

Le web scraping nécessite souvent de naviguer dans les mécanismes anti-bots, de charger du contenu dynamique à l’aide d’outils d’automatisation du navigateur tels que Puppeteer, d’utiliser la rotation de proxy pour éviter les blocages d’IP et de résoudre les CAPTCHAs. Même avec ces stratégies, la mise à l’échelle et le maintien de sessions stables restent un défi.
Cet article vous explique comment passer du scraping traditionnel basé sur un proxy à Bright Data Scraping Browser. Apprenez à automatiser la gestion et la mise à l’échelle du proxy afin de réduire les coûts de développement et de maintenance. Les deux méthodes sont comparées et couvrent la configuration, les performances, l’évolutivité et la complexité.
Remarque : les exemples présentés dans cet article sont donnés à des fins éducatives. Consultez toujours les conditions d’utilisation du site web cible et respectez les lois et réglementations en vigueur avant de récupérer des données.
Conditions préalables
Avant de commencer le tutoriel, assurez-vous que vous disposez des prérequis suivants :
- Node.js
- Code Visual Studio
- Un compte Bright Data gratuit pour pouvoir utiliser leur navigateur de scraping
Commencez par créer un nouveau dossier de projet Node.js dans lequel vous pourrez stocker votre code.
Ensuite, ouvrez votre terminal ou votre shell et créez un nouveau répertoire à l’aide des commandes suivantes :
mkdir scraping-tutorialrncd scraping-tutorial
Initialiser un nouveau projet Node.js :
npm init -y
L’option -y répond automatiquement oui à toutes les questions et crée un fichier package.json avec les paramètres par défaut.
Récupération de données sur le Web à partir d’un proxy
Dans une approche typique basée sur un proxy, vous utilisez un outil d’automatisation de navigateur comme Puppeteer pour interagir avec votre domaine cible, charger du contenu dynamique et extraire des données. Ce faisant, vous intégrez des proxys pour éviter les interdictions d’IP et préserver l’anonymat.
Créons rapidement un script de scraping web à l’aide de Puppeteer qui récupère les données d’un site de commerce électronique à l’aide de proxies.
Créer un script de balayage du Web à l’aide de Puppeteer
Commencez par installer Puppeteer :
npm install puppeteer
Ensuite, créez un fichier appelé proxy-scraper.js (vous pouvez lui donner le nom que vous voulez) dans le dossier scraping-tutorial et ajoutez le code suivant :
const puppeteer = require(u0022puppeteeru0022);rnrn(async () =u0026gt; {rn // Launch a headless browserrn const browser = await puppeteer.launch({rn headless: true,rn });rn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(books); // Print the collected datarnrn await browser.close();rn})();rn
Ce script utilise Puppeteer pour récupérer les titres et les prix des livres sur les cinq premières pages du site Web Books to Scrape. Il lance un navigateur sans tête, ouvre une nouvelle page et parcourt chaque page du catalogue.
Pour chaque page, le script utilise les sélecteurs DOM dans page.evaluate() pour extraire les titres et les prix des livres, en stockant les données dans un tableau. Une fois toutes les pages traitées, les données sont imprimées sur la console et le navigateur est fermé. Cette approche permet d’extraire efficacement les données d’un site web paginé.
Testez et exécutez le code à l’aide de la commande suivante :
node proxy-scraper.jsVotre résultat devrait ressembler à ceci :
Navigating to: https://books.toscrape.com/catalogue/page-1.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-2.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-3.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-4.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-5.htmlrn[rn { title: 'A Light in the Attic', price: '£51.77' },rn { title: 'Tipping the Velvet', price: '£53.74' },rn { title: 'Soumission', price: '£50.10' },rn { title: 'Sharp Objects', price: '£47.82' },rn { title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },rn { title: 'The Requiem Red', price: '£22.65' },rn…output omitted…rn {rn title: 'In the Country We Love: My Family Divided',rn price: '£22.00'rn }rn]
Mise en place de Proxies
Les proxys sont couramment utilisés dans les configurations de scraping pour diviser les demandes et les rendre intraçables. Une approche courante consiste à maintenir un pool de proxys et à les faire tourner de manière dynamique.
