

En termes simples, les données erronées désignent les données incomplètes, inexactes, incohérentes, non pertinentes ou dupliquées qui s’introduisent dans votre infrastructure de données pour diverses raisons.
À la fin de cet article, vous comprendrez :
- Ce que sont les mauvaises données
- Les différents types de données erronées
- Quelles sont les causes des données erronées
- Leurs conséquences et les mesures préventives
Examinons cela plus en détail :
Différents types de données erronées
La qualité et la fiabilité des données sont essentielles dans presque tous les domaines, de l’analyse commerciale à la formation des modèles d’IA. Les données de mauvaise qualité se manifestent sous plusieurs formes différentes, chacune posant des défis uniques en matière d’utilisabilité et d’intégrité des données.
Données incomplètes
Les données incomplètes désignent un jeu de données auquel il manque un ou plusieurs attributs, champs ou entrées nécessaires à une analyse précise. Ces informations manquantes rendent le jeu de données peu fiable, voire inutilisable.
Les causes courantes des données incomplètes comprennent l’omission intentionnelle de données spécifiques, les transactions non enregistrées, la collecte partielle de données, les erreurs lors de la saisie des données, les problèmes techniques invisibles lors du transfert des données, etc.
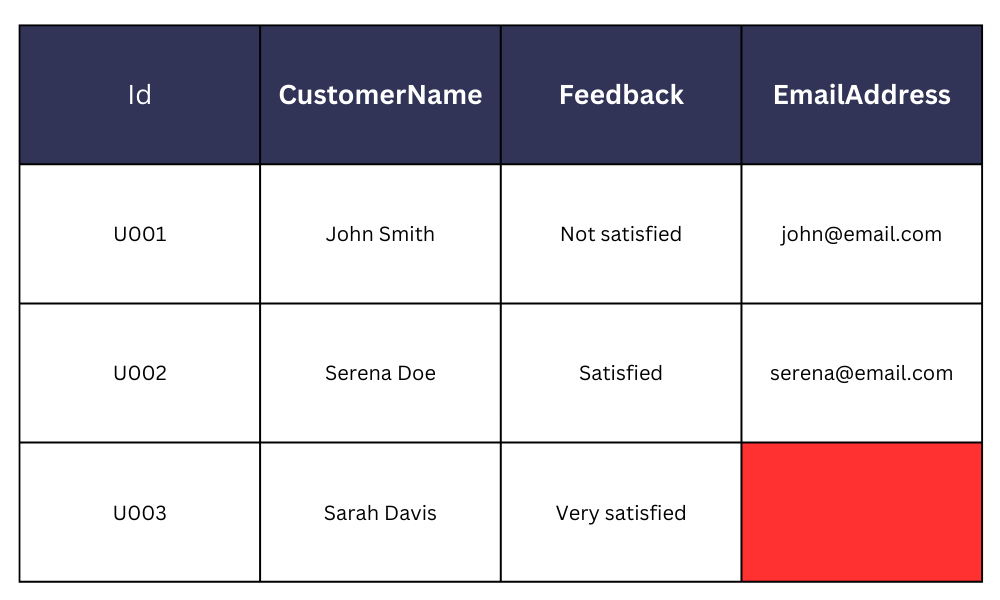
Prenons par exemple le cas d’une enquête auprès des clients dans laquelle les coordonnées des répondants ne sont pas enregistrées. Il est alors impossible de recontacter les répondants par la suite, comme le montre l’exemple ci-dessous.
Un autre exemple peut être une base de données hospitalière contenant des dossiers médicaux de patients dans lesquels des informations cruciales telles que les allergies et les antécédents médicaux sont manquantes, ce qui peut même conduire à des situations mettant la vie en danger.
Données en double
Les données en double apparaissent lorsque la même entrée de données ou des entrées de données presque identiques sont enregistrées plusieurs fois dans la base de données. Cette redondance conduit à des analyses trompeuses et à des conclusions erronées, et complique parfois les opérations de fusion et les dysfonctionnements du système. Les statistiques dérivées d’un jeu de données contenant des données en double deviennent peu fiables et inefficaces pour la prise de décision.
Exemples :
- Une base de données de gestion de la relation client (CRM) contenant plusieurs enregistrements pour un même client peut fausser les informations dérivées après analyse, telles que le nombre de clients distincts ou les ventes par client.
