

Dans cet article, vous apprendrez comment recueillir manuellement des données financières et comment utiliser l’API Bright Data Financial Data Scraper pour automatiser le processus.
Définissez ce que vous voulez récupérer comme données et comment elles sont organisées
Les données financières englobent un large éventail d’informations, souvent complexes. Avant de commencer le scraping, vous devez identifier clairement le type de données dont vous avez besoin.
Par exemple, vous voudrez peut-être scraper le cours en direct d’une action, ainsi que son prix à l’ouverture et à la fermeture, le plus haut et le plus bas atteints au cours de la journée et toutes les variations de prix qui se sont produites au fil du temps. Les données financières telles que les comptes de résultat, les bilans (qui décrivent l’actif et le passif) et les états des flux de trésorerie (qui suivent les entrées et les sorties d’argent) sont également nécessaires pour évaluer les performances d’une entreprise. Les ratios financiers, les évaluations des analystes et les rapports peuvent guider les décisions d’achat et de vente, tandis que les nouvelles mises à jour et l’analyse du sentiment des médias sociaux permettent de mieux comprendre les tendances du marché.
Comprendre comment les données d’une page web sont organisées peut faciliter la recherche et la récupération de ce dont vous avez besoin.
Analyser les considérations juridiques et éthiques
Avant de commencer à scraper un site web, vérifiez bien les conditions d’utilisation du site en question. De nombreux sites web interdisent le scraping sans consentement ou autorisation préalable.
Vous devez également respecter les règles du fichier robots.txt , qui indique les parties du site auxquelles vous pouvez accéder. En outre, veillez à ne pas surcharger le serveur de requêtes et à espacer vos demandes. Cela permet de protéger les ressources du site web et d’éviter tout problème.
Utiliser les outils de développement du navigateur
Pour visualiser les éléments HTML d’une page web, vous pouvez utiliser les outils de développement de votre navigateur. Ces outils sont intégrés dans la plupart des navigateurs modernes, notamment Chrome, Safari et Edge. Pour ouvrir les outils de développement, appuyez sur Ctrl + Shift + I sous Windows, Cmd + Option + I sur Mac, ou cliquez avec le bouton droit de la souris sur la page et sélectionnez Inspecter.
Une fois ouvert, vous pouvez inspecter la structure HTML de la page et identifier des éléments de données spécifiques. L’onglet Éléments affiche l’arborescence du modèle objet du document (DOM), ce qui vous permet de localiser et de mettre en évidence les différents éléments de la page. L’onglet Réseau affiche toutes les requêtes réseau, ce qui est utile pour trouver des points de terminaison d’API ou des données chargées dynamiquement. L’onglet Console vous permet d’exécuter des commandes JavaScript et d’interagir avec les scripts de la page.
Dans ce tutoriel, vous allez gratter le stock de APPL de Yahoo Finance. Pour trouver les balises HTML pertinentes, naviguez jusqu’à la page de l’action APPL, cliquez avec le bouton droit de la souris sur un prix affiché sur la page, puis cliquez sur Inspecter. L’onglet Éléments met en évidence l’élément HTML contenant le prix :

Notez le nom de la balise et tout attribut unique, comme class ou idpour vous aider à localiser cet élément dans votre scraper.
Comment configurer l’environnement et le projet
Ce tutoriel utilise [Python]((https://www.python.or) pour le web scraping en raison de sa simplicité et des bibliothèques disponibles. Avant de commencer, vérifiez que Python 3.10 ou une version plus récente est installé sur votre système.
Une fois que vous avez Python, ouvrez votre terminal ou votre shell, et exécutez les commandes suivantes pour créer un répertoire et un environnement virtuel :
mkdir scrape-financial-data
cd scrape-financial-data
python3 -m venv myenv
Après la création de votre environnement virtuel, vous devez encore l’activer. Les commandes d’activation diffèrent selon votre système d’exploitation.
Si vous utilisez Windows, exécutez la commande suivante :
.myenvScriptsactivate
Si vous êtes sous macOS/Linux, exécutez cette commande :
source myenv/bin/activate
Une fois l’environnement virtuel activé, installez les bibliothèques nécessaires avec pip:
pip3 install requests beautifulsoup4 lxml
Cette commande installe la bibliothèque Requests pour gérer les requêtes HTTP, Beautiful Souppour analyser le contenu HTML et lxml pour analyser efficacement le XML et le HTML.