Placez vos mandataires dans un tableau ou stockez-les dans un fichier séparé si vous le souhaitez :
const proxies = [rn u0022proxy1.example.com:portu0022, rn u0022proxy2.example.com:portu0022rn // Add more proxies herern];
Utiliser la logique de rotation des mandataires
Améliorons le code avec une logique qui fait tourner le tableau de proxy à chaque fois que vous lancez le navigateur. Mettez à jour le fichier proxy-scraper.js pour y inclure le code suivant :
const puppeteer = require(u0022puppeteeru0022);rnrnconst proxies = [rn u0022proxy1.example.com:portu0022, rn u0022proxy2.example.com:portu0022rn // Add more proxies herern];rnrn(async () =u0026gt; {rn // Choose a random proxyrn const randomProxy =rn proxies[Math.floor(Math.random() * proxies.length)];rnrn // Launch Puppeteer with proxyrn const browser = await puppeteer.launch({rn headless: true,rn args: [rn `u002du002dproxy-server=http=${randomProxy}`,rn u0022u002du002dno-sandboxu0022,rn u0022u002du002ddisable-setuid-sandboxu0022,rn u0022u002du002dignore-certificate-errorsu0022,rn ],rn });rnrn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(`Using proxy: ${randomProxy}`);rn console.log(books); // Print the collected datarnrn await browser.close();rn})();rn
Note : Au lieu de faire la rotation des proxies manuellement, vous pouvez utiliser une bibliothèque comme luminati-proxy pour automatiser le processus.
Dans ce code, un proxy aléatoire est sélectionné dans la liste des proxies et appliqué à Puppeteer à l’aide de l’option --proxy-server=${randomProxy}. Pour éviter toute détection, une chaîne d’agent utilisateur aléatoire est également attribuée. La logique de scraping est ensuite répétée et le proxy utilisé pour le scraping des données produit est enregistré.
Lorsque vous exécutez à nouveau le code, vous devriez voir une sortie comme précédemment, mais avec un ajout au proxy qui a été utilisé :
Navigating to: https://books.toscrape.com/catalogue/page-1.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-2.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-3.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-4.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-5.htmlrnUsing proxy: 115.147.63.59:8081rn…output omitted…
Défis du scraping basé sur un proxy
Bien qu’une approche basée sur un proxy puisse fonctionner pour de nombreux cas d’utilisation, vous pouvez être confronté à certains des défis suivants :
- Blocages fréquents : les proxys peuvent être bloqués si le site dispose d’une détection anti-bot stricte.
- Frais généraux liés aux performances : la rotation des serveurs mandataires et la relance des demandes ralentissent votre pipeline de collecte de données.
- Évolutivité complexe : la gestion et la rotation d’un grand pool de serveurs mandataires en vue d’obtenir des performances et une disponibilité optimales sont complexes. Il faut équilibrer la charge, empêcher la surutilisation des serveurs mandataires, prévoir des périodes de refroidissement et gérer les défaillances en temps réel. Le défi s’accroît avec les requêtes simultanées, car le système doit échapper à la détection tout en surveillant et en remplaçant en permanence les IP figurant sur la liste noire ou dont les performances sont insuffisantes.
- Maintenance du navigateur : la maintenance du navigateur peut s’avérer à la fois difficile sur le plan technique et gourmande en ressources. Vous devez continuellement mettre à jour et gérer l’empreinte digitale du navigateur (cookies, en-têtes et autres attributs d’identification) pour imiter le comportement réel de l’utilisateur et échapper aux contrôles anti-bots avancés.
- Frais généraux des navigateurs en nuage : les navigateurs en nuage génèrent des frais généraux opérationnels supplémentaires en raison des exigences accrues en matière de ressources et du contrôle complexe de l’infrastructure, ce qui entraîne des dépenses opérationnelles élevées. La mise à l’échelle des instances du navigateur pour assurer des performances constantes complique encore le processus.
DynamicScraping avec le navigateur Bright Data Scraping Browser
Pour relever ces défis, vous pouvez utiliser une solution API unique telle que le navigateur de récupération de données Bright. Cette solution simplifie vos opérations, élimine la nécessité d’une rotation manuelle du proxy et d’une configuration complexe du navigateur, et permet souvent d’obtenir un taux de réussite plus élevé dans la récupération des données.
