

Le web scraping est le processus de collecte automatique de données à partir de sites Web à des fins telles que l’analyse des données ou la mise au point de modèles d’IA.
Python est un choix populaire pour le web scraping en raison de sa vaste gamme de bibliothèques de scraping, dont lxml, qui est utilisée pour analyser des documents XML et HTML. lxml étend les capacités de Python avec une API Python pour les bibliothèques C rapides que sont libxml2 et libxslt. Il s’intègre également à ElementTree, la structure de données hiérarchique de Python pour les arbres XML/HTML, faisant de lxml un outil privilégié pour un web scraping efficace et fiable.
Dans cet article, vous allez apprendre à utiliser lxml pour le web scraping.
Les solutions Bright Data, l’alternative parfaite
En matière de web scraping, l’utilisation de lxml avec Python est une approche efficace, mais elle peut être longue et coûteuse, en particulier lorsqu’il s’agit de sites Web complexes ou de gros volumes de données. Bright Data propose une alternative efficace avec ses ensembles de données prêts à l’emploi et API Web Scraper. Ces solutions réduisent considérablement le temps et les coûts liés à la collecte de données en fournissant des données précollectées provenant de plus de 100 domaines et des API de scraping faciles à intégrer.
Avec Bright Data, vous pouvez contourner les défis techniques liés au scraping manuel, en vous concentrant sur l’analyse des données plutôt que sur leur récupération. Que vous ayez besoin d’ensembles de données adaptés à vos besoins spécifiques ou d’API qui gèrent la gestion des proxys et la résolution des CAPTCHA, les outils de Bright Data offrent une solution rationalisée et rentable pour tous vos besoins en matière de web scraping.
Utilisation de lxml pour le Web Scraping en Python
Sur le Web, les données structurées et hiérarchiques peuvent être représentées dans deux formats: HTML et XML:
- Le XML est une structure de base qui ne comporte pas de balises ni de styles prédéfinis. Le codeur crée la structure en définissant ses propres balises. L’objectif principal de la balise est de créer une structure de données standard qui peut être comprise entre différents systèmes.
- Le HTML est un langage de balisage Web avec des balises prédéfinies. Ces balises sont dotées de certaines propriétés de style, telles que
font-sizedans les balises <h1>oudisplaypour les balises<img />. La fonction principale du HTML est de structurer efficacement les pages Web.
lxml fonctionne à la fois avec les documents HTML et XML.
Prérequis
Avant de commencer le web scraping avec lxml, vous devez installer quelques bibliothèques sur votre machine:
pip install lxml requests cssselect
Cette commande installe les éléments suivants:
- lxml pour analyser le XML et le HTML
- demandes pour récupérer des pages Web
- cssselect, qui utilise des sélecteurs CSS pour extraire des éléments HTML
Analyse du contenu HTML statique
Deux principaux types de contenu Web peuvent être extraits: le contenu statique et le contenu dynamique. Le contenu statique est intégré au document HTML lors du chargement initial de la page web, ce qui permet de le récupérer facilement. En revanche, le contenu dynamique est chargé en continu ou déclenché par JavaScript après le chargement initial de la page. Le scraping de contenu dynamique nécessite de déclencher l’exécution de la fonction de scraping uniquement une fois que le contenu est disponible dans le navigateur.
Dans cet article, vous commencez par extraire le site de Books to Scrape, dont le contenu HTML statique est conçu à des fins de test. Vous extrayez les titres et les prix des livres et vous enregistrez ces informations dans un fichier JSON.
