

Dans ce guide étape par étape, vous apprendrez comment faire du web scraping sur Reddit en utilisant Python
Dans ce tutoriel, nous parlerons des points suivants :
- Nouvelle stratégie de Reddit pour ses API
- API Reddit vs web scraping Reddit
- Collecter des données sur Reddit avec Selenium
Nouvelle stratégie de Reddit pour ses API
En avril 2023, Reddit a annoncé de nouveaux tarifs pour ses API de données, prohibitifs pour les petites entreprises. Au moment de la rédaction du présent document, les frais d’API sont fixés à 0,24 $ pour 1 000 appels. Comme vous pouvez l’imaginer, le total peut monter rapidement, même pour une utilisation modeste. Cela est particulièrement vrai compte tenu de la multitude de contenus générés par les utilisateurs sur Reddit, et des énormes quantités d’appels nécessaires pour les récupérer. Apollo, l’une des applications tierces basées sur l’API Reddit les plus utilisées, a été contrainte d’arrêter ses activités à cause de cela.
Cela signifie-t-il la fin de Reddit en tant que source d’analyse de sentiment du public, de commentaires des utilisateurs et de données de tendances ? Certainement pas ! Il existe une solution plus efficace, moins coûteuse et indépendante des décisions d’entreprise pouvant être prises du jour au lendemain. Cette solution est le web scraping. Découvrons pourquoi.
API Reddit vs web scraping Reddit
L’API de Reddit est la méthode officielle permettant d’obtenir des données sur le site. Compte tenu des récents changements de politique et des orientations adoptées par la plateforme, le web scraping sur Reddit est une meilleure solution, et ce pour plusieurs bonnes raisons :
- Rapport coût-efficacité : étant donné les nouveaux tarifs de l’API de Reddit, scraper Reddit peut être une alternative beaucoup plus abordable. La création d’un web scraper Reddit en Python vous permet de collecter des données sans encourir de dépenses supplémentaires associées à l’utilisation de l’API.
- Une collecte de données améliorée : lorsque vous faites du web scraping sur Reddit, vous avez la possibilité de personnaliser le code d’extraction de données pour obtenir uniquement les informations qui correspondent à vos besoins. Cette personnalisation vous aide à surmonter les limitations relatives au format des données, au débit et les restrictions d’utilisation dans l’API.
- Accès à des données non officielles : alors que l’API de Reddit ne donne accès qu’à une sélection d’informations bien déterminées, le web scraping vous donne accès à toutes les données publiques accessibles sur le site.
Maintenant que vous savez pourquoi le web scraping est une option plus efficace que l’appel d’API, voyons comment construire un web scraper Reddit en Python. Avant de passer à la section suivante, envisagez de consulter notre guide détaillé sur le web scraping avec Python.
Collecte de données Reddit avec Selenium
Dans ce tutoriel étape par étape, vous apprendrez à créer en Python un script de web scraping pour Reddit.
Étape 1 : configuration du projet
Assurez-vous d’abord de respecter les prérequis suivants :
- Python 3+ : Téléchargez le programme d’installation, double-cliquez dessus et suivez les instructions d’installation.
- Un IDE Python : PyCharm Community Edition ou Visual Studio Code avec l’extension Python conviendront.
Initialisez un projet Python avec un environnement virtuel en exécutant les commandes ci-dessous :
mkdir reddit-scraper
cd reddit-scraper
python -m venv envLe dossier reddit-scraper créé ici est le dossier du projet de votre script Python.
Ouvrez le répertoire dans l’IDE, créez un fichier scraper.py et initialisez-le comme ceci :
print('Hello, World!')Pour l’instant, ce script se contente d’afficher la sortie « Hello, World! », mais il contiendra bientôt votre logique de web scraping.
Vérifiez que le programme fonctionne en appuyant sur le bouton RUN de votre IDE ou en lançant la commande :
python scraper.pySur le terminal, vous devriez voir :
Hello, World!Parfait ! Vous avez maintenant un projet Python pour votre web scraper Reddit.
Étape 2 : sélectionnez et installez les bibliothèques de web scraping
Comme vous le savez peut-être déjà, Reddit est une plateforme hautement interactive. Le site charge les nouvelles données et assure leur rendu de manière dynamique, selon la façon dont les utilisateurs interagissent avec ses pages par le biais d’actions de clic et de défilement. D’un point de vue technique, cela signifie que Reddit s’appuie fortement sur JavaScript.
Faire du web scraping en Python sur Reddit nécessite donc un outil capable d’assurer le rendu de pages web dans un navigateur. C’est là que Selenium entre en jeu. Cet outil vous permet de faire du web scraping sur des sites dynamiques en Python, et donc d’effectuer des opérations automatisées sur des pages web dans un navigateur.
Vous pouvez ajouter Selenium et Webdriver Manager aux dépendances de votre projet avec :
pip install selenium webdriver-managerLe processus d’installation peut prendre un certain temps ; soyez donc patient.
Le package webdriver-manager n’est pas strictement indispensable mais est fortement recommandé. Il vous permet d’éviter de télécharger, d’installer et de configurer manuellement les pilotes web dans Selenium. La bibliothèque s’occupera de tout à votre place.
Intégrez Selenium dans votre fichier scraper.py :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# enable the headless mode
options = Options()
options.add_argument('--headless=new')
# initialize a web driver to control Chrome
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# maxime the controlled browser window
driver.fullscreen_window()
# scraping logic...
# close the browser and free up the Selenium resources
driver.quit()Ce script instancie un objet Chrome WebDriver pour contrôler par programmation une fenêtre Chrome.
Par défaut, Selenium ouvre le navigateur dans une nouvelle fenêtre d’interface graphique. Cela est utile pour surveiller ce que le script fait sur les pages, ce qui sert notamment pour le débogage. Cela étant, le chargement d’un navigateur avec son interface graphique consomme énormément de ressources. Il est donc recommandé de configurer Chrome pour qu’il fonctionne en mode sans tête. Plus précisément, l’option --headless=New indique à Chrome de démarrer sans interface utilisateur en arrière-plan.
Bravo ! Il est temps de visiter notre page cible sur Reddit.
Étape 3 : connectez-vous à Reddit
Ici, vous allez apprendre à extraire des données du subreddit r/Technology. Cela étant, n’importe quel autre subreddit ferait l’affaire.
Plus précisément, supposons que vous vouliez extraire les données de la page sur laquelle se trouvent les posts les plus lus de la semaine. Voici l’URL de la page cible :
https://www.reddit.com/r/technology/top/?t=weekStockez cette chaîne dans une variable Python :
url = 'https://www.reddit.com/r/technology/top/?t=week'Ensuite, utilisez Selenium pour visiter la page avec :
driver.get(url)La fonction get() demande au navigateur contrôlé de se connecter à la page identifiée par l’URL passée en paramètre.
Voici ce à quoi ressemble votre web scraper Reddit pour l’instant :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# enable the headless mode
options = Options()
options.add_argument('--headless=new')
# initialize a web driver to control Chrome
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# maxime the controlled browser window
driver.fullscreen_window()
# the URL of the target page to scrape
url = 'https://www.reddit.com/r/technology/top/?t=week'
# connect to the target URL in Selenium
driver.get(url)
# scraping logic...
# close the browser and free up the Selenium resources
driver.quit()Testez votre script. Il ouvre la fenêtre du navigateur ci-dessous pendant une fraction de seconde avant de la fermer à cause de l’instruction quit() :