Configurer votre compte Bright Data
Pour commencer, connectez-vous à votre compte Bright Data et accédez à Proxies & Scraping, faites défiler vers le bas jusqu’à Scraping Browser et cliquez sur Get Started:
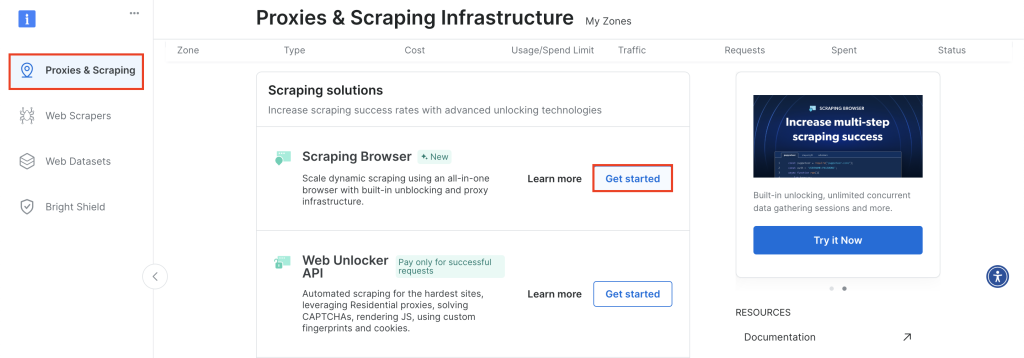
Conservez la configuration par défaut et cliquez sur Ajouter pour créer une nouvelle instance de Scraping Browser :
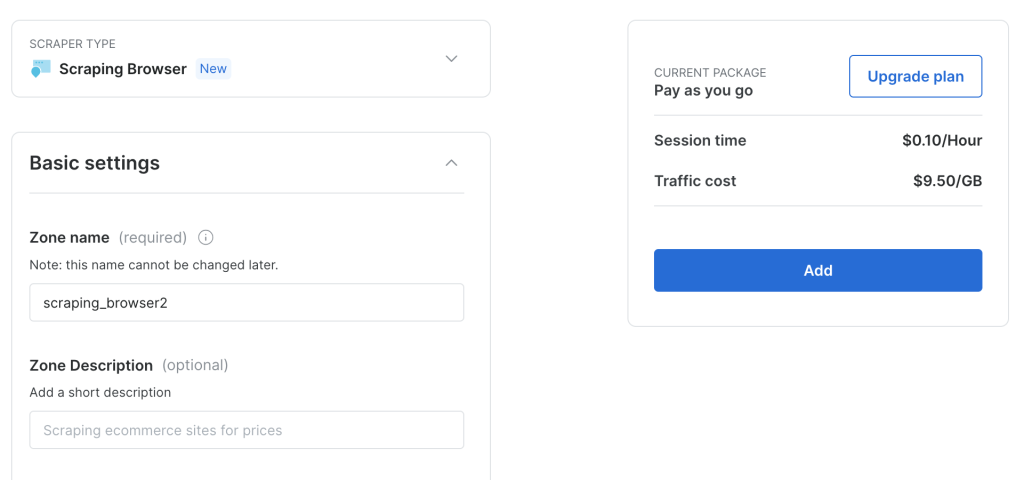
Après avoir créé une instance de Scraping Browser, notez l’URL de Puppeteer car vous en aurez bientôt besoin :
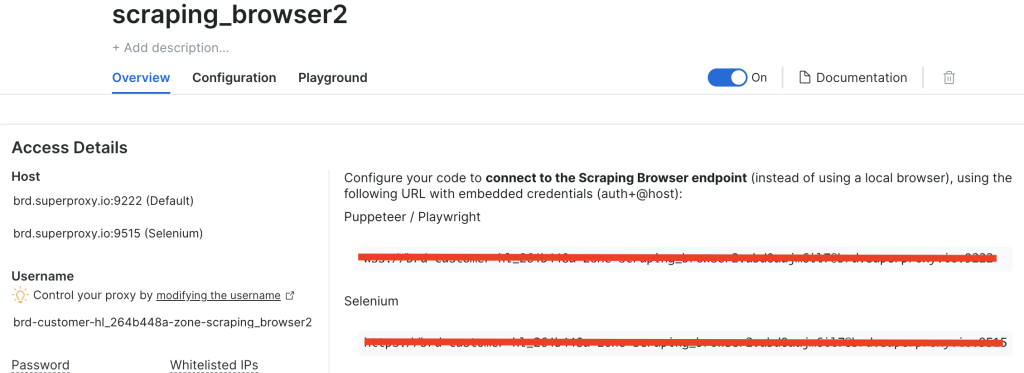
Ajuster le code pour utiliser le navigateur Bright Data Scraping
Maintenant, ajustons le code pour qu’au lieu d’utiliser des proxies rotatifs, vous vous connectiez directement au point de terminaison du navigateur de capture de données Bright.