Pour commencer, utilisez les outils de développement de votre navigateur pour identifier les éléments HTML pertinents. Ouvrez Dev Tools en cliquant avec le bouton droit sur la page Web et en sélectionnant l’option Inspect . Si vous utilisez Chrome, vous pouvez appuyer sur F12 pour accéder à ce menu:
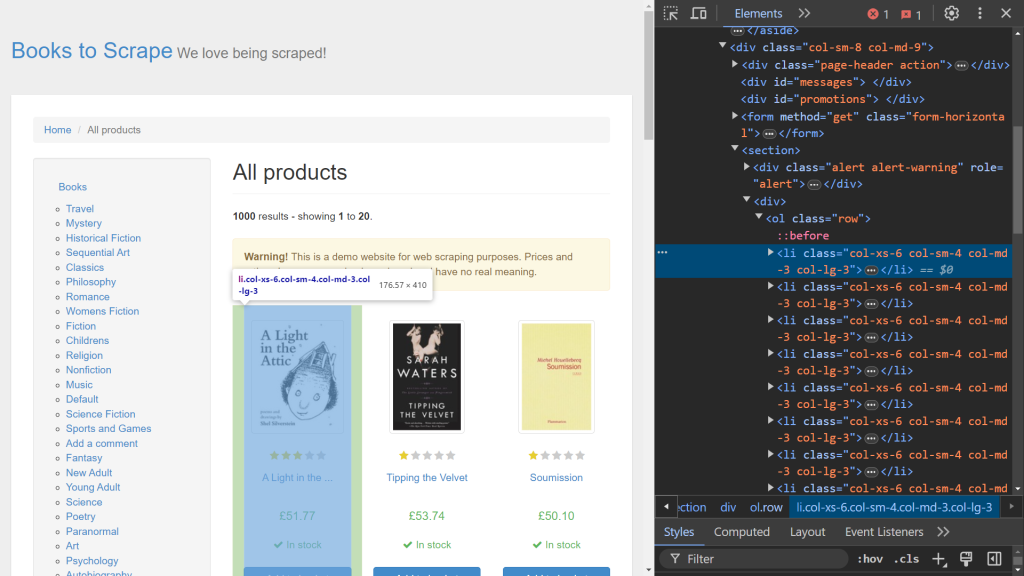
Le côté droit de l’écran affiche le code responsable du rendu de la page. Pour localiser l’élément HTML spécifique qui gère les données de chaque livre, recherchez dans le code à l’aide de l’option survoler-sélectionner (flèche en haut à gauche de l’écran):
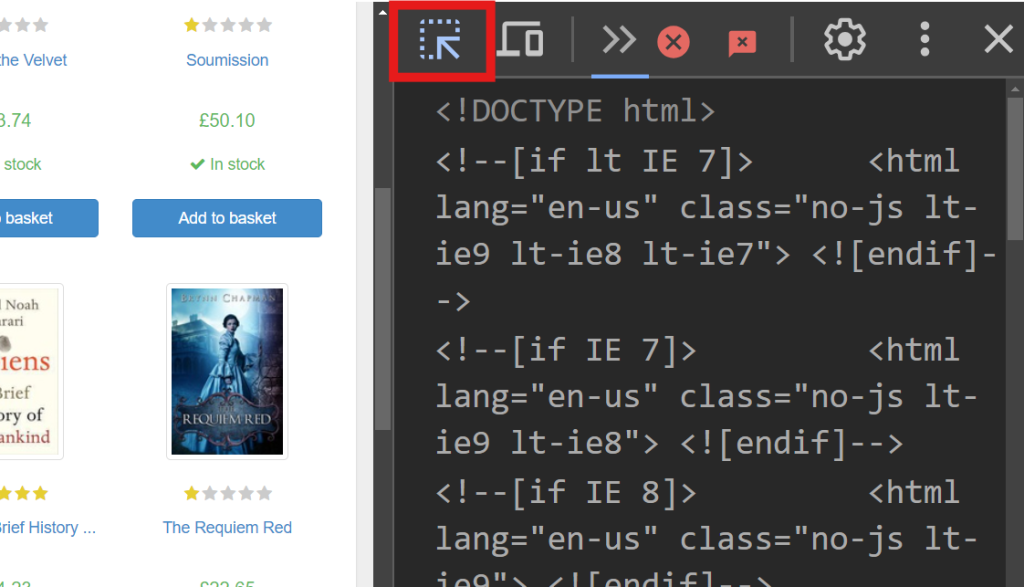
Dans Dev Tools, vous devriez voir l’extrait de code suivant:
<article class="product_pod">
<!-- code omitted -->
<h3><a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a></h3>
<div class="product_price">
<p class="price_color">£51.77</p>
<!-- code omitted -->
</div>
</article>
Dans cet extrait, chaque livre est contenu dans une étiquette
étiquetée avec la classe product_pod. Vous ciblez cet élément pour extraire les données. Créez un nouveau fichier nommé static_scrape.py et ajoutez le code suivant :
import requests
from lxml import html
import json
URL = "https://books.toscrape.com/"
content = requests.get(URL).text
Ce code importe les bibliothèques nécessaires et définit une variable URL . Il utilise requests.get () pour récupérer le contenu HTML statique de la page Web en envoyant une requête GET à l’URL spécifiée. Le code HTML est ensuite récupéré à l’aide de l’attribut text de la réponse.