Comment récupérer manuellement des données financières
Pour extraire manuellement des données financières, créez un fichier nommé manual_scraping.py et ajoutez le code suivant pour importer les bibliothèques nécessaires :
import requests
from bs4 import BeautifulSoup
Renseignez l’URL des données financières que vous souhaitez scraper. Comme indiqué précédemment, ce tutoriel utilise la page Yahoo Finance pour l’action Apple (AAPL) :
url = 'https://finance.yahoo.com/quote/AAPL?p=AAPL&.tsrc=fin-srch'
Après avoir défini l’URL, envoyez une requête GET à l’URL :
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
Ce code comprend un en-tête User-Agent pour imiter une requête de navigateur, ce qui permet d’éviter d’être bloqué par le site web ciblé.
Vérifiez que la requête aboutit :
if response.status_code == 200:
print('Successfully retrieved the webpage')
else:
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')
exit()
Ensuite, analyser le contenu de la page web à l’aide de l’analyseur lxml :
soup = BeautifulSoup(response.content, 'lxml')
Trouver les éléments sur la base de leurs attributs uniques, extraire le contenu du texte et imprimer les données extraites :
# Extract specific company details
try:
# Extract specific company details
previous_close = soup.find('fin-streamer', {'data-field': 'regularMarketPreviousClose'}).text.strip()
open_price = soup.find('fin-streamer', {'data-field': 'regularMarketOpen'}).text.strip()
day_range = soup.find('fin-streamer', {'data-field': 'regularMarketDayRange'}).text.strip()
week_52_range = soup.find('fin-streamer', {'data-field': 'fiftyTwoWeekRange'}).text.strip()
market_cap = soup.find('fin-streamer', {'data-field': 'marketCap'}).text.strip()
# Extract PE Ratio (TTM)
pe_label = soup.find('span', class_='label', title='PE Ratio (TTM)')
pe_value = pe_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Extract EPS (TTM)
eps_label = soup.find('span', class_='label', title='EPS (TTM)')
eps_value = eps_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Print the scraped details
print("n### Stock Price ###")
print(f"Open Price: {open_price}")
print(f"Previous Close: {previous_close}")
print(f"Day's Range: {day_range}")
print(f"52 Week Range: {week_52_range}")
print("n### Company Details ###")
print(f"Market Cap: {market_cap}")
print(f"PE Ratio (TTM): {pe_value}")
print(f"EPS (TTM): {eps_value}")
except AttributeError as e:
print("Error while scraping data. Some fields may not be found.")
print(e)
Exécuter et tester le code
Pour tester le code, ouvrez votre terminal ou votre shell et exécutez la commande suivante :
python3 manual_scraping.py
Vous devriez obtenir le résultat suivant :
Successfully retrieved the webpage
### Stock Price ###
Open Price: 225.20
Previous Close: 225.00
Day's Range: 225.18 - 229.74
52 Week Range: 164.08 - 237.49
### Company Details ###
Market Cap: 3.447T
PE Ratio (TTM): 37.50
EPS (TTM): 37.50
Relever les défis du scraping manuel
L’extraction manuelle de données peut s’avérer difficile pour diverses raisons, notamment en raison des CAPTCHA ou des blocages d’adresse IP, qui nécessitent l’utilisation de stratégies de contournement. Les données non structurées ou désordonnées peuvent provoquer des erreurs d’analyse, tandis que l’extraction de données sans les autorisations peut vous confronter à des problèmes juridiques. Les mises à jour fréquentes du site web peuvent également endommager votre scraper, ce qui nécessite une maintenance régulière du code pour garantir la continuité du fonctionnement.
Pour construire et automatiser votre scraper, vous devez passer beaucoup de temps à écrire le code et à le corriger plutôt que de vous concentrer sur l’analyse des données. Si vous traitez de grandes quantités de données, cela peut être encore plus difficile car vous devez vous assurer que les données sont propres et organisées. Si vous gérez différentes structures de sites web, vous devez également comprendre les différentes technologies web.
En d’autres termes, si vous avez besoin de récupérer des données fréquemment et rapidement, le web scraping manuel n’est pas la meilleure solution.
