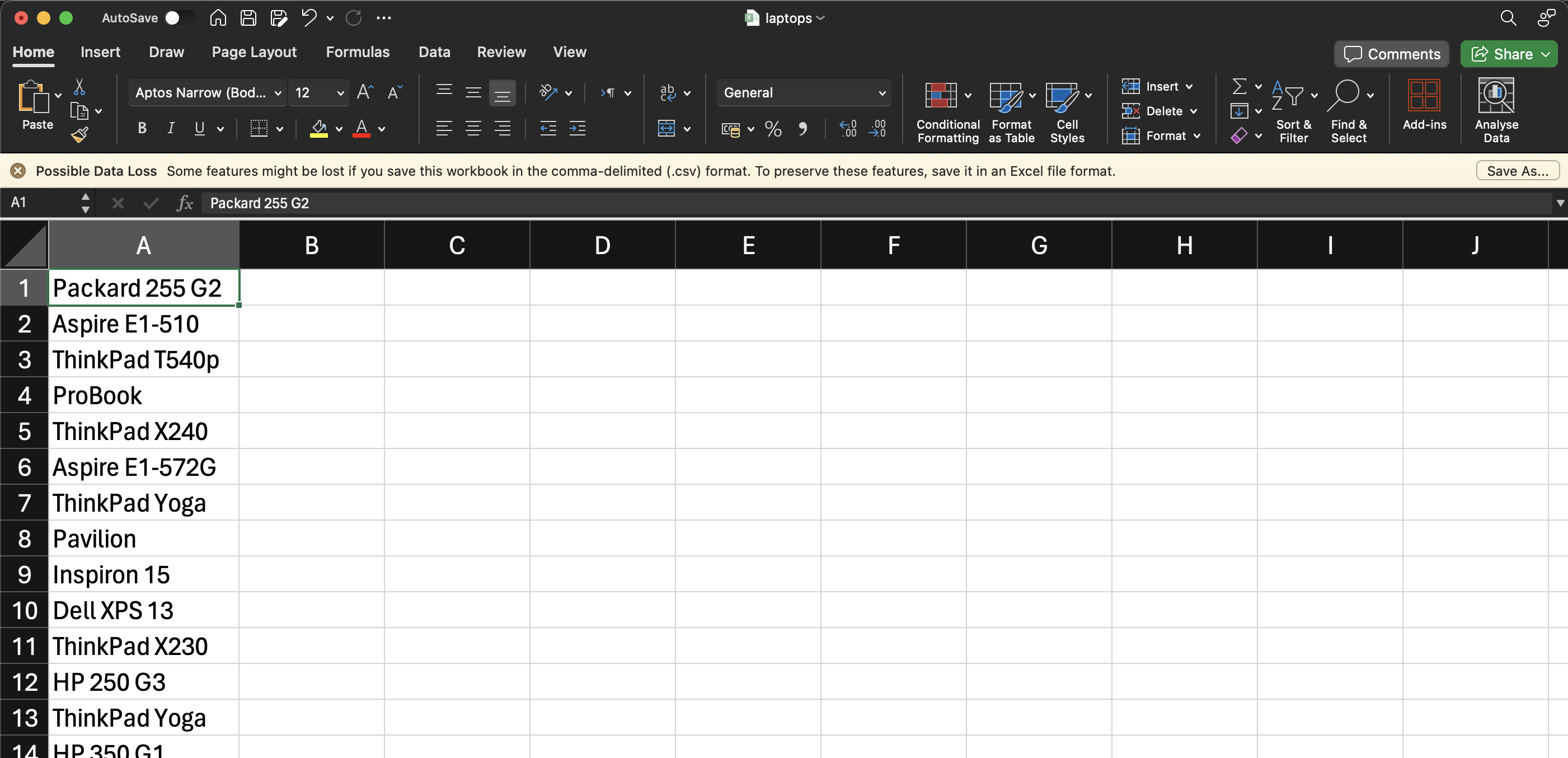
Conclusion
Dans cet article, vous avez appris à extraire, analyser et stocker du code HTML à l’aide de Python.
Bien que ce tutoriel soit relativement simple, dans la réalité, vous rencontrerez probablement divers obstacles lors du scraping, notamment des CAPTCHA, des limites de débit, des changements de mise en page du site web ou des exigences réglementaires. Heureusement,Bright Datapeut vous aider. Bright Data propose des outils tels quedes Proxys résidentiels avancéspour améliorer votre scraping, unIDEWebScraperpour créer des Scrapers à grande échelle et unWeb Unblockerpour débloquer les sites web publics, y compris la résolution de CAPTCHA. Ces outils peuvent vous aider à collecter des données précises à grande échelle et à surmonter les obstacles. De plus, l’engagement de Bright Data en faveur d’un scraping éthique vous garantit de rester dans le cadre des conditions d’utilisation des sites web et des réglementations légales.
Grâce à la plateforme riche en fonctionnalités de Bright Data, vous pouvez vous concentrer sur l’extraction des données précieuses dont vous avez besoin, en laissant derrière vous les complexités du Scraping web. Commencez votre essai gratuit dès aujourd’hui !