Une fois le contenu HTML obtenu, l’étape suivante consiste à l’analyser à l’aide de lxml et à extraire les données nécessaires. lxml propose deux méthodes d’extraction: les sélecteurs XPath et CSS. Dans cet exemple, vous utilisez XPath pour récupérer le titre du livre et des sélecteurs CSS pour récupérer le prix du livre.
Ajoutez le code suivant à votre script:
parsed = html.fromstring(content)
all_books = parsed.xpath('//article[@class="product_pod"]')
books = []
Ce code initialise la variable analysée à l’aide de html.fromstring (content), qui analyse le contenu HTML dans une arborescence hiérarchique. La variable all_books utilise un sélecteur XPath pour récupérer toutes les balises <article> ayant la classe product_pod sur la page web. Cette syntaxe est spécifiquement valide pour les expressions XPath.
Ajoutez ensuite ce qui suit à votre script pour parcourir chaque livre de all_books et en extraire les données :
for book in all_books:
book_title = book.xpath('.//h3/a/@title')
price = book.cssselect("p.price_color")[0].text_content()
books.append({"title": book_title, "price": price})
La variable book_title est définie à l’aide d’un sélecteur XPath qui extrait l’attribut title d’une balise <a> au sein d’une balise <h3>. Le point (.) au début de l’expression XPath indique de lancer la recherche à partir de la balise <article> plutôt que depuis le point de départ par défaut. La ligne suivante utilise la méthode cssselect pour extraire le prix d’une balise <p> avec la classe price_color. Puisque cssselect renvoie une liste, l’indexation ([0]) accède au premier élément et text_content () récupère le texte contenu dans l’élément. Chaque paire de titres et de prix extraite est ensuite ajoutée à la liste books sous forme de dictionnaire, qui peut être facilement stocké dans un fichier JSON.
Maintenant que vous avez terminé le processus de web scraping, il est temps de sauvegarder ces données localement. Ouvrez votre fichier de script et saisissez le code suivant:
with open("books.json", "w", encoding="utf-8") as file:
json.dump(books ,file)
Dans ce code, un nouveau fichier nommé books.json est créé. Ce fichier est renseigné à l’aide de la méthode json.dump , qui prend la liste books comme source et un objet file comme destination.