Regardez le message « Chrome is being controlled by automated test software. » Bien ! Cela garantit que Selenium fonctionne correctement sur Chrome.
Étape 4 : inspectez la page cible
Avant de vous lancer dans l’écriture de votre code, vous devez parcourir la page cible pour voir quelles informations y figurent et comment vous pouvez les récupérer. En particulier, vous devez identifier quels éléments HTML contiennent les données qui vous intéressent et concevoir des stratégies de sélection appropriées.
Pour simuler les conditions dans lesquelles Selenium fonctionne – une session de navigateur tout ce qu’il y a de plus ordinaire – ouvrez la page Reddit en mode incognito. Cliquez avec le bouton droit sur n’importe quelle section de la page, puis cliquez sur « Inspect » pour ouvrir Chrome DevTools :

Cet outil vous aide à comprendre la structure DOM de la page. Comme vous pouvez le voir, le site utilise des classes CSS qui semblent être générées aléatoirement au moment du build. En d’autres termes, vous ne devez pas baser vos stratégies de sélection sur elles.

Heureusement, les éléments les plus importants du site ont des attributs HTML bien déterminés. Par exemple, le nœud de description subreddit possède l’attribut suivant :
data-testid="no-edit-description-block"Cette information est utile pour construire une logique de sélection d’éléments HTML efficace.
Continuez à analyser le site Reddit dans les DevTools et familiarisez-vous avec son DOM jusqu’à ce que vous soyez prêt à en extraire les données avec Python.
Étape 5 : extrayez les informations principales du subreddit
Tout d’abord, créez un dictionnaire Python dans lequel stocker les données collectées.
subreddit = {}Ensuite, notez que vous pouvez obtenir le nom du subreddit à partir de l’élément situé en haut de la page:

Récupérez-le comme ceci :
name = driver \
.find_element(By.TAG_NAME, 'h1') \
.textComme vous devez déjà l’avoir remarqué, certaines des informations générales les plus intéressantes sur le subreddit se trouvent dans la barre latérale droite :

Vous pouvez obtenir la description, la date de création et le nombre de membres comme ceci :
description = driver \
.find_element(By.CSS_SELECTOR, '[data-testid="no-edit-description-block"]') \
.get_attribute('innerText')
creation_date = driver \
.find_element(By.CSS_SELECTOR, '.icon-cake') \
.find_element(By.XPATH, "following-sibling::*[1]") \
.get_attribute('innerText') \
.replace('Created ', '')
members = driver \
.find_element(By.CSS_SELECTOR, '[id^="IdCard--Subscribers"]') \
.find_element(By.XPATH, "preceding-sibling::*[1]") \