Comment extraire des données avec l’API Bright Data Financial Data Scraper
Bright Data relève les défis du scraping manuel avec son API Financial Data Scraper, qui automatise l’extraction des données. Il est doté d’une gestion de proxy intégrée avec des proxys rotatifs pour éviter les blocages d’IP. L’API renvoie des données structurées dans des formats tels que JSON et CSV. Il est également très évolutif, ce qui permet de traiter facilement de grands volumes de données.
Pour utiliser l’API Financial Data Scraper API, créez un compte gratuit sur le site Web de Bright Data. Vérifiez votre adresse électronique et complétez toutes les étapes de vérification d’identité requises.
Une fois votre compte créé, connectez-vous pour accéder au tableau de bord et obtenir vos clés API.
Configurer l’API Financial Data Scraper
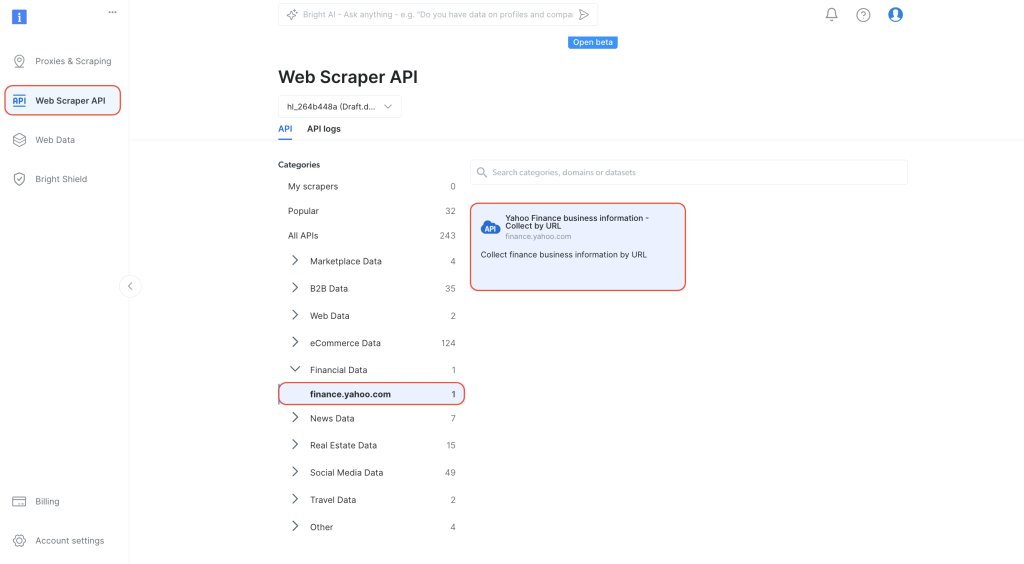
Dans le tableau de bord, naviguez vers l’API Web Scraper API dans l’onglet de navigation de gauche. Sélectionnez
Données financières dans Catégories, puis cliquez sur « API Yahoo Finance Business Information – collecter par URL » :
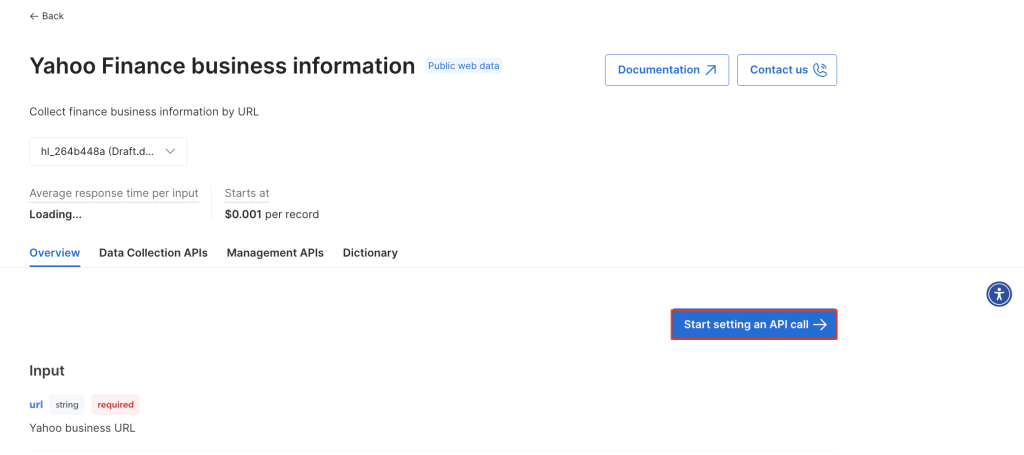
Cliquez sur Lancer un appel API:
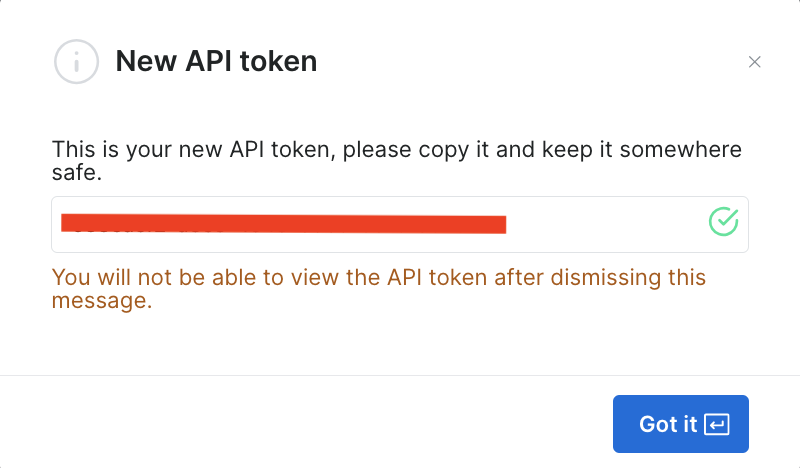
Pour utiliser l’API, vous devez créer un jeton qui authentifie vos appels d’API à Bright Data Scraper. Pour créer un nouveau jeton, cliquez sur Créer un jeton:

Une boîte de dialogue s’ouvre. Définissez les Autorisations sur « Admin » et la durée sur « Illimitée » :

Après avoir enregistré ces informations, le jeton est créé et vous serez invité à saisir le nouveau jeton. Veillez à l’enregistrer dans un endroit sûr, car vous en aurez bientôt besoin :
Si vous avez déjà créé le jeton, vous pouvez l’obtenir dans les paramètres de l’utilisateur, sous Jetons d’API. Sélectionnez l’onglet Plus de votre utilisateur, puis cliquez sur Copier le jeton.
Utiliser le scraper pour récupérer des données financières