Vous pouvez tester ce script en ouvrant le terminal et en exécutant la commande suivante:
python static_scrape.py
Cette commande génère un nouveau fichier dans votre répertoire avec le résultat suivant:
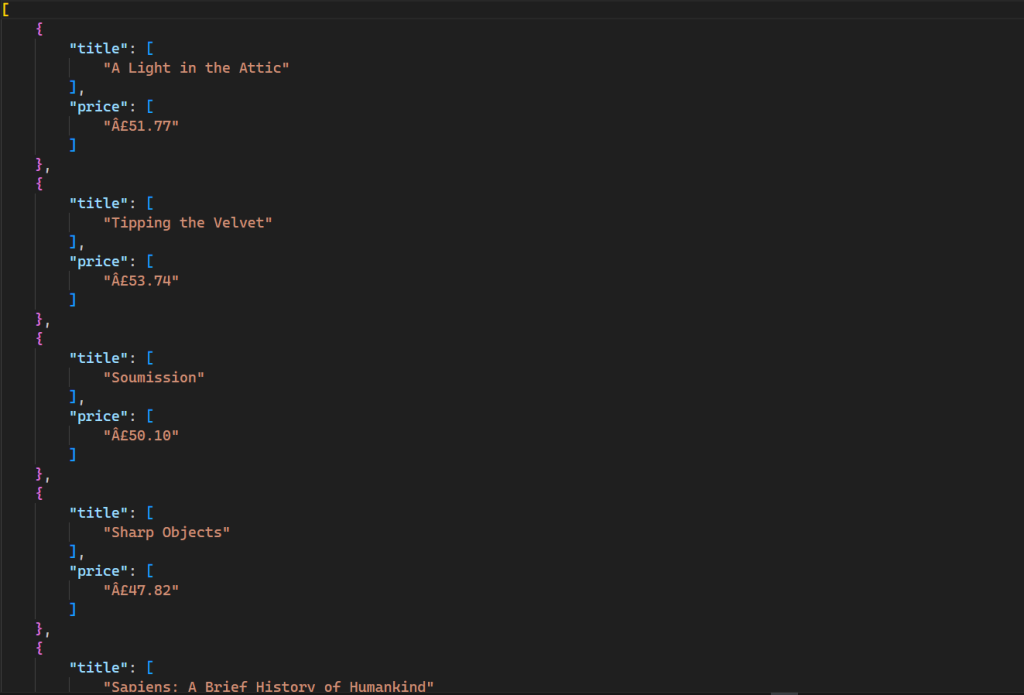
Tout le code source de ce tutoriel est disponible sur GitHub.
Analyse du contenu HTML dynamique
Il est plus difficile de récupérer du contenu Web dynamique que du contenu statique, car JavaScript affiche les données en continu plutôt qu’en une seule fois. Pour vous aider à extraire le contenu dynamique, vous utilisez un outil d’automatisation du navigateur appelé Selenium, qui vous permet de créer et d’exécuter une instance de navigateur et de la contrôler par programmation.
Pour installer Selenium, ouvrez le terminal et exécutez la commande suivante:
pip install selenium
YouTube est un excellent exemple de contenu rendu à l’aide de JavaScript. Lorsque vous visitez une chaîne, seul un nombre limité de vidéos est initialement chargé. D’autres vidéos sont chargées au fur et à mesure que vous faites défiler la page vers le bas. Ici, vous pouvez extraire les données des cent meilleures vidéos de la chaîne YouTube FreeCodeCamp.org en émulant des appuis sur le clavier pour faire défiler la page.