- Un système de gestion des stocks qui stocke le même produit sous différents numéros SKU rend les estimations des stocks inexactes.
Données inexactes
La présence d’informations incorrectes ou erronées dans une ou plusieurs entrées d’un jeu de données est considérée comme une donnée inexacte.
Une simple erreur dans un code ou un chiffre due à une faute de frappe ou à une omission involontaire peut être suffisamment grave pour entraîner de sérieuses complications et pertes, en particulier lorsque les données sont utilisées pour prendre des décisions dans un domaine à haut risque. L’existence de données inexactes diminue en soi la fiabilité et la crédibilité de l’ensemble du jeu de données.
Exemples :
- Une base de données d’une entreprise de transport contenant des adresses de livraison incorrectes peut entraîner l’envoi de colis à des adresses erronées, voire dans des pays erronés, causant d’énormes pertes et des retards tant pour l’entreprise que pour le client.
- Les situations dans lesquelles un système de gestion des ressources humaines (HRMS) contient des informations incorrectes sur les salaires des employés peuvent entraîner des écarts dans les paies et des problèmes juridiques potentiels.
Données incohérentes
Les données incohérentes, qui apparaissent lorsque différentes personnes ou équipes utilisent des unités ou des formats différents pour le même type de données au sein d’une organisation, sont une cause fréquente de confusion et d’inefficacité que vous pouvez rencontrer lorsque vous travaillez avec des données. Elles perturbent l’uniformité et la continuité entre les données, ce qui entraîne un traitement erroné des données.
Exemples :
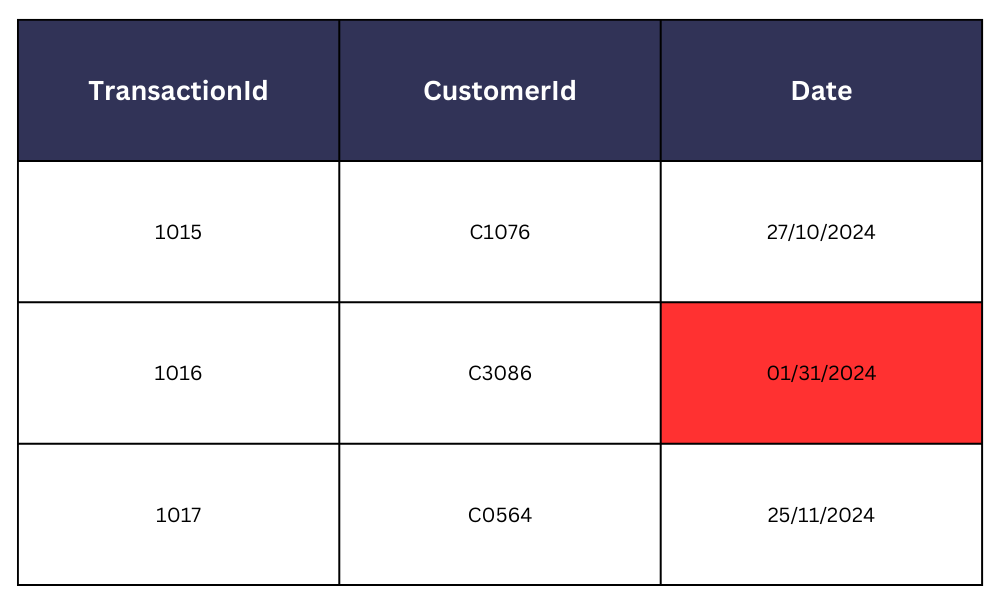
- Des formats de date incohérents entre plusieurs entrées de données (MM/JJ/AAAA vs JJ/MM/AAAA), par exemple dans un système bancaire, peuvent entraîner des conflits et des problèmes lors de l’agrégation et de l’analyse des données.
- Deux magasins d’une même chaîne de distribution qui saisissent des données sur les stocks dans des unités de mesure différentes (nombre de caisses vs nombre d’articles individuels) peuvent être source de confusion lors du réapprovisionnement et de la distribution.
Données obsolètes
En termes simples, les données obsolètes sont des enregistrements qui ne sont plus à jour, pertinents et applicables. Les données obsolètes sont particulièrement courantes dans les domaines en évolution rapide, où des changements rapides se produisent en permanence. Les données datant d’une décennie, d’un an ou même d’un mois peuvent ne plus être utiles, voire être trompeuses, selon le contexte.