.get_attribute('innerText')Dans ce cas, vous ne pouvez pas utiliser l’attribut text car les chaînes de texte sont contenues dans des nœuds imbriqués. Si vous utilisiez .text, vous obtiendrez une chaîne vide. Vous devez donc plutôt appeler la méthode get_attribute() pour lire l’attribut innerText, qui retourne le contenu textuel rendu d’un nœud et de ses descendants.
Si vous regardez l’élément de date de création, vous remarquerez qu’il n’y a pas de moyen facile de le sélectionner. Comme il s’agit du nœud qui suit l’icône de gâteau, sélectionnez d’abord l’icône avec .icon-cake, puis utilisez l’expression XPath following-sibling::*[1] pour sélectionner le nœud frère suivant. Nettoyez le texte collecté de manière à supprimer la chaîne « Created » en appelant la méthode Python replace().
Pour l’élément de compteur de membres abonnés, on retrouve quelque chose de similaire. La principale différence est que, dans ce cas, vous devez accéder au frère précédent.
N’oubliez pas d’ajouter les données extraites au dictionnaire subreddit :
subreddit['name'] = name
subreddit['description'] = description
subreddit['creation_date'] = creation_date
subreddit['members'] = membersAffichez subreddit avec print(subreddit), et vous obtiendrez :
{'name': '/r/Technology', 'description': 'Subreddit dedicated to the news and discussions about the creation and use of technology and its surrounding issues.', 'creation_date': 'Jan 25, 2008', 'members': '14.4m'}Parfait ! Vous venez de faire du web scraping avec Python !
Étape 6 : extrayez les données des posts du subreddit
Comme un subreddit contient un certain nombre de posts, vous allez maintenant avoir besoin d’un tableau pour stocker les données collectées :
posts = []Inspectez un élément de post HTML :

Ici, vous pouvez remarquer que vous pouvez tous les sélectionner avec le Sélecteur CSS [data-testid="post-container"] :
post_html_elements = driver \
.find_elements(By.CSS_SELECTOR, '[data-testid="post-container"]')Faites une itération sur eux. Pour chaque élément, créez un dictionnaire de post pour conserver des données de chaque post :
for post_html_element in post_html_elements:
post = {}
# scraping logic...Inspectez l’élément des votes favorables :
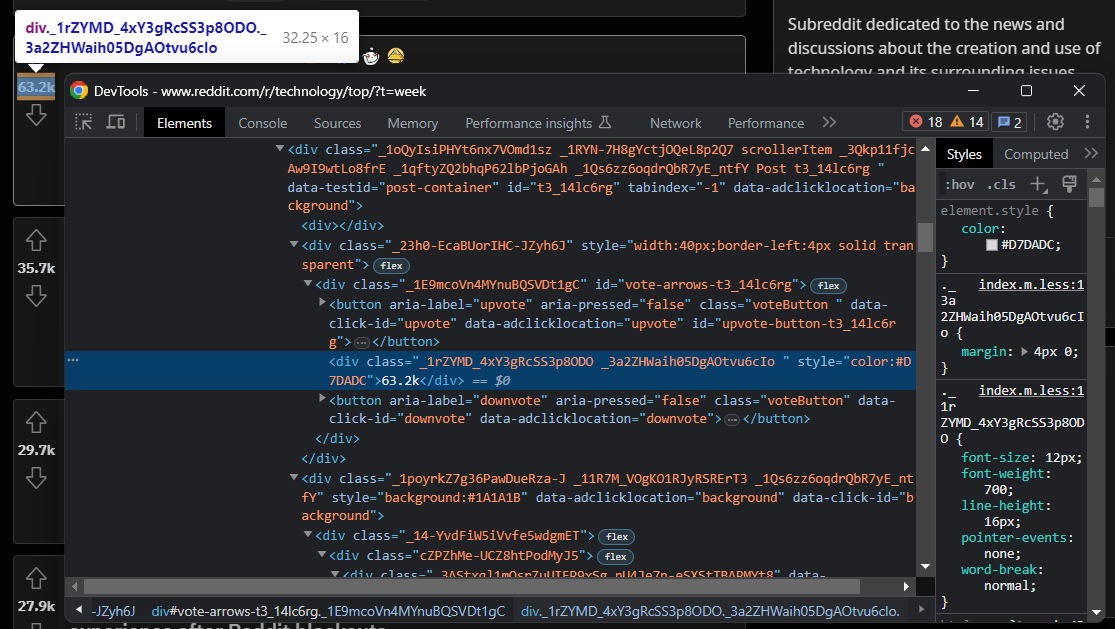
Vous pouvez récupérer ces informations dans la boucle for comme ceci :
upvotes = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-click-id="upvote"]') \
.find_element(By.XPATH, "following-sibling::*[1]") \
.get_attribute('innerText')Encore une fois, il est préférable d’accéder au bouton upvote, qui est facile à sélectionner, puis de pointer sur le nœud frère suivant pour récupérer les informations cibles.
Inspectez les éléments d’auteur et de titre du post :