Pour commencer, examinez le code HTML de la page Web. Lorsque vous ouvrez Dev Tools, les informations suivantes s’affichent:
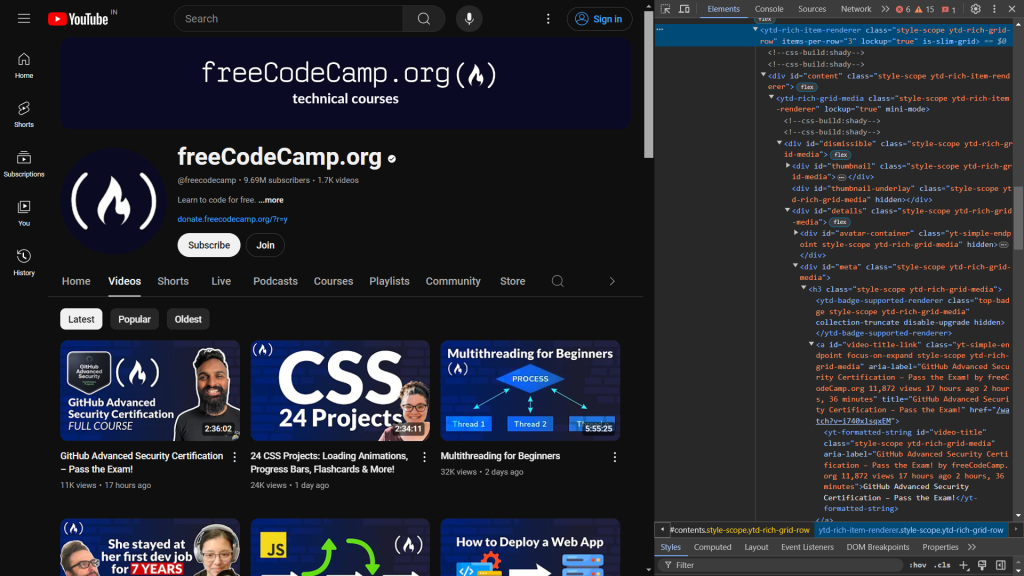
Le code suivant identifie les éléments responsables de l’affichage du titre et du lien de la vidéo:
<a id="video-title-link" class="yt-simple-endpoint focus-on-expand style-scope ytd-rich-grid-media" href="/watch?v=i740xlsqxEM">
<yt-formatted-string id="video-title" class="style-scope ytd-rich-grid-media">GitHub Advanced Security Certification – Pass the Exam!
</yt-formatted-string></a>
Le titre de la vidéo se trouve dans la balise yt-formatted-string avec l’ID video-title, et le lien vidéo se trouve dans l’attribut href de la balise a avec l’ID video-title-link.
Une fois que vous avez identifié ce que vous souhaitez extraire, créez un nouveau fichier nommé dynamic_scrape.py et ajoutez le code suivant, qui importe tous les modules requis pour le script:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from lxml import html
from time import sleep
import json
Ici, vous commencez par importer webdriver depuis selenium, ce qui crée une instance de navigateur que vous pouvez contrôler par programmation. Les lignes suivantes importent By et Keys, qui sélectionnent un élément sur le web et effectuent quelques pressions sur le clavier. La fonction sleep est importée pour suspendre l’exécution du programme et attendre que le code JavaScript affiche le contenu de la page.
Une fois toutes les importations triées, vous pouvez définir l’instance de pilote pour le navigateur de votre choix. Ce didacticiel utilise Chrome, mais Selenium prend également en charge Edge, Firefoxet Safari.
Pour définir l’instance de pilote pour le navigateur, ajoutez le script avec le code suivant:
URL = "https://www.youtube.com/@freecodecamp/videos"
videos = []
driver = webdriver.Chrome()
driver.get(URL)
sleep(3)
Comme dans le script précédent, vous déclarez une variable URL contenant l’URL Web que vous souhaitez extraire et une variable videos qui stocke toutes les données sous forme de liste. Ensuite, une variable driver est déclarée (c’est-à-dire une instance Chrome ) que vous utilisez lorsque vous interagissez avec le navigateur. La fonction get () ouvre l’instance du navigateur et envoie une demande à l’adresse URLspécifiée. Ensuite, vous appelez la fonction sleep pour attendre trois secondes avant d’accéder à un élément de la page Web afin de vous assurer que tout le code HTML est chargé dans le navigateur.