Exemples :
- Une personne peut développer de nouvelles allergies au fil du temps. Un hôpital qui prescrit des médicaments à un patient dont les informations sur les allergies sont obsolètes peut compromettre la sécurité du patient.
- Une agence immobilière qui répertorie des biens à partir d’une source de données obsolète peut perdre du temps et gaspiller ses efforts sur des biens déjà vendus ou qui ne sont plus disponibles. Cela est improductif et peut nuire à la réputation de l’entreprise.
En outre, les données non conformes, non pertinentes, non structurées et biaisées sont également des types de données de mauvaise qualité qui peuvent compromettre la qualité des données dans votre écosystème de données. Il est essentiel de comprendre chacun de ces différents types de données de mauvaise qualité afin d’en identifier les causes profondes et les menaces qu’ils représentent pour votre entreprise, et d’élaborer des stratégies pour en atténuer l’impact.
Quelles sont les causes des données erronées ?
Maintenant que vous comprenez clairement les types de données erronées, il est important de comprendre ce qui les cause, afin que vous puissiez prendre des mesures proactives pour éviter que de telles situations ne se produisent dans vos Jeux de données.
Voici quelques causes possibles des données erronées :
- Erreurs humaines lors de la saisie des données : il va sans dire qu’il s’agit de la cause la plus courante de données erronées, en particulier lorsqu’il s’agit de données incomplètes, inexactes et dupliquées. Une formation insuffisante, un manque d’attention aux détails, des malentendus concernant le processus de saisie des données et, surtout, des erreurs involontaires telles que des fautes de frappe peuvent finalement conduire à des Jeux de données peu fiables et à d’énormes complications lors de l’analyse.
- Mauvaises pratiques et normes de saisie des données : un ensemble de normes solides est essentiel pour mettre en place des pratiques fiables et bien structurées. Par exemple, si vous autorisez la saisie de texte libre pour un champ tel que le pays, un utilisateur peut entrer différents noms pour le même pays (par exemple : USA, États-Unis, États-Unis d’Amérique), ce qui entraîne une grande variété de réponses inefficaces pour la même valeur. Ces incohérences et cette confusion résultent de l’absence de normes correctement définies.

- Problèmes de migration : les donnéeserronées ne sont pas toujours le résultat de saisies manuelles. Elles peuvent également résulter de la migration de données d’une base de données à une autre. Un tel problème entraîne un désalignement des enregistrements et des champs, une perte de données et même une corruption des données qui peut nécessiter de longues heures de vérification et de correction.
- Dégradation des données : chaque petit changement, qu’il s’agisse des préférences des clients ou d’une évolution des tendances du marché, peut entraîner une mise à jour des données de l’entreprise. Si la base de données n’est pas constamment mise à jour pour refléter ces changements, les données deviennent obsolètes, ce qui entraîne leur détérioration ou leur dégradation. Les données obsolètes n’ont aucune utilité réelle dans la prise de décision et l’analyse et contribuent à fournir des informations trompeuses lorsqu’elles sont utilisées.
- Fusion de données provenant de plusieurs sources : une combinaisoninefficace de données provenant de plusieurs sources ou une intégration de données défectueuse peut entraîner des données inexactes et incohérentes. Cela se produit lorsque les différentes sources de données combinées sont formatées selon des normes, des formats et des niveaux de qualité variables.
Impact des données erronées
Si vous traitez des jeux de données contenant des données erronées, vous mettez en péril votre analyse finale. En fait, les données erronées peuvent avoir des conséquences durables et dévastatrices, en particulier sur les entreprises et les domaines axés sur les données, par exemple
- Une mauvaise qualité des données peut nuire à votre entreprise en augmentant le risque de prendre de mauvaises décisions et de faire de mauvais investissements sur la base d’informations trompeuses.
- Les données erronées entraînent des coûts financiers importants, notamment le gaspillage de ressources et la perte de revenus. Se remettre des effets des données erronées peut nécessiter beaucoup de temps et d’argent.
- L’accumulation de données erronées peut même entraîner la faillite d’une entreprise, car elle augmente le besoin de retouches, conduit à des opportunités manquées et a un impact négatif sur la productivité dans son ensemble.