Créez un nouveau fichier appelé brightdata-scraper.js et ajoutez le code suivant :
const puppeteer = require(u0022puppeteeru0022);rnrn(async () =u0026gt; {rn // Choose a random proxyrn const SBR_WS_ENDPOINT = u0022YOUR_BRIGHT_DATA_WS_ENDPOINTu0022rnrn // Launch Puppeteer with proxyrn const browser = await puppeteer.connect({rn browserWSEndpoint: SBR_WS_ENDPOINT,rn });rnrn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(books); // Print the collected datarnrn await browser.close();rn})();
Veillez à remplacer YOUR_BRIGHT_DATA_WS_ENDPOINT par l’URL que vous avez récupérée à l’étape précédente.
Ce code est similaire au code précédent, mais au lieu d’avoir une liste de proxies et de jongler entre les différents proxies, vous vous connectez directement au point de terminaison de Bright Data.
Exécutez le code suivant :
node brightdata-scraper.js
Votre résultat devrait être le même qu’auparavant, mais vous n’aurez plus besoin d’effectuer manuellement la rotation des proxys ou de configurer les agents utilisateurs. Le navigateur Bright Data Scraping Browser gère tout, de la rotation des proxys au contournement des CAPTCHA, pour garantir un scraping de données ininterrompu.
Transformer le code en un point d’accès express
Si vous souhaitez intégrer le navigateur Bright Data Scraping Browser à une application plus vaste, envisagez de l’exposer en tant que point de terminaison Express.
Commencez par installer Express :
npm install express
Créez un fichier appelé server.js et ajoutez le code suivant :
const express = require(u0022expressu0022);rnconst puppeteer = require(u0022puppeteeru0022);rnrnconst app = express();rnconst PORT = 3000;rnrn// Needed to parse JSON bodies:rnapp.use(express.json());rnrn// Your Bright Data Scraping Browser WebSocket endpointrnconst SBR_WS_ENDPOINT =rn u0022wss://brd-customer-hl_264b448a-zone-scraping_browser2:[email protected]:9222u0022;rnrn/**rn POST /scraperrn Body example:rn {rn u0022baseUrlu0022: u0022https://books.toscrape.com/catalogue/page-u0022rn }rn*/rnapp.post(u0022/scrapeu0022, async (req, res) =u0026gt; {rn const { baseUrl } = req.body;rnrn if (!baseUrl) {rn return res.status(400).json({rn success: false,rn error: 'Missing u0022baseUrlu0022 in request body.',rn });rn }rnrn try {rn // Connect to the existing Bright Data (Luminati) Scraping Browserrn const browser = await puppeteer.connect({rn browserWSEndpoint: SBR_WS_ENDPOINT,rn });rnrn const page = await browser.newPage();rn const books = [];rnrn // Example scraping 5 pages of the base URLrn for (let i = 1; i {rn const data = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn const title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn const price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn data.push({ title, price });rn });rn return data;rn });rnrn books.push(...pageBooks);rn }rnrn // Close the browser connectionrn await browser.close();rnrn // Return JSON with the scraped datarn return res.json({rn success: true,rn books,rn });rn } catch (error) {rn console.error(u0022Scraping error:u0022, error);rn return res.status(500).json({rn success: false,rn error: error.message,rn });rn }rn});rnrn// Start the Express serverrnapp.listen(PORT, () =u0026gt; {rn console.log(`Server is listening on http://localhost:${PORT}`);rn});
Dans ce code, vous initialisez une application Express, acceptez des charges utiles JSON et définissez une route POST /scrape. Les clients envoient un corps JSON contenant l’URL de base, qui est ensuite transmis au point d’extrémité du navigateur de capture de données Bright avec l’URL ciblée.