Comme indiqué précédemment, YouTube utilise JavaScript pour charger d’autres vidéos lorsque vous faites défiler la page vers le bas. Pour extraire les données d’une centaine de vidéos, vous devez faire défiler la page vers le bas par programmation après avoir ouvert le navigateur. Vous pouvez le faire en ajoutant le code suivant à votre script:
parent = driver.find_element(By.TAG_NAME, 'html')
for i in range(4):
parent.send_keys(Keys.END)
sleep(3)
Dans ce code, la balise <html> est sélectionnée à l’aide de la fonction find_element . Elle renvoie le premier élément correspondant aux critères donnés, qui dans ce cas est la balise html . La méthode send_keys simule l’appui sur la touche END pour faire défiler la page vers le bas, ce qui déclenche le chargement d’autres vidéos. Cette action est répétée quatre fois dans une boucle pour pour s’assurer que suffisamment de vidéos sont chargées. La fonction sleep s’arrête pendant trois secondes après chaque défilement pour permettre aux vidéos de se charger avant de les faire défiler à nouveau.
Maintenant que vous disposez de toutes les données nécessaires pour démarrer le processus de scraping, il est temps d’utiliser lxml avec cssselect pour sélectionner les éléments que vous souhaitez extraire:
html_data = html.fromstring(driver.page_source)
videos_html = html_data.cssselect("a#video-title-link")
for video in videos_html:
title = video.text_content()
link = "https://www.youtube.com" + video.get("href")
videos.append( {"title": title, "link": link} )
Dans ce code, vous transmettez le contenu HTML de l’attribut page_source du pilote à la méthode fromstring , qui crée une arborescence hiérarchique du code HTML. Ensuite, vous sélectionnez toutes les balises <a> comportant l’ID video-title-link à l’aide de sélecteurs CSS. Le signe # indique la sélection à l’aide de l’ID de la balise. Cette sélection renvoie une liste d’éléments qui répondent aux critères donnés. Le code répète ensuite sur chaque élément pour extraire le titre et le lien. La méthode text_content extrait le texte intérieur (le titre de la vidéo), tandis que la méthode get récupère la valeur de l’attribut href (le lien vidéo). Enfin, les données sont stockées dans une liste appelée vidéos.
À ce stade, vous avez terminé le processus de grattage. L’étape suivante consiste à stocker ces données extraites localement dans votre système. Pour stocker les données, ajoutez le code suivant dans le script:
with open('videos.json', 'w') as file:
json.dump(videos, file)
driver.close()
Ici, vous créez un fichier videos.json et vous utilisez la méthode json.dump pour sérialiser la liste des vidéos au format JSON et l’écrire dans l’objet du fichier. Enfin, vous appelez la méthode close sur l’objet pilote pour fermer et détruire l’instance du navigateur en toute sécurité.
Vous pouvez maintenant tester votre script en ouvrant le terminal et en exécutant la commande suivante:
python dynamic_scrape.py
Après avoir exécuté le script, un nouveau fichier nommé videos.json est créé dans votre répertoire:
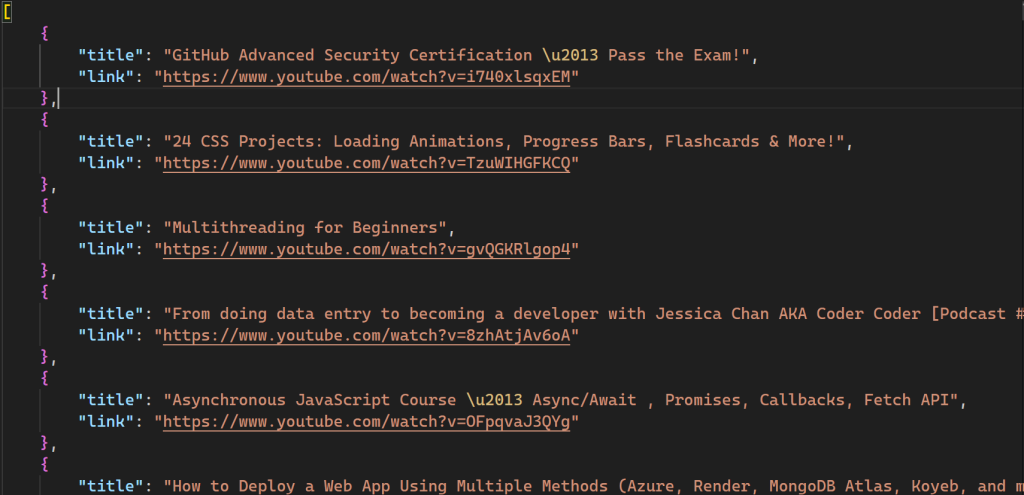
Tout le code source de ce tutoriel est disponible sur GitHub.