- En conséquence, la fiabilité et la crédibilité de l’entreprise diminuent, ce qui nuit considérablement à la satisfaction et à la fidélisation des clients. Des données inexactes et incomplètes de la part de l’entreprise entraînent un service client médiocre et une communication incohérente.
En outre, les données erronées peuvent entraîner des erreurs critiques qui peuvent dégénérer en complications juridiques ou mettre des vies en danger, en particulier dans les domaines financier et médical.
Par exemple, en 2020, pendant la pandémie de COVID-19, Public Health England (PHE) a connu une erreur importante dans la gestion des données qui a entraîné la non-déclaration de 15 841 cas de COVID-19 en raison de données erronées. Le problème provenait de la version obsolète des feuilles de calcul Excel utilisées par PHE, qui ne pouvaient contenir que 65 000 lignes, au lieu du million de lignes qu’elles pouvaient réellement contenir. Certaines des données fournies par les sociétés tierces analysant les tests par écouvillonnage ont été perdues, ce qui a entraîné des données incomplètes. Le nombre de contacts étroits à risque d’infection manqués en raison de cette erreur technique s’élevait à environ 50 000.
De plus, l’erreur de saisie commise par Samsung en 2018 a entraîné une chute du cours des actions d’environ 11 % en une seule journée, effaçant près de 300 millions de dollars de valeur boursière. Elle a été causée par un employé de Samsung Securities qui a commis une erreur de saisie en entrant 2,8 milliards d’« actions » (d’une valeur de 105 milliards de dollars) au lieu de 2,8 milliards de « wons sud-coréens » à distribuer aux employés qui participaient au plan d’actionnariat de l’entreprise.
Par conséquent, les conséquences d’une mauvaise donnée ne doivent pas être prises à la légère, et des mesures préventives appropriées doivent être prises pour éliminer le risque.
Prévenir les données erronées
Aucun jeu de données n’est parfait. Vos données sont forcément sujettes à des erreurs. La première étape pour prévenir les données erronées consiste à reconnaître cette réalité afin de pouvoir mettre en œuvre les stratégies préventives nécessaires pour garantir la qualité des données.
Voici quelques mesures permettant de prévenir les données erronées :
- La mise en place d’une gouvernance des données robuste est une étape cruciale pour établir la responsabilité et les normes au sein de l’organisation. Elle peut vous aider à mettre en place des politiques et des procédures claires sur la manière de gérer, d’accéder et de maintenir les données afin de minimiser le risque de données erronées.
- Réalisez régulièrement des audits de données afin de détecter les incohérences et les données obsolètes avant que des complications ne surviennent.
- Réglementer les processus de saisie des données en mettant en place des normes, des règles de validation des données, des formats et des modèles standard dans toute l’organisation afin de minimiser les erreurs humaines.
- Les employés bien informés ont tendance à commettre moins d’erreurs lors du traitement et de la gestion des données. Il est donc nécessaire d’organiser régulièrement des sessions de formation et de mise à jour afin que les employés restent informés des processus standard.
- Sauvegardez régulièrement les données afin d’éviter toute perte en cas d’imprévu.
- Utilisez des outils avancés spécialement conçus pour la validation des données afin de garantir la cohérence et l’intégrité de vos données. Ils peuvent confirmer l’exactitude et l’exhaustivité de vos données, en détectant et en corrigeant les erreurs potentielles.
Conclusion
Cet article a exploré ce que sont les données erronées, les différents types de données erronées que vous pouvez rencontrer et leurs causes. En outre, il a mis en évidence l’impact négatif significatif des données erronées sur une organisation axée sur les données, des pertes financières aux échecs commerciaux. Comprendre ces facteurs est la première étape pour prévenir les données erronées.
Même s’il existe plusieurs stratégies préventives pour garantir la qualité des données, l’utilisation d’un outil fiable spécialement conçu à cet effet vous facilitera certainement la tâche.
Envisagez d’utiliser des outils de scraping de données qui vous permettent de créer automatiquement des jeux de données fiables et propres. Cela vous évite d’avoir à fournir des efforts et vous permet d’obtenir des données propres et directement utilisables. L’API Web Scraper de Bright Data est l’un de ces outils. Vous n’êtes pas intéressé par le scraping ? Inscrivez-vous dès maintenant et téléchargez nos échantillons de données gratuits !