Exécutez votre nouveau serveur Express :
node server.js
Pour tester le point d’accès, vous pouvez utiliser un outil comme Postman (ou tout autre client REST de votre choix), ou vous pouvez utiliser curl à partir de votre terminal ou shell comme ceci :
curl -X POST http://localhost/scrape rn-H 'Content-Type: application/json' rn-d '{u0022baseUrlu0022: u0022https://books.toscrape.com/catalogue/page-u0022}'rn
Votre résultat devrait ressembler à ceci :
{rn u0022successu0022: true,rn u0022booksu0022: [rn {rn u0022titleu0022: u0022A Light in the Atticu0022,rn u0022priceu0022: u0022£51.77u0022rn },rn {rn u0022titleu0022: u0022Tipping the Velvetu0022,rn u0022priceu0022: u0022£53.74u0022rn },rn {rn u0022titleu0022: u0022Soumissionu0022,rn u0022priceu0022: u0022£50.10u0022rn },rn {rn u0022titleu0022: u0022Sharp Objectsu0022,rn u0022priceu0022: u0022£47.82u0022rn },rn {rn u0022titleu0022: u0022Sapiens: A Brief History of Humankindu0022,rn u0022priceu0022: u0022£54.23u0022rn },rn {rn u0022titleu0022: u0022The Requiem Redu0022,rn u0022priceu0022: u0022£22.65u0022rn },rn {rn u0022titleu0022: u0022The Dirty Little Secrets of Getting Your Dream Jobu0022,rn u0022priceu0022: u0022£33.34u0022rn },rn {rn u0022titleu0022: u0022The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhullu0022,rn u0022priceu0022: u0022£17.93u0022rn },rn rn ... output omitted...rn rn {rn u0022titleu0022: u0022Judo: Seven Steps to Black Belt (an Introductory Guide for Beginners)u0022,rn u0022priceu0022: u0022£53.90u0022rn },rn {rn u0022titleu0022: u0022Joinu0022,rn u0022priceu0022: u0022£35.67u0022rn },rn {rn u0022titleu0022: u0022In the Country We Love: My Family Dividedu0022,rn u0022priceu0022: u0022£22.00u0022rn }rn ]rn}
Le diagramme suivant illustre le contraste entre la configuration manuelle (proxy rotatif) et l’approche du navigateur Bright Data Scraping :
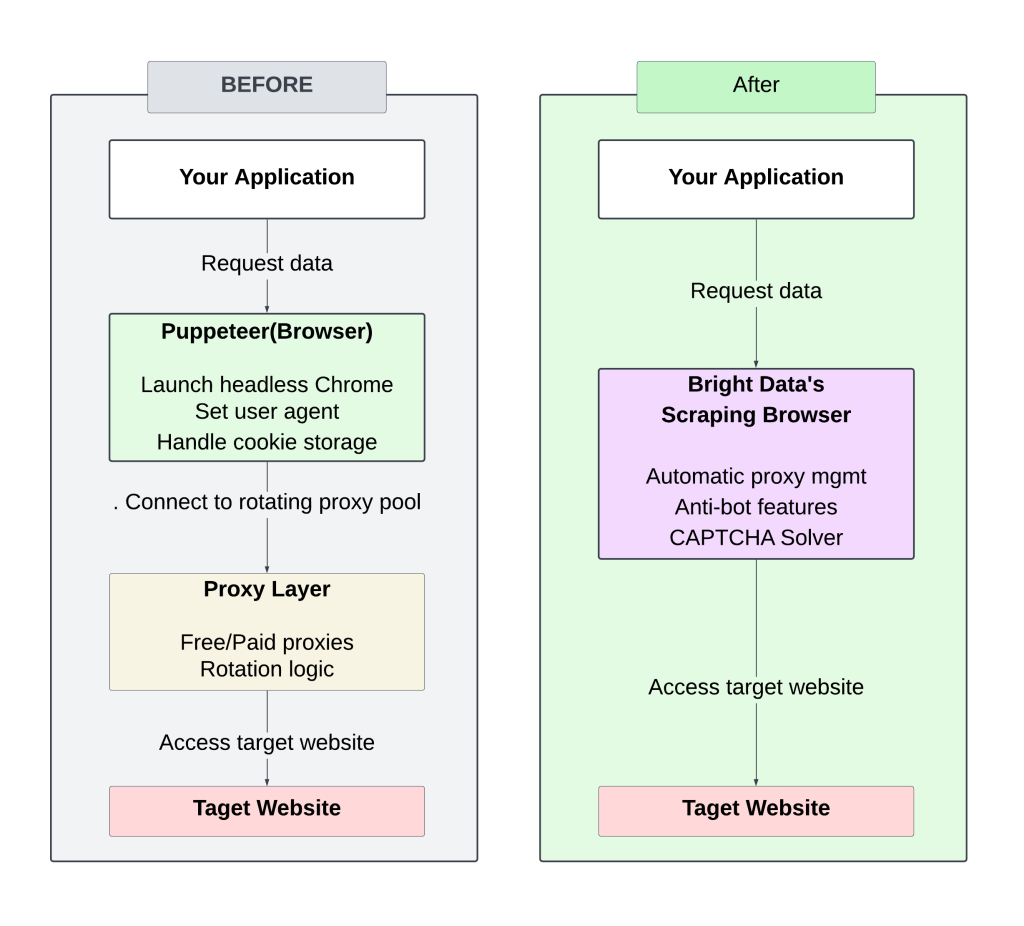
La gestion des serveurs mandataires à rotation manuelle nécessite une attention et un réglage constants, ce qui entraîne des blocages fréquents et une évolutivité limitée.