Utilisation de lxml avec les proxies de Bright Data
Bien que le web scraping soit une excellente technique pour automatiser la collecte de données provenant de différentes sources, le processus n’est pas sans difficultés. Vous devez faire face aux outils anti-grattage mis en place par les sites Web, à la limitation des taux, au géoblocage et à l’absence d’anonymat. Les serveurs proxy peuvent résoudre ces problèmes en agissant comme des intermédiaires qui masquent l’adresse IP de l’utilisateur, permettant ainsi aux scrapers de contourner les restrictions et d’accéder à des données ciblées sans être détectés. Bright Data est le meilleur choix pour services proxy fiables.
L’exemple suivant montre à quel point il est facile de travailler avec les proxys Bright Data. Cela implique d’apporter quelques modifications au fichier script_scrape.py pour scraper le site Web Books to Scrape.
Pour commencer, vous devez obtenir des proxys auprès de Bright Data en vous inscrivant à un essai gratuit, qui fournit des ressources proxy d’une valeur de 5 dollars américains. Après avoir créé un compte Bright Data, le tableau de bord suivant s’affiche:
Accédez à l’option Mes zones et créez une nouvelle zone proxy résidentiel . La création d’une nouvelle zone révèle votre nom d’utilisateur, votre mot de passe et votre hôte du proxy, dont vous aurez besoin à l’étape suivante.
Ouvrez le fichier static_scrape.py et ajoutez le code suivant sous la variable URL:
URL = "https://books.toscrape.com/"
# new
username = ""
password = ""
hostname = ""
proxies = {
"http": f"https://{username}:{password}@{hostname}",
"https": f"https://{username}:{password}@{hostname}",
}
content = requests.get(URL, proxies=proxies).text
Remplacez les espaces réservés username, password et hostname par les informations d’identification de votre proxy. Ce code indique à la bibliothèque requests d’utiliser le proxy spécifié. Le reste de votre script reste inchangé.
Testez votre script en exécutant la commande suivante:
python static_scrape.py
Après avoir exécuté ce script, vous verrez un résultat similaire à celui que vous avez reçu dans l’exemple précédent.
Vous pouvez consulter l’intégralité de ce script sur GitHub.
Conclusion
lxml est un outil robuste et facile à utiliser pour extraire des données à partir de documents HTML. lxml est optimisé pour la vitesse et prend en charge les sélecteurs XPath et CSS, ce qui permet une analyse efficace des documents XML et HTML volumineux.
Dans ce didacticiel, vous avez tout appris sur le web scraping avec lxml et sur le scraping de contenu dynamique et statique. Vous avez également appris comment l’utilisation des serveurs proxy de Bright Data peut vous aider à contourner les restrictions imposées par les sites Web aux scrapers.
Bright Data est votre plateforme unique pour toutes les solutions de web scraping. Bright Data propose des fonctionnalités telles que les proxies, les navigateurs de scraping et les reCAPTCHA qui permettent aux utilisateurs de résoudre efficacement leurs problèmes de web scraping. Bright Data propose également un blog détaillé contenant des didacticiels et des bonnes pratiques liés au web scraping.
Vous souhaitez commencer? Inscrivez-vous dès maintenant et testez nos produits gratuitement!