Sur la page Yahoo Finance Business Information , ajoutez votre jeton API dans le champ API token , puis ajoutez l’URL du site web ciblé, qui est https://finance.yahoo.com/quote/AAPL/. Copiez la demande dans la section AUTHENTICATED REQUEST à droite :
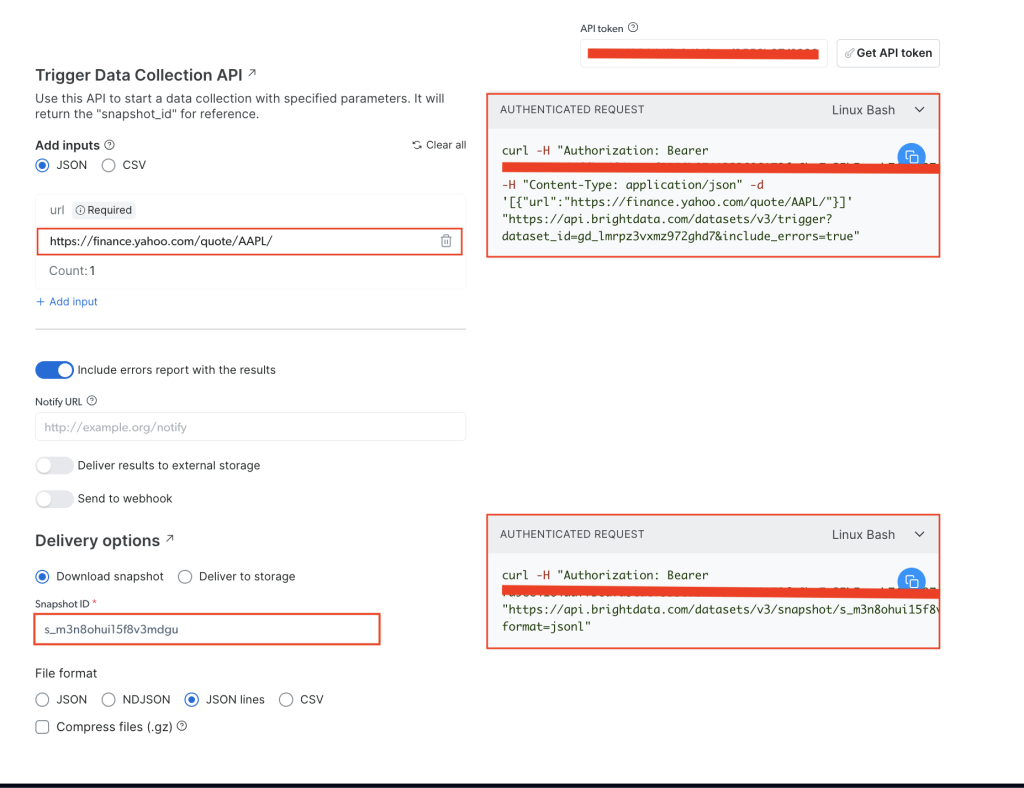
Ouvrez votre terminal ou votre shell et exécutez l’appel API en utilisant curl. Il devrait ressembler à ceci :
curl -H "Authorization: Bearer YOUR_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://finance.yahoo.com/quote/AAPL/"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=YOUR_DATA_SET_ID&include_errors=true"
Après avoir exécuté la commande, vous obtenez comme réponse le snapshot_id :
{"snapshot_id":"s_m3n8ohui15f8v3mdgu"}
Copiez le snapshot_id et exécutez l’appel API suivant à partir de votre terminal ou shell :
curl -H "Authorization: Bearer YOUR_TOKEN" "https://api.brightdata.com/datasets/v3/snapshot/YOUR_SNAP_SHOT_ID?format=jsonl"
Veillez à remplacer
YOUR_TOKENetYOUR_SNAP_SHOT_IDpar vos informations d’identification.
Après avoir exécuté ce code, vous devriez obtenir les données scrapées en sortie. Les données doivent ressembler à ce qui suit Fichier JSON.
Si vous obtenez une réponse indiquant que l’instantané n’est pas prêt, attendez dix secondes, puis réessayez.
L’API Bright Data Financial Data Scraper a extrait toutes les données dont vous aviez besoin sans vous obliger à analyser la structure HTML ou à localiser des balises spécifiques. L’ensemble des données de la page ont été récupérées, y compris des champs supplémentaires tels que earning_estimate, earnings_history et growth_estinates.
Tout le code de ce tutoriel est disponible dans ce dépôt GitHub.
Avantages de l’utilisation de l’API Bright Data