L’utilisation du navigateur Bright Data Scraping Browser rationalise le processus en éliminant la nécessité de gérer des proxys ou des en-têtes, tout en offrant des temps de réponse plus rapides grâce à une infrastructure optimisée. Ses stratégies anti-bots intégrées augmentent les taux de réussite, ce qui réduit les risques de blocage ou de marquage.
Tout le code de ce tutoriel est disponible dans ce dépôt GitHub.
Calculer le retour sur investissement
Le passage d’une configuration de scraping manuelle basée sur un proxy à Bright Data Scraping Browser permet de réduire considérablement le temps et les coûts de développement.
Configuration traditionnelle
La recherche quotidienne de sites d’information nécessite les éléments suivants :
- Développement initial : ~50 heures (5 000 USD à 100 USD/heure)
- Maintenance continue : ~10 heures/mois (1 000 USD) pour les mises à jour du code, l’infrastructure, la mise à l’échelle et la gestion du proxy.
- Coût du proxy/IP : ~250 USD/mois (varie en fonction des besoins en IP)
Coût mensuel total estimé : ~1 250 USD
Configuration du navigateur Bright Data Scraping
- Temps de développement : 5-10 heures ($1,000 USD)
- Maintenance : ~2-4 heures/mois ($200 USD)
- Aucune gestion de proxy ou d’infrastructure n’ est nécessaire
- Coûts des services de Bright Data :
- Utilisation du trafic : $8.40 USD/GB(par exemple 30GB/mois = $252 USD)
Coût mensuel total estimé : ~450 USD
L’automatisation de la gestion du proxy et la mise à l’échelle du navigateur Bright Data Scraping Browser réduisent à la fois les coûts de développement initiaux et la maintenance continue, ce qui rend le scraping de données à grande échelle plus efficace et plus rentable.
Conclusion
Le passage d’une configuration de scraping web traditionnelle basée sur un proxy à Bright Data Scraping Browser élimine les problèmes de rotation de proxy et de gestion manuelle des anti-bots.
Au-delà de la récupération du code HTML, Bright Data propose également des outils supplémentaires pour rationaliser l’extraction des données :
- Web Scrapers pour vous aider à mettre de l’ordre dans vos extractions de données
- L’API de Web Unlocker pour explorer des sites plus complexes
- Les ensembles de données vous permettent d’accéder à des données structurées pré-collectées.
Ces solutions peuvent simplifier votre processus de scraping, réduire la charge de travail et améliorer l’évolutivité.