Obtenir ces données est un peu plus facile :
author = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-testid="post_author_link"]') \
.text
title = post_html_element \
.find_element(By.TAG_NAME, 'h3') \
.textEnsuite, vous pouvez collecter le nombre de commentaires et le lien sortant :

try:
outbound_link = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-testid="outbound-link"]') \
.get_attribute('href')
except NoSuchElementException:
outbound_link = None
comments = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-click-id="comments"]') \
.get_attribute('innerText') \
.replace(' Comments', '')Puisque l’élément de lien sortant est facultatif, vous devez encapsuler la logique de sélection dans un bloc try.
Ajoutez ces données à post et adjoignez-les au tableau posts, mais seulement si title est présent. Cette vérification supplémentaire permet d’éviter de collecter les messages publicitaires spéciaux placés par Reddit :
# populate the dictionary with the retrieved data
post['upvotes'] = upvotes
post['title'] = title
post['outbound_link'] = outbound_link
post['comments'] = comments
# to avoid adding ad posts
# to the list of scraped posts
if title:
posts.append(post)Enfin, ajoutez posts au dictionnaire subreddit :
subreddit['posts'] = postsParfait ! Vous avez maintenant toutes les données Reddit recherchées.
Étape 7 : Exportez les données extraites au format JSON
Les données collectées se trouvent maintenant dans un dictionnaire Python. Ce n’est pas le meilleur format pour partager des données avec d’autres équipes. Pour résoudre ce problème, vous devez les exporter au format JSON :
import json
# ...
with open('subreddit.json', 'w') as file:
json.dump(video, file)Importez json depuis la bibliothèque standard de Python, créez un fichier subreddit.json avec open(), puis remplissez-le avec json.dump(). Consultez notre guide pour découvrir comment analyser des données en Python pour les convertir en JSON.
Parfait ! Vous êtes passé de données brutes contenues dans une page HTML dynamique à des données JSON semi-structurées. Il est maintenant temps de jeter un coup d’œil à l’ensemble de notre web scraper Reddit.
Étape 8 : au final
Voici l’ensemble du script scraper.py :
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import json
# enable the headless mode
options = Options()
options.add_argument('--headless=new')
# initialize a web driver to control Chrome
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# maxime the controlled browser window
driver.fullscreen_window()
# the URL of the target page to scrape
url = 'https://www.reddit.com/r/technology/top/?t=week'
# connect to the target URL in Selenium
driver.get(url)
# initialize the dictionary that will contain
# the subreddit scraped data
subreddit = {}
# subreddit scraping logic
name = driver \
.find_element(By.TAG_NAME, 'h1') \
.text
description = driver \
.find_element(By.CSS_SELECTOR, '[data-testid="no-edit-description-block"]') \
.get_attribute('innerText')
creation_date = driver \
.find_element(By.CSS_SELECTOR, '.icon-cake') \
.find_element(By.XPATH, "following-sibling::*[1]") \
.get_attribute('innerText') \
.replace('Created ', '')
members = driver \
.find_element(By.CSS_SELECTOR, '[id^="IdCard--Subscribers"]') \
.find_element(By.XPATH, "preceding-sibling::*[1]") \
.get_attribute('innerText')
# add the scraped data to the dictionary
subreddit['name'] = name
subreddit['description'] = description
subreddit['creation_date'] = creation_date
subreddit['members'] = members
# to store the post scraped data
posts = []
# retrieve the list of post HTML elements
post_html_elements = driver \
.find_elements(By.CSS_SELECTOR, '[data-testid="post-container"]')
for post_html_element in post_html_elements:
# to store the data scraped from the
# post HTML element
post = {}
# subreddit post scraping logic
upvotes = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-click-id="upvote"]') \
.find_element(By.XPATH, "following-sibling::*[1]") \