L’API Financial Data Scraper de Bright Data simplifie le processus de scraping en éliminant la nécessité d’écrire ou de gérer le code de scraping. L’API contribue également à garantir la conformité en gérant la rotation du proxy et en respectant les conditions de service des sites web, ce qui vous permet de collecter des données sans craindre d’être bloqué ou d’enfreindre les règles.
L’API Bright Data Financial Data Scraper fournit des données structurées et fiables avec très peu de codage. L’API gère la navigation sur les pages et l’analyse HTML à votre place afin de simplifier le processus. L’évolutivité de l’API vous permet de collecter des données sur de nombreuses actions et d’autres indicateurs financiers sans apporter de modifications importantes à votre code. La maintenance est également minimale car Bright Data met à jour le scraper lorsque les sites Web modifient leur structure, de sorte que votre collecte de données se poursuit sans problème et sans travail supplémentaire.
Conclusion
La collecte de données financières est une tâche essentielle pour les développeurs et les équipes chargées des données dans les domaines de l’analyse financière, du trading algorithmique et des études de marché. Dans cet article, vous avez appris à scraper manuellement des données financières à l’aide de Python et de l’API Bright Data Financial Data Scraper. Bien que le scraping manuel de données offre un certain contrôle, il peut être difficile de gérer les mesures anti-scraping et les frais généraux de maintenance, et il est difficile d’optimiser votre modèle pour vos exigences spécifiques.
L’API Bright Data Financial Data Scraper rationalise la collecte de données en gérant des tâches complexes, telles que la rotation de proxy et la résolution de CAPTCHA. Outre l’API, Bright Data propose également des ensembles de données, des proxies résidentiels et un navigateur spécialisé dans le scraping pour vous aider à améliorer vos projets de scraping sur le web. Inscrivez-vous à un essai gratuit pour découvrir tout ce que Bright Data a à offrir.