.get_attribute('innerText')
author = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-testid="post_author_link"]') \
.text
title = post_html_element \
.find_element(By.TAG_NAME, 'h3') \
.text
try:
outbound_link = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-testid="outbound-link"]') \
.get_attribute('href')
except NoSuchElementException:
outbound_link = None
comments = post_html_element \
.find_element(By.CSS_SELECTOR, '[data-click-id="comments"]') \
.get_attribute('innerText') \
.replace(' Comments', '')
# populate the dictionary with the retrieved data
post['upvotes'] = upvotes
post['title'] = title
post['outbound_link'] = outbound_link
post['comments'] = comments
# to avoid adding ad posts
# to the list of scraped posts
if title:
posts.append(post)
subreddit['posts'] = posts
# close the browser and free up the Selenium resources
driver.quit()
# export the scraped data to a JSON file
with open('subreddit.json', 'w', encoding='utf-8') as file:
json.dump(subreddit, file, indent=4, ensure_ascii=False)Parfait ! Vous pouvez construire un web scraper Reddit en Python en un peu plus de 100 lignes de code.
Lancez le script, et le fichier subreddit.json suivant apparaîtra dans le dossier racine de votre projet :
{
"name": "/r/Technology",
"description": "Subreddit dedicated to the news and discussions about the creation and use of technology and its surrounding issues.",
"creation_date": "Jan 25, 2008",
"members": "14.4m",
"posts": [
{
"upvotes": "63.2k",
"title": "Mojang exits Reddit, says they '\"no longer feel that Reddit is an appropriate place to post official content or refer [its] players to\".",
"outbound_link": "https://www.pcgamer.com/minecrafts-devs-exit-its-7-million-strong-subreddit-after-reddits-ham-fisted-crackdown-on-protest/",
"comments": "2.9k"
},
{
"upvotes": "35.7k",
"title": "JP Morgan accidentally deletes evidence in multi-million record retention screwup",
"outbound_link": "https://www.theregister.com/2023/06/26/jp_morgan_fined_for_deleting/",
"comments": "2.0k"
},
# omitted for brevity ...
{
"upvotes": "3.6k",
"title": "Facebook content moderators in Kenya call the work 'torture.' Their lawsuit may ripple worldwide",
"outbound_link": "https://techxplore.com/news/2023-06-facebook-content-moderators-kenya-torture.html",
"comments": "188"
},
{
"upvotes": "3.6k",
"title": "Reddit is telling protesting mods their communities ‘will not’ stay private",
"outbound_link": "https://www.theverge.com/2023/6/28/23777195/reddit-protesting-moderators-communities-subreddits-private-reopen",
"comments": "713"
}
]
}Félicitations ! Vous venez d’apprendre à extraire des données Reddit en Python.
Conclusion
Faire du web scraping sur Reddit est un meilleur moyen d’obtenir des données que d’utiliser son API, surtout avec les nouvelles politiques. Dans ce tutoriel étape par étape, vous avez appris à construire un web scraper en Python pour récupérer les données d’un subreddit. Comme vous l’avez vu, cela ne nécessite que quelques lignes de code.
Cela étant, de même que Reddit a changé sa politique en matière d’API du jour au lendemain, il pourrait bientôt mettre en œuvre des mesures anti-scraping strictes. En extraire des données deviendrait alors un exploit, mais il y a une solution. Le navigateur Scraping Browser de Bright Data est un outil qui permet d’assurer le rendu de JavaScript ou de Selenium tout en gérant automatiquement pour vous les empreintes de navigateur, les CAPTCHA et les mesures anti-scraping prises par les sites web.
Si ce n’est pas votre tasse de thé, nous avons construit un web scraper Reddit pour répondre à vos besoins. Grâce à cette solution fiable et facile à utiliser, vous pouvez obtenir sans effort toutes les données Reddit que vous voulez.
Aucune carte de crédit requise
Vous ne voulez pas du tout vous occuper des tâches de web scraping sur Reddit, mais vous êtes intéressé par les données de certains subreddits ? Achetez un jeu de données Reddit.



